 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Volumetric Mechanical Property Fields Invariant to Resolution
Jun 16, 2026Accurate mechanical properties (or materials) Young's modulus ($E$), Poisson's ratio ($ν$) and density ($ρ$) are essential for reliable physics simulation of digital worlds, but most 3D assets lack this information. We propose AdaVoMP, a method for predicting accurate dense spatially-varying ($E$, $ν$, $ρ$) for input 3D objects across representations, improving the resolution, accuracy, and memory efficiency over the state-of-the-art. The foundation of our technique is a sparse and adaptive voxel structure SAV that efficiently represents both the input 3D shape and the material field output. We replace the fixed-voxel model of the most accurate prior method, VoMP, with a novel sparse transformer encoder-decoder model that learns to generate a unique SAV autoregressively for every input shape to represent its materials, achieving a resolution $16^3\times$ higher than prior art. Experiments show that AdaVoMP estimates more accurate volumetric properties, even with lesser test-time compute than all prior art. This allows us to convert high-resolution complex 3D objects into simulation-ready assets, resulting in realistic deformable simulations.
VoLo: A Physical Orchestrator for Open-Vocabulary Long-Horizon Manipulation
Jun 05, 2026Open-vocabulary long-horizon manipulation requires robots to reason over flexible instructions and complex multi-object scenes while adaptively planning, executing, monitoring, and recovering from failures. We address these demands with a closed agent loop in which a VLM orchestrates heterogeneous robot capabilities as interruptible tools. Unlike in virtual AI agents, the timing of decisions, actions and tool calls is important in a physical world that does not pause for reasoning. We refer to this setting as Physical Orchestration, and propose VoLoAgent, a VLM that plans, monitors, and recovers by treating a VLA/WAM as an interruptible tool it steers mid-rollout alongside vision models and action primitives. To evaluate these long-horizon capabilities, we introduce RoboVoLo, a high-fidelity benchmark for open-vocabulary long-horizon manipulation across common sense, memory/state tracking, complex references, and world knowledge, with both task-level success and failure-mode diagnostics. Experiments show VoLoAgent substantially outperforms single VLA/VLM or tool-based systems, with validation on real-robot experiments. Project page: https://chicychen.github.io/VoLo/
Cosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
RoboLab: A High-Fidelity Simulation Benchmark for Analysis of Task Generalist Policies
Apr 10, 2026The pursuit of general-purpose robotics has yielded impressive foundation models, yet simulation-based benchmarking remains a bottleneck due to rapid performance saturation and a lack of true generalization testing. Existing benchmarks often exhibit significant domain overlap between training and evaluation, trivializing success rates and obscuring insights into robustness. We introduce RoboLab, a simulation benchmarking framework designed to address these challenges. Concretely, our framework is designed to answer two questions: (1) to what extent can we understand the performance of a real-world policy by analyzing its behavior in simulation, and (2) which external factors most strongly affect that behavior under controlled perturbations. First, RoboLab enables human-authored and LLM-enabled generation of scenes and tasks in a robot- and policy-agnostic manner within a physically realistic and photorealistic simulation. With this, we propose the RoboLab-120 benchmark, consisting of 120 tasks categorized into three competency axes: visual, procedural, relational competency, across three difficulty levels. Second, we introduce a systematic analysis of real-world policies that quantify both their performance and the sensitivity of their behavior to controlled perturbations, indicating that high-fidelity simulation can serve as a proxy for analyzing performance and its dependence on external factors. Evaluation with RoboLab exposes significant performance gap in current state-of-the-art models. By providing granular metrics and a scalable toolset, RoboLab offers a scalable framework for evaluating the true generalization capabilities of task-generalist robotic policies.
Inference-Time Policy Steering through Human Interactions
Nov 25, 2024



Generative policies trained with human demonstrations can autonomously accomplish multimodal, long-horizon tasks. However, during inference, humans are often removed from the policy execution loop, limiting the ability to guide a pre-trained policy towards a specific sub-goal or trajectory shape among multiple predictions. Naive human intervention may inadvertently exacerbate distribution shift, leading to constraint violations or execution failures. To better align policy output with human intent without inducing out-of-distribution errors, we propose an Inference-Time Policy Steering (ITPS) framework that leverages human interactions to bias the generative sampling process, rather than fine-tuning the policy on interaction data. We evaluate ITPS across three simulated and real-world benchmarks, testing three forms of human interaction and associated alignment distance metrics. Among six sampling strategies, our proposed stochastic sampling with diffusion policy achieves the best trade-off between alignment and distribution shift. Videos are available at https://yanweiw.github.io/itps/.
Aim My Robot: Precision Local Navigation to Any Object
Nov 22, 2024Existing navigation systems mostly consider "success" when the robot reaches within 1m radius to a goal. This precision is insufficient for emerging applications where the robot needs to be positioned precisely relative to an object for downstream tasks, such as docking, inspection, and manipulation. To this end, we design and implement Aim-My-Robot (AMR), a local navigation system that enables a robot to reach any object in its vicinity at the desired relative pose, with centimeter-level precision. AMR achieves high precision and robustness by leveraging multi-modal perception, precise action prediction, and is trained on large-scale photorealistic data generated in simulation. AMR shows strong sim2real transfer and can adapt to different robot kinematics and unseen objects with little to no fine-tuning.
Fast Explicit-Input Assistance for Teleoperation in Clutter
Feb 04, 2024



