 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Guided Self-Supervision for Ultra-Fine-Grained Recognition with Limited Data
Apr 21, 2026This paper investigates the intrinsic geometrical features of highly similar objects and introduces a general self-supervised framework called the Geometric Attribute Exploration Network (GAEor), which is designed to address the ultra-fine-grained visual categorization (Ultra-FGVC) task in data-limited scenarios. Unlike prior work that often captures subtle yet critical distinctions, GAEor generates geometric attributes as novel alternative recognition cues. These attributes are determined by various details within the object, aligned with its geometric patterns, such as the intricate vein structures in soybean leaves. Crucially, each category exhibits distinct geometric descriptors that serve as powerful cues, even among objects with minimal visual variation -- a factor largely overlooked in recent research. GAEor discovers these geometric attributes by first amplifying geometry-relevant details via visual feedback from a backbone network, then embedding the relative polar coordinates of these details into the final representation. Extensive experiments demonstrate that GAEor significantly sets new state-of-the-art records in five widely-used Ultra-FGVC benchmarks.
Divide-and-Conquer Approach to Holistic Cognition in High-Similarity Contexts with Limited Data
Apr 21, 2026Ultra-fine-grained visual categorization (Ultra-FGVC) aims to classify highly similar subcategories within fine-grained objects using limited training samples. However, holistic yet discriminative cues, such as leaf contours in extremely similar cultivars, remain under-explored in current studies, thereby limiting recognition performance. Though crucial, modeling holistic cues with complex morphological structures typically requires massive training samples, posing significant challenges in data-limited scenarios. To address this challenge, we propose a novel Divide-and-Conquer Holistic Cognition Network (DHCNet) that implements a divide-and-conquer strategy by decomposing holistic cues into spatially-associated subtle discrepancies and progressively establishing the holistic cognition process, significantly simplifying holistic cognition while reducing dependency on training data. Technically, DHCNet begins by progressively analyzing subtle discrepancies, transitioning from smaller local patches to larger ones using a self-shuffling operation on local regions. Simultaneously, it leverages the unaffected local regions to potentially guide the perception of the original topological structure among the shuffled patches, thereby aiding in the establishment of spatial associations for these discrepancies. Additionally, DHCNet incorporates the online refinement of these holistic cues discovered from local regions into the training process to iteratively improve their quality. As a result, DHCNet uses these holistic cues as supervisory signals to fine-tune the parameters of the recognition model, thus improving its sensitivity to holistic cues across the entire objects. Extensive evaluations demonstrate that DHCNet achieves remarkable performance on five widely-used Ultra-FGVC datasets.
Breaking Alignment Barriers: TPS-Driven Semantic Correlation Learning for Alignment-Free RGB-T Salient Object Detection
Dec 26, 2025Existing RGB-T salient object detection methods predominantly rely on manually aligned and annotated datasets, struggling to handle real-world scenarios with raw, unaligned RGB-T image pairs. In practical applications, due to significant cross-modal disparities such as spatial misalignment, scale variations, and viewpoint shifts, the performance of current methods drastically deteriorates on unaligned datasets. To address this issue, we propose an efficient RGB-T SOD method for real-world unaligned image pairs, termed Thin-Plate Spline-driven Semantic Correlation Learning Network (TPS-SCL). We employ a dual-stream MobileViT as the encoder, combined with efficient Mamba scanning mechanisms, to effectively model correlations between the two modalities while maintaining low parameter counts and computational overhead. To suppress interference from redundant background information during alignment, we design a Semantic Correlation Constraint Module (SCCM) to hierarchically constrain salient features. Furthermore, we introduce a Thin-Plate Spline Alignment Module (TPSAM) to mitigate spatial discrepancies between modalities. Additionally, a Cross-Modal Correlation Module (CMCM) is incorporated to fully explore and integrate inter-modal dependencies, enhancing detection performance. Extensive experiments on various datasets demonstrate that TPS-SCL attains state-of-the-art (SOTA) performance among existing lightweight SOD methods and outperforms mainstream RGB-T SOD approaches.
