 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuFIA: Language-Guided Augmented Dexterity for Robotic Surgical Assistants
May 08, 2024



In this work, we present SuFIA, the first framework for natural language-guided augmented dexterity for robotic surgical assistants. SuFIA incorporates the strong reasoning capabilities of large language models (LLMs) with perception modules to implement high-level planning and low-level control of a robot for surgical sub-task execution. This enables a learning-free approach to surgical augmented dexterity without any in-context examples or motion primitives. SuFIA uses a human-in-the-loop paradigm by restoring control to the surgeon in the case of insufficient information, mitigating unexpected errors for mission-critical tasks. We evaluate SuFIA on four surgical sub-tasks in a simulation environment and two sub-tasks on a physical surgical robotic platform in the lab, demonstrating its ability to perform common surgical sub-tasks through supervised autonomous operation under challenging physical and workspace conditions. Project website: orbit-surgical.github.io/sufia
ORBIT-Surgical: An Open-Simulation Framework for Learning Surgical Augmented Dexterity
Apr 24, 2024



Physics-based simulations have accelerated progress in robot learning for driving, manipulation, and locomotion. Yet, a fast, accurate, and robust surgical simulation environment remains a challenge. In this paper, we present ORBIT-Surgical, a physics-based surgical robot simulation framework with photorealistic rendering in NVIDIA Omniverse. We provide 14 benchmark surgical tasks for the da Vinci Research Kit (dVRK) and Smart Tissue Autonomous Robot (STAR) which represent common subtasks in surgical training. ORBIT-Surgical leverages GPU parallelization to train reinforcement learning and imitation learning algorithms to facilitate study of robot learning to augment human surgical skills. ORBIT-Surgical also facilitates realistic synthetic data generation for active perception tasks. We demonstrate ORBIT-Surgical sim-to-real transfer of learned policies onto a physical dVRK robot. Project website: orbit-surgical.github.io
AdaDemo: Data-Efficient Demonstration Expansion for Generalist Robotic Agent
Apr 11, 2024



Encouraged by the remarkable achievements of language and vision foundation models, developing generalist robotic agents through imitation learning, using large demonstration datasets, has become a prominent area of interest in robot learning. The efficacy of imitation learning is heavily reliant on the quantity and quality of the demonstration datasets. In this study, we aim to scale up demonstrations in a data-efficient way to facilitate the learning of generalist robotic agents. We introduce AdaDemo (Adaptive Online Demonstration Expansion), a general framework designed to improve multi-task policy learning by actively and continually expanding the demonstration dataset. AdaDemo strategically collects new demonstrations to address the identified weakness in the existing policy, ensuring data efficiency is maximized. Through a comprehensive evaluation on a total of 22 tasks across two robotic manipulation benchmarks (RLBench and Adroit), we demonstrate AdaDemo's capability to progressively improve policy performance by guiding the generation of high-quality demonstration datasets in a data-efficient manner.
Multi-Constraint Safe RL with Objective Suppression for Safety-Critical Applications
Feb 23, 2024

Safe reinforcement learning tasks with multiple constraints are a challenging domain despite being very common in the real world. To address this challenge, we propose Objective Suppression, a novel method that adaptively suppresses the task reward maximizing objectives according to a safety critic. We benchmark Objective Suppression in two multi-constraint safety domains, including an autonomous driving domain where any incorrect behavior can lead to disastrous consequences. Empirically, we demonstrate that our proposed method, when combined with existing safe RL algorithms, can match the task reward achieved by our baselines with significantly fewer constraint violations.
Fast Explicit-Input Assistance for Teleoperation in Clutter
Feb 04, 2024