The performance of prediction-based assistance for robot teleoperation degrades in unseen or goal-rich environments due to incorrect or quickly-changing intent inferences. Poor predictions can confuse operators or cause them to change their control input to implicitly signal their goal, resulting in unnatural movement. We present a new assistance algorithm and interface for robotic manipulation where an operator can explicitly communicate a manipulation goal by pointing the end-effector. Rapid optimization and parallel collision checking in a local region around the pointing target enable direct, interactive control over grasp and place pose candidates. We compare the explicit pointing interface to an implicit inference-based assistance scheme in a within-subjects user study (N=20) where participants teleoperate a simulated robot to complete a multi-step singulation and stacking task in cluttered environments. We find that operators prefer the explicit interface, which improved completion time, pick and place success rates, and NASA TLX scores. Our code is available at https://github.com/NVlabs/fast-explicit-teleop
An imminent collision monitoring system with safe stopping interventions for autonomous aerial flights
Jun 17, 2022
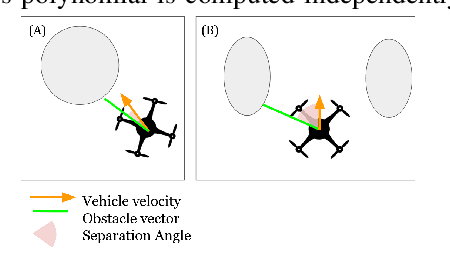

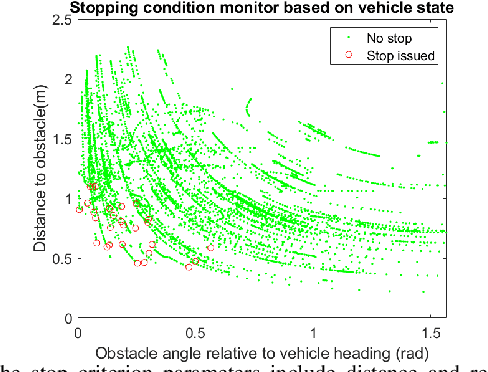
Collision avoidance requires tradeoffs in planning time horizons. Depending on the planner, safety cannot always be guaranteed in uncertain environments given map updates. To mitigate situations where the planner leads the vehicle into a state of collision or the vehicle reaches a point where no trajectories are feasible, we propose a continuous collision checking algorithm. The imminent collision checking system continuously monitors vehicle safety, and plans a safe trajectory that leads the vehicle to a stop within the observed map. We test our proposed pipeline alongside a teleoperated navigation in real-life experiments, and in simulated random-forest and warehouse environments where we show that with our method, we are able to mitigate collisions with a success rate of at least 90\%.
Fast and Agile Vision-Based Flight with Teleoperation and Collision Avoidance on a Multirotor
May 31, 2019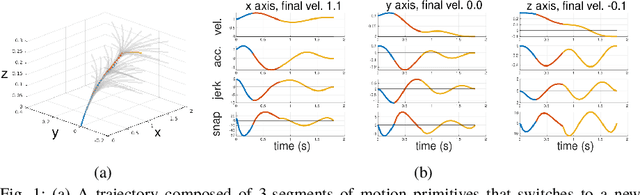

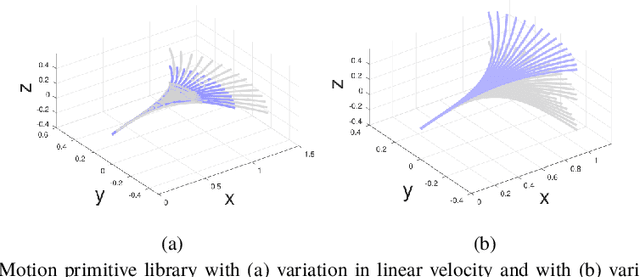
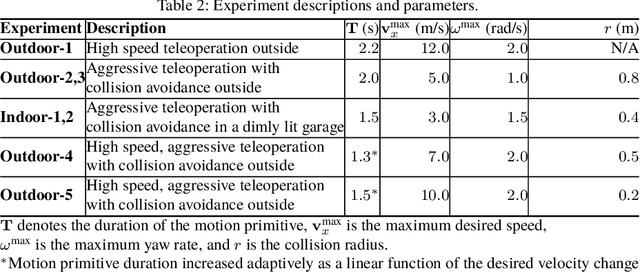
We present a multirotor architecture capable of aggressive autonomous flight and collision-free teleoperation in unstructured, GPS-denied environments. The proposed system enables aggressive and safe autonomous flight around clutter by integrating recent advancements in visual-inertial state estimation and teleoperation. Our teleoperation framework maps user inputs onto smooth and dynamically feasible motion primitives. Collision-free trajectories are ensured by querying a locally consistent map that is incrementally constructed from forward-facing depth observations. Our system enables a non-expert operator to safely navigate a multirotor around obstacles at speeds of 10 m/s. We achieve autonomous flights at speeds exceeding 12 m/s and accelerations exceeding 12 m/s^2 in a series of outdoor field experiments that validate our approach.