Propagating Sparse Depth via Depth Foundation Model for Out-of-Distribution Depth Completion
Aug 07, 2025



Depth completion is a pivotal challenge in computer vision, aiming at reconstructing the dense depth map from a sparse one, typically with a paired RGB image. Existing learning based models rely on carefully prepared but limited data, leading to significant performance degradation in out-of-distribution (OOD) scenarios. Recent foundation models have demonstrated exceptional robustness in monocular depth estimation through large-scale training, and using such models to enhance the robustness of depth completion models is a promising solution. In this work, we propose a novel depth completion framework that leverages depth foundation models to attain remarkable robustness without large-scale training. Specifically, we leverage a depth foundation model to extract environmental cues, including structural and semantic context, from RGB images to guide the propagation of sparse depth information into missing regions. We further design a dual-space propagation approach, without any learnable parameters, to effectively propagates sparse depth in both 3D and 2D spaces to maintain geometric structure and local consistency. To refine the intricate structure, we introduce a learnable correction module to progressively adjust the depth prediction towards the real depth. We train our model on the NYUv2 and KITTI datasets as in-distribution datasets and extensively evaluate the framework on 16 other datasets. Our framework performs remarkably well in the OOD scenarios and outperforms existing state-of-the-art depth completion methods. Our models are released in https://github.com/shenglunch/PSD.
Seg-Wild: Interactive Segmentation based on 3D Gaussian Splatting for Unconstrained Image Collections
Jul 10, 2025



Reconstructing and segmenting scenes from unconstrained photo collections obtained from the Internet is a novel but challenging task. Unconstrained photo collections are easier to get than well-captured photo collections. These unconstrained images suffer from inconsistent lighting and transient occlusions, which makes segmentation challenging. Previous segmentation methods cannot address transient occlusions or accurately restore the scene's lighting conditions. Therefore, we propose Seg-Wild, an interactive segmentation method based on 3D Gaussian Splatting for unconstrained image collections, suitable for in-the-wild scenes. We integrate multi-dimensional feature embeddings for each 3D Gaussian and calculate the feature similarity between the feature embeddings and the segmentation target to achieve interactive segmentation in the 3D scene. Additionally, we introduce the Spiky 3D Gaussian Cutter (SGC) to smooth abnormal 3D Gaussians. We project the 3D Gaussians onto a 2D plane and calculate the ratio of 3D Gaussians that need to be cut using the SAM mask. We also designed a benchmark to evaluate segmentation quality in in-the-wild scenes. Experimental results demonstrate that compared to previous methods, Seg-Wild achieves better segmentation results and reconstruction quality. Our code will be available at https://github.com/Sugar0725/Seg-Wild.
Geometry-Editable and Appearance-Preserving Object Compositon
May 27, 2025General object composition (GOC) aims to seamlessly integrate a target object into a background scene with desired geometric properties, while simultaneously preserving its fine-grained appearance details. Recent approaches derive semantic embeddings and integrate them into advanced diffusion models to enable geometry-editable generation. However, these highly compact embeddings encode only high-level semantic cues and inevitably discard fine-grained appearance details. We introduce a Disentangled Geometry-editable and Appearance-preserving Diffusion (DGAD) model that first leverages semantic embeddings to implicitly capture the desired geometric transformations and then employs a cross-attention retrieval mechanism to align fine-grained appearance features with the geometry-edited representation, facilitating both precise geometry editing and faithful appearance preservation in object composition. Specifically, DGAD builds on CLIP/DINO-derived and reference networks to extract semantic embeddings and appearance-preserving representations, which are then seamlessly integrated into the encoding and decoding pipelines in a disentangled manner. We first integrate the semantic embeddings into pre-trained diffusion models that exhibit strong spatial reasoning capabilities to implicitly capture object geometry, thereby facilitating flexible object manipulation and ensuring effective editability. Then, we design a dense cross-attention mechanism that leverages the implicitly learned object geometry to retrieve and spatially align appearance features with their corresponding regions, ensuring faithful appearance consistency. Extensive experiments on public benchmarks demonstrate the effectiveness of the proposed DGAD framework.