The performance of prediction-based assistance for robot teleoperation degrades in unseen or goal-rich environments due to incorrect or quickly-changing intent inferences. Poor predictions can confuse operators or cause them to change their control input to implicitly signal their goal, resulting in unnatural movement. We present a new assistance algorithm and interface for robotic manipulation where an operator can explicitly communicate a manipulation goal by pointing the end-effector. Rapid optimization and parallel collision checking in a local region around the pointing target enable direct, interactive control over grasp and place pose candidates. We compare the explicit pointing interface to an implicit inference-based assistance scheme in a within-subjects user study (N=20) where participants teleoperate a simulated robot to complete a multi-step singulation and stacking task in cluttered environments. We find that operators prefer the explicit interface, which improved completion time, pick and place success rates, and NASA TLX scores. Our code is available at https://github.com/NVlabs/fast-explicit-teleop
ORGANA: A Robotic Assistant for Automated Chemistry Experimentation and Characterization
Jan 13, 2024



Chemistry experimentation is often resource- and labor-intensive. Despite the many benefits incurred by the integration of advanced and special-purpose lab equipment, many aspects of experimentation are still manually conducted by chemists, for example, polishing an electrode in electrochemistry experiments. Traditional lab automation infrastructure faces challenges when it comes to flexibly adapting to new chemistry experiments. To address this issue, we propose a human-friendly and flexible robotic system, ORGANA, that automates a diverse set of chemistry experiments. It is capable of interacting with chemists in the lab through natural language, using Large Language Models (LLMs). ORGANA keeps scientists informed by providing timely reports that incorporate statistical analyses. Additionally, it actively engages with users when necessary for disambiguation or troubleshooting. ORGANA can reason over user input to derive experiment goals, and plan long sequences of both high-level tasks and low-level robot actions while using feedback from the visual perception of the environment. It also supports scheduling and parallel execution for experiments that require resource allocation and coordination between multiple robots and experiment stations. We show that ORGANA successfully conducts a diverse set of chemistry experiments, including solubility assessment, pH measurement, recrystallization, and electrochemistry experiments. For the latter, we show that ORGANA robustly executes a long-horizon plan, comprising 19 steps executed in parallel, to characterize the electrochemical properties of quinone derivatives, a class of molecules used in rechargeable flow batteries. Our user study indicates that ORGANA significantly improves many aspects of user experience while reducing their physical workload. More details about ORGANA can be found at https://ac-rad.github.io/organa/.
RePLan: Robotic Replanning with Perception and Language Models
Jan 08, 2024



Advancements in large language models (LLMs) have demonstrated their potential in facilitating high-level reasoning, logical reasoning and robotics planning. Recently, LLMs have also been able to generate reward functions for low-level robot actions, effectively bridging the interface between high-level planning and low-level robot control. However, the challenge remains that even with syntactically correct plans, robots can still fail to achieve their intended goals. This failure can be attributed to imperfect plans proposed by LLMs or to unforeseeable environmental circumstances that hinder the execution of planned subtasks due to erroneous assumptions about the state of objects. One way to prevent these challenges is to rely on human-provided step-by-step instructions, limiting the autonomy of robotic systems. Vision Language Models (VLMs) have shown remarkable success in tasks such as visual question answering and image captioning. Leveraging the capabilities of VLMs, we present a novel framework called Robotic Replanning with Perception and Language Models (RePLan) that enables real-time replanning capabilities for long-horizon tasks. This framework utilizes the physical grounding provided by a VLM's understanding of the world's state to adapt robot actions when the initial plan fails to achieve the desired goal. We test our approach within four environments containing seven long-horizion tasks. We find that RePLan enables a robot to successfully adapt to unforeseen obstacles while accomplishing open-ended, long-horizon goals, where baseline models cannot. Find more information at https://replan-lm.github.io/replan.github.io/
Benchmarks for Physical Reasoning AI
Dec 17, 2023



Physical reasoning is a crucial aspect in the development of general AI systems, given that human learning starts with interacting with the physical world before progressing to more complex concepts. Although researchers have studied and assessed the physical reasoning of AI approaches through various specific benchmarks, there is no comprehensive approach to evaluating and measuring progress. Therefore, we aim to offer an overview of existing benchmarks and their solution approaches and propose a unified perspective for measuring the physical reasoning capacity of AI systems. We select benchmarks that are designed to test algorithmic performance in physical reasoning tasks. While each of the selected benchmarks poses a unique challenge, their ensemble provides a comprehensive proving ground for an AI generalist agent with a measurable skill level for various physical reasoning concepts. This gives an advantage to such an ensemble of benchmarks over other holistic benchmarks that aim to simulate the real world by intertwining its complexity and many concepts. We group the presented set of physical reasoning benchmarks into subcategories so that more narrow generalist AI agents can be tested first on these groups.
Geometry Matching for Multi-Embodiment Grasping
Dec 06, 2023



