 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereoPolicy: Improving Robotic Manipulation Policies via Stereo Perception
May 11, 2026Recent advances in robot imitation learning have yielded powerful visuomotor policies capable of manipulating a wide variety of objects directly from monocular visual inputs. However, monocular observations inherently lack reliable depth cues and spatial awareness, which are critical for precise manipulation in cluttered or geometrically complex scenes. To address this limitation, we introduce StereoPolicy, a new visuomotor policy learning framework that directly leverages synchronized stereo image pairs to strengthen geometric reasoning, without requiring explicit 3D reconstruction or camera calibration. StereoPolicy employs pretrained 2D vision encoders to process each image independently and fuses the resulting representations through a Stereo Transformer. This design implicitly captures spatial correspondence and disparity cues. The framework integrates seamlessly with diffusion-based and pretrained vision-language-action (VLA) policies, delivering consistent improvements over RGB, RGB-D, point cloud, and multi-view baselines across three simulation benchmarks: RoboMimic, RoboCasa, and OmniGibson. We further validate StereoPolicy on real-robot experiments spanning both tabletop and bimanual mobile manipulation settings. Our results underscore stereo vision as a scalable and robust modality that bridges 2D pretrained representations with 3D geometric understanding for robotic manipulation.
CaP-X: A Framework for Benchmarking and Improving Coding Agents for Robot Manipulation
Mar 23, 2026"Code-as-Policy" considers how executable code can complement data-intensive Vision-Language-Action (VLA) methods, yet their effectiveness as autonomous controllers for embodied manipulation remains underexplored. We present CaP-X, an open-access framework for systematically studying Code-as-Policy agents in robot manipulation. At its core is CaP-Gym, an interactive environment in which agents control robots by synthesizing and executing programs that compose perception and control primitives. Building on this foundation, CaP-Bench evaluates frontier language and vision-language models across varying levels of abstraction, interaction, and perceptual grounding. Across 12 models, CaP-Bench reveals a consistent trend: performance improves with human-crafted abstractions but degrades as these priors are removed, exposing a dependence on designer scaffolding. At the same time, we observe that this gap can be mitigated through scaling agentic test-time computation--through multi-turn interaction, structured execution feedback, visual differencing, automatic skill synthesis, and ensembled reasoning--substantially improves robustness even when agents operate over low-level primitives. These findings allow us to derive CaP-Agent0, a training-free framework that recovers human-level reliability on several manipulation tasks in simulation and on real embodiments. We further introduce CaP-RL, showing reinforcement learning with verifiable rewards improves success rates and transfers from sim2real with minimal gap. Together, CaP-X provides a principled, open-access platform for advancing embodied coding agents.
Learning from Trials and Errors: Reflective Test-Time Planning for Embodied LLMs
Feb 24, 2026Embodied LLMs endow robots with high-level task reasoning, but they cannot reflect on what went wrong or why, turning deployment into a sequence of independent trials where mistakes repeat rather than accumulate into experience. Drawing upon human reflective practitioners, we introduce Reflective Test-Time Planning, which integrates two modes of reflection: \textit{reflection-in-action}, where the agent uses test-time scaling to generate and score multiple candidate actions using internal reflections before execution; and \textit{reflection-on-action}, which uses test-time training to update both its internal reflection model and its action policy based on external reflections after execution. We also include retrospective reflection, allowing the agent to re-evaluate earlier decisions and perform model updates with hindsight for proper long-horizon credit assignment. Experiments on our newly-designed Long-Horizon Household benchmark and MuJoCo Cupboard Fitting benchmark show significant gains over baseline models, with ablative studies validating the complementary roles of reflection-in-action and reflection-on-action. Qualitative analyses, including real-robot trials, highlight behavioral correction through reflection.