Monocular and Generalizable Gaussian Talking Head Animation
Apr 01, 2025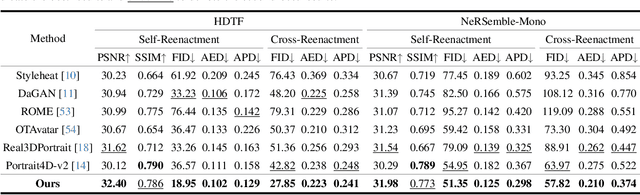
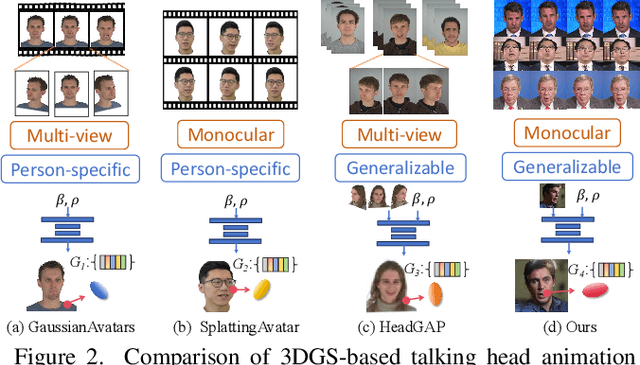
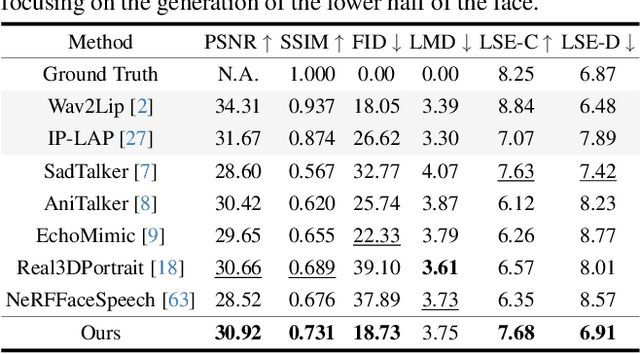
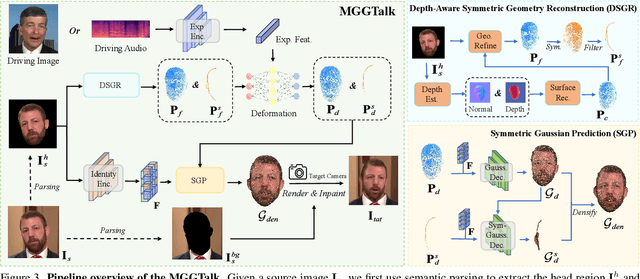
In this work, we introduce Monocular and Generalizable Gaussian Talking Head Animation (MGGTalk), which requires monocular datasets and generalizes to unseen identities without personalized re-training. Compared with previous 3D Gaussian Splatting (3DGS) methods that requires elusive multi-view datasets or tedious personalized learning/inference, MGGtalk enables more practical and broader applications. However, in the absence of multi-view and personalized training data, the incompleteness of geometric and appearance information poses a significant challenge. To address these challenges, MGGTalk explores depth information to enhance geometric and facial symmetry characteristics to supplement both geometric and appearance features. Initially, based on the pixel-wise geometric information obtained from depth estimation, we incorporate symmetry operations and point cloud filtering techniques to ensure a complete and precise position parameter for 3DGS. Subsequently, we adopt a two-stage strategy with symmetric priors for predicting the remaining 3DGS parameters. We begin by predicting Gaussian parameters for the visible facial regions of the source image. These parameters are subsequently utilized to improve the prediction of Gaussian parameters for the non-visible regions. Extensive experiments demonstrate that MGGTalk surpasses previous state-of-the-art methods, achieving superior performance across various metrics.