Many existing learning-based grasping approaches concentrate on a single embodiment, provide limited generalization to higher DoF end-effectors and cannot capture a diverse set of grasp modes. We tackle the problem of grasping using multiple embodiments by learning rich geometric representations for both objects and end-effectors using Graph Neural Networks. Our novel method - GeoMatch - applies supervised learning on grasping data from multiple embodiments, learning end-to-end contact point likelihood maps as well as conditional autoregressive predictions of grasps keypoint-by-keypoint. We compare our method against baselines that support multiple embodiments. Our approach performs better across three end-effectors, while also producing diverse grasps. Examples, including real robot demos, can be found at geo-match.github.io.
HandyPriors: Physically Consistent Perception of Hand-Object Interactions with Differentiable Priors
Dec 03, 2023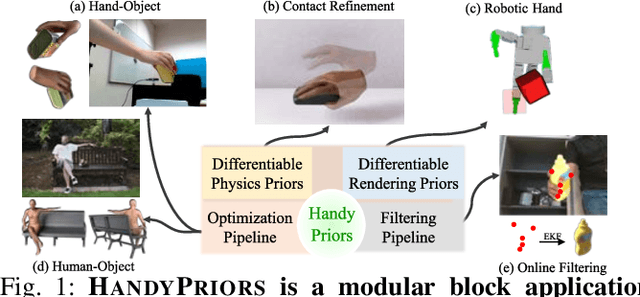
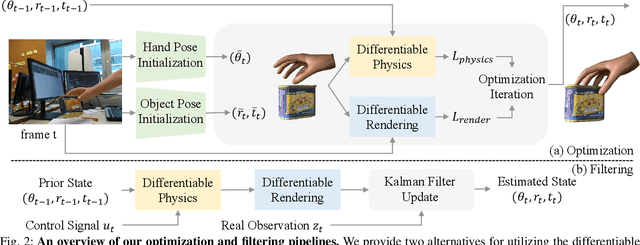
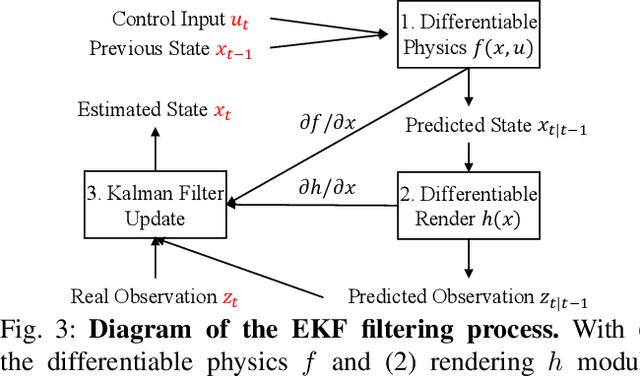

Various heuristic objectives for modeling hand-object interaction have been proposed in past work. However, due to the lack of a cohesive framework, these objectives often possess a narrow scope of applicability and are limited by their efficiency or accuracy. In this paper, we propose HandyPriors, a unified and general pipeline for pose estimation in human-object interaction scenes by leveraging recent advances in differentiable physics and rendering. Our approach employs rendering priors to align with input images and segmentation masks along with physics priors to mitigate penetration and relative-sliding across frames. Furthermore, we present two alternatives for hand and object pose estimation. The optimization-based pose estimation achieves higher accuracy, while the filtering-based tracking, which utilizes the differentiable priors as dynamics and observation models, executes faster. We demonstrate that HandyPriors attains comparable or superior results in the pose estimation task, and that the differentiable physics module can predict contact information for pose refinement. We also show that our approach generalizes to perception tasks, including robotic hand manipulation and human-object pose estimation in the wild.