Robo-DM: Data Management For Large Robot Datasets
May 21, 2025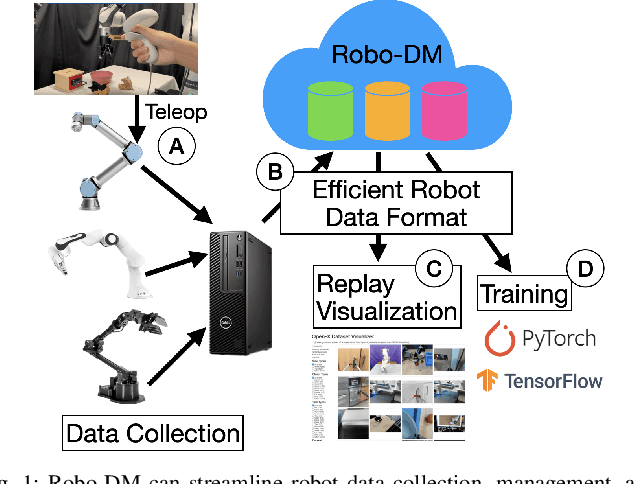
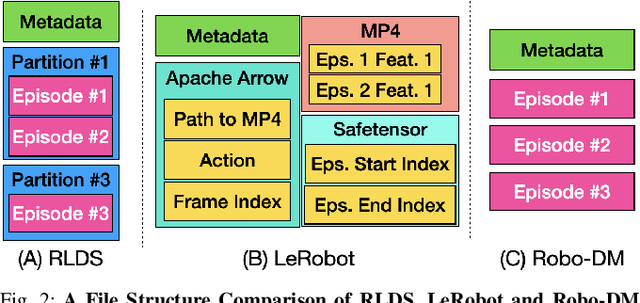
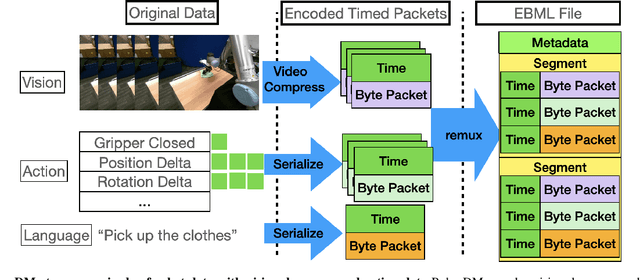
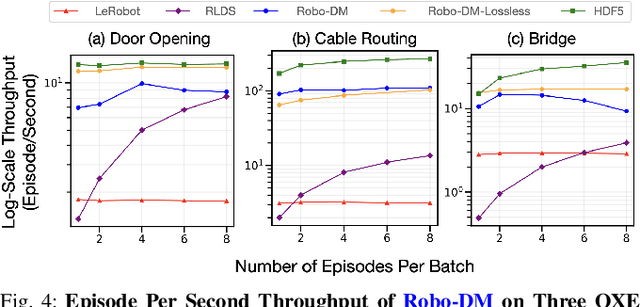
Recent results suggest that very large datasets of teleoperated robot demonstrations can be used to train transformer-based models that have the potential to generalize to new scenes, robots, and tasks. However, curating, distributing, and loading large datasets of robot trajectories, which typically consist of video, textual, and numerical modalities - including streams from multiple cameras - remains challenging. We propose Robo-DM, an efficient open-source cloud-based data management toolkit for collecting, sharing, and learning with robot data. With Robo-DM, robot datasets are stored in a self-contained format with Extensible Binary Meta Language (EBML). Robo-DM can significantly reduce the size of robot trajectory data, transfer costs, and data load time during training. Compared to the RLDS format used in OXE datasets, Robo-DM's compression saves space by up to 70x (lossy) and 3.5x (lossless). Robo-DM also accelerates data retrieval by load-balancing video decoding with memory-mapped decoding caches. Compared to LeRobot, a framework that also uses lossy video compression, Robo-DM is up to 50x faster when decoding sequentially. We physically evaluate a model trained by Robo-DM with lossy compression, a pick-and-place task, and In-Context Robot Transformer. Robo-DM uses 75x compression of the original dataset and does not suffer reduction in downstream task accuracy.
Real2Render2Real: Scaling Robot Data Without Dynamics Simulation or Robot Hardware
May 14, 2025



Scaling robot learning requires vast and diverse datasets. Yet the prevailing data collection paradigm-human teleoperation-remains costly and constrained by manual effort and physical robot access. We introduce Real2Render2Real (R2R2R), a novel approach for generating robot training data without relying on object dynamics simulation or teleoperation of robot hardware. The input is a smartphone-captured scan of one or more objects and a single video of a human demonstration. R2R2R renders thousands of high visual fidelity robot-agnostic demonstrations by reconstructing detailed 3D object geometry and appearance, and tracking 6-DoF object motion. R2R2R uses 3D Gaussian Splatting (3DGS) to enable flexible asset generation and trajectory synthesis for both rigid and articulated objects, converting these representations to meshes to maintain compatibility with scalable rendering engines like IsaacLab but with collision modeling off. Robot demonstration data generated by R2R2R integrates directly with models that operate on robot proprioceptive states and image observations, such as vision-language-action models (VLA) and imitation learning policies. Physical experiments suggest that models trained on R2R2R data from a single human demonstration can match the performance of models trained on 150 human teleoperation demonstrations. Project page: https://real2render2real.com
Predict-Optimize-Distill: A Self-Improving Cycle for 4D Object Understanding
Apr 24, 2025Humans can resort to long-form inspection to build intuition on predicting the 3D configurations of unseen objects. The more we observe the object motion, the better we get at predicting its 3D state immediately. Existing systems either optimize underlying representations from multi-view observations or train a feed-forward predictor from supervised datasets. We introduce Predict-Optimize-Distill (POD), a self-improving framework that interleaves prediction and optimization in a mutually reinforcing cycle to achieve better 4D object understanding with increasing observation time. Given a multi-view object scan and a long-form monocular video of human-object interaction, POD iteratively trains a neural network to predict local part poses from RGB frames, uses this predictor to initialize a global optimization which refines output poses through inverse rendering, then finally distills the results of optimization back into the model by generating synthetic self-labeled training data from novel viewpoints. Each iteration improves both the predictive model and the optimized motion trajectory, creating a virtuous cycle that bootstraps its own training data to learn about the pose configurations of an object. We also introduce a quasi-multiview mining strategy for reducing depth ambiguity by leveraging long video. We evaluate POD on 14 real-world and 5 synthetic objects with various joint types, including revolute and prismatic joints as well as multi-body configurations where parts detach or reattach independently. POD demonstrates significant improvement over a pure optimization baseline which gets stuck in local minima, particularly for longer videos. We also find that POD's performance improves with both video length and successive iterations of the self-improving cycle, highlighting its ability to scale performance with additional observations and looped refinement.