Is this Generated Person Existed in Real-world? Fine-grained Detecting and Calibrating Abnormal Human-body
Nov 21, 2024



Recent improvements in visual synthesis have significantly enhanced the depiction of generated human photos, which are pivotal due to their wide applicability and demand. Nonetheless, the existing text-to-image or text-to-video models often generate low-quality human photos that might differ considerably from real-world body structures, referred to as "abnormal human bodies". Such abnormalities, typically deemed unacceptable, pose considerable challenges in the detection and repair of them within human photos. These challenges require precise abnormality recognition capabilities, which entail pinpointing both the location and the abnormality type. Intuitively, Visual Language Models (VLMs) that have obtained remarkable performance on various visual tasks are quite suitable for this task. However, their performance on abnormality detection in human photos is quite poor. Hence, it is quite important to highlight this task for the research community. In this paper, we first introduce a simple yet challenging task, i.e., \textbf{F}ine-grained \textbf{H}uman-body \textbf{A}bnormality \textbf{D}etection \textbf{(FHAD)}, and construct two high-quality datasets for evaluation. Then, we propose a meticulous framework, named HumanCalibrator, which identifies and repairs abnormalities in human body structures while preserving the other content. Experiments indicate that our HumanCalibrator achieves high accuracy in abnormality detection and accomplishes an increase in visual comparisons while preserving the other visual content.
KMTalk: Speech-Driven 3D Facial Animation with Key Motion Embedding
Sep 02, 2024We present a novel approach for synthesizing 3D facial motions from audio sequences using key motion embeddings. Despite recent advancements in data-driven techniques, accurately mapping between audio signals and 3D facial meshes remains challenging. Direct regression of the entire sequence often leads to over-smoothed results due to the ill-posed nature of the problem. To this end, we propose a progressive learning mechanism that generates 3D facial animations by introducing key motion capture to decrease cross-modal mapping uncertainty and learning complexity. Concretely, our method integrates linguistic and data-driven priors through two modules: the linguistic-based key motion acquisition and the cross-modal motion completion. The former identifies key motions and learns the associated 3D facial expressions, ensuring accurate lip-speech synchronization. The latter extends key motions into a full sequence of 3D talking faces guided by audio features, improving temporal coherence and audio-visual consistency. Extensive experimental comparisons against existing state-of-the-art methods demonstrate the superiority of our approach in generating more vivid and consistent talking face animations. Consistent enhancements in results through the integration of our proposed learning scheme with existing methods underscore the efficacy of our approach. Our code and weights will be at the project website: \url{https://github.com/ffxzh/KMTalk}.
Behavior Pattern Mining-based Multi-Behavior Recommendation
Aug 22, 2024



Multi-behavior recommendation systems enhance effectiveness by leveraging auxiliary behaviors (such as page views and favorites) to address the limitations of traditional models that depend solely on sparse target behaviors like purchases. Existing approaches to multi-behavior recommendations typically follow one of two strategies: some derive initial node representations from individual behavior subgraphs before integrating them for a comprehensive profile, while others interpret multi-behavior data as a heterogeneous graph, applying graph neural networks to achieve a unified node representation. However, these methods do not adequately explore the intricate patterns of behavior among users and items. To bridge this gap, we introduce a novel algorithm called Behavior Pattern mining-based Multi-behavior Recommendation (BPMR). Our method extensively investigates the diverse interaction patterns between users and items, utilizing these patterns as features for making recommendations. We employ a Bayesian approach to streamline the recommendation process, effectively circumventing the challenges posed by graph neural network algorithms, such as the inability to accurately capture user preferences due to over-smoothing. Our experimental evaluation on three real-world datasets demonstrates that BPMR significantly outperforms existing state-of-the-art algorithms, showing an average improvement of 268.29% in Recall@10 and 248.02% in NDCG@10 metrics. The code of our BPMR is openly accessible for use and further research at https://github.com/rookitkitlee/BPMR.