OTTER: A Vision-Language-Action Model with Text-Aware Visual Feature Extraction
Mar 05, 2025



Vision-Language-Action (VLA) models aim to predict robotic actions based on visual observations and language instructions. Existing approaches require fine-tuning pre-trained visionlanguage models (VLMs) as visual and language features are independently fed into downstream policies, degrading the pre-trained semantic alignments. We propose OTTER, a novel VLA architecture that leverages these existing alignments through explicit, text-aware visual feature extraction. Instead of processing all visual features, OTTER selectively extracts and passes only task-relevant visual features that are semantically aligned with the language instruction to the policy transformer. This allows OTTER to keep the pre-trained vision-language encoders frozen. Thereby, OTTER preserves and utilizes the rich semantic understanding learned from large-scale pre-training, enabling strong zero-shot generalization capabilities. In simulation and real-world experiments, OTTER significantly outperforms existing VLA models, demonstrating strong zeroshot generalization to novel objects and environments. Video, code, checkpoints, and dataset: https://ottervla.github.io/.
Second Language (Arabic) Acquisition of LLMs via Progressive Vocabulary Expansion
Dec 16, 2024



This paper addresses the critical need for democratizing large language models (LLM) in the Arab world, a region that has seen slower progress in developing models comparable to state-of-the-art offerings like GPT-4 or ChatGPT 3.5, due to a predominant focus on mainstream languages (e.g., English and Chinese). One practical objective for an Arabic LLM is to utilize an Arabic-specific vocabulary for the tokenizer that could speed up decoding. However, using a different vocabulary often leads to a degradation of learned knowledge since many words are initially out-of-vocabulary (OOV) when training starts. Inspired by the vocabulary learning during Second Language (Arabic) Acquisition for humans, the released AraLLaMA employs progressive vocabulary expansion, which is implemented by a modified BPE algorithm that progressively extends the Arabic subwords in its dynamic vocabulary during training, thereby balancing the OOV ratio at every stage. The ablation study demonstrated the effectiveness of Progressive Vocabulary Expansion. Moreover, AraLLaMA achieves decent performance comparable to the best Arabic LLMs across a variety of Arabic benchmarks. Models, training data, benchmarks, and codes will be all open-sourced.
Alignment at Pre-training! Towards Native Alignment for Arabic LLMs
Dec 04, 2024



The alignment of large language models (LLMs) is critical for developing effective and safe language models. Traditional approaches focus on aligning models during the instruction tuning or reinforcement learning stages, referred to in this paper as `post alignment'. We argue that alignment during the pre-training phase, which we term `native alignment', warrants investigation. Native alignment aims to prevent unaligned content from the beginning, rather than relying on post-hoc processing. This approach leverages extensively aligned pre-training data to enhance the effectiveness and usability of pre-trained models. Our study specifically explores the application of native alignment in the context of Arabic LLMs. We conduct comprehensive experiments and ablation studies to evaluate the impact of native alignment on model performance and alignment stability. Additionally, we release open-source Arabic LLMs that demonstrate state-of-the-art performance on various benchmarks, providing significant benefits to the Arabic LLM community.
DiffusionSeeder: Seeding Motion Optimization with Diffusion for Rapid Motion Planning
Oct 22, 2024Running optimization across many parallel seeds leveraging GPU compute have relaxed the need for a good initialization, but this can fail if the problem is highly non-convex as all seeds could get stuck in local minima. One such setting is collision-free motion optimization for robot manipulation, where optimization converges quickly on easy problems but struggle in obstacle dense environments (e.g., a cluttered cabinet or table). In these situations, graph-based planning algorithms are used to obtain seeds, resulting in significant slowdowns. We propose DiffusionSeeder, a diffusion based approach that generates trajectories to seed motion optimization for rapid robot motion planning. DiffusionSeeder takes the initial depth image observation of the scene and generates high quality, multi-modal trajectories that are then fine-tuned with a few iterations of motion optimization. We integrate DiffusionSeeder to generate the seed trajectories for cuRobo, a GPU-accelerated motion optimization method, which results in 12x speed up on average, and 36x speed up for more complicated problems, while achieving 10% higher success rate in partially observed simulation environments. Our results show the effectiveness of using diverse solutions from a learned diffusion model. Physical experiments on a Franka robot demonstrate the sim2real transfer of DiffusionSeeder to the real robot, with an average success rate of 86% and planning time of 26ms, improving on cuRobo by 51% higher success rate while also being 2.5x faster.