 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Length Generalization in Mamba via Image Reconstruction
Mar 12, 2026Mamba has attracted widespread interest as a general-purpose sequence model due to its low computational complexity and competitive performance relative to transformers. However, its performance can degrade when inference sequence lengths exceed those seen during training. We study this phenomenon using a controlled vision task in which Mamba reconstructs images from sequences of image patches. By analyzing reconstructions at different stages of sequence processing, we reveal that Mamba qualitatively adapts its behavior to the distribution of sequence lengths encountered during training, resulting in strategies that fail to generalize beyond this range. To support our analysis, we introduce a length-adaptive variant of Mamba that improves performance across training sequence lengths. Our results provide an intuitive perspective on length generalization in Mamba and suggest directions for improving the architecture.
Exploring the limits of Hierarchical World Models in Reinforcement Learning
Jun 01, 2024Hierarchical model-based reinforcement learning (HMBRL) aims to combine the benefits of better sample efficiency of model based reinforcement learning (MBRL) with the abstraction capability of hierarchical reinforcement learning (HRL) to solve complex tasks efficiently. While HMBRL has great potential, it still lacks wide adoption. In this work we describe a novel HMBRL framework and evaluate it thoroughly. To complement the multi-layered decision making idiom characteristic for HRL, we construct hierarchical world models that simulate environment dynamics at various levels of temporal abstraction. These models are used to train a stack of agents that communicate in a top-down manner by proposing goals to their subordinate agents. A significant focus of this study is the exploration of a static and environment agnostic temporal abstraction, which allows concurrent training of models and agents throughout the hierarchy. Unlike most goal-conditioned H(MB)RL approaches, it also leads to comparatively low dimensional abstract actions. Although our HMBRL approach did not outperform traditional methods in terms of final episode returns, it successfully facilitated decision making across two levels of abstraction using compact, low dimensional abstract actions. A central challenge in enhancing our method's performance, as uncovered through comprehensive experimentation, is model exploitation on the abstract level of our world model stack. We provide an in depth examination of this issue, discussing its implications for the field and suggesting directions for future research to overcome this challenge. By sharing these findings, we aim to contribute to the broader discourse on refining HMBRL methodologies and to assist in the development of more effective autonomous learning systems for complex decision-making environments.
Benchmarks for Physical Reasoning AI
Dec 17, 2023



Physical reasoning is a crucial aspect in the development of general AI systems, given that human learning starts with interacting with the physical world before progressing to more complex concepts. Although researchers have studied and assessed the physical reasoning of AI approaches through various specific benchmarks, there is no comprehensive approach to evaluating and measuring progress. Therefore, we aim to offer an overview of existing benchmarks and their solution approaches and propose a unified perspective for measuring the physical reasoning capacity of AI systems. We select benchmarks that are designed to test algorithmic performance in physical reasoning tasks. While each of the selected benchmarks poses a unique challenge, their ensemble provides a comprehensive proving ground for an AI generalist agent with a measurable skill level for various physical reasoning concepts. This gives an advantage to such an ensemble of benchmarks over other holistic benchmarks that aim to simulate the real world by intertwining its complexity and many concepts. We group the presented set of physical reasoning benchmarks into subcategories so that more narrow generalist AI agents can be tested first on these groups.
Modular Networks Prevent Catastrophic Interference in Model-Based Multi-Task Reinforcement Learning
Nov 15, 2021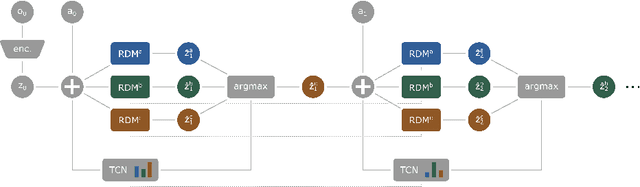

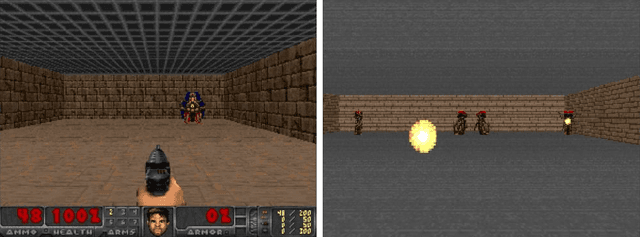
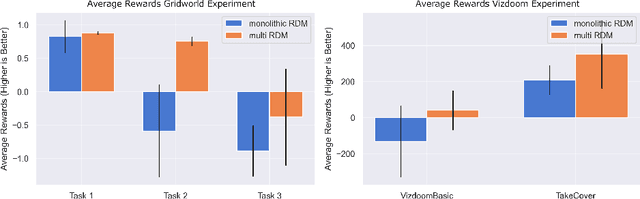
In a multi-task reinforcement learning setting, the learner commonly benefits from training on multiple related tasks by exploiting similarities among them. At the same time, the trained agent is able to solve a wider range of different problems. While this effect is well documented for model-free multi-task methods, we demonstrate a detrimental effect when using a single learned dynamics model for multiple tasks. Thus, we address the fundamental question of whether model-based multi-task reinforcement learning benefits from shared dynamics models in a similar way model-free methods do from shared policy networks. Using a single dynamics model, we see clear evidence of task confusion and reduced performance. As a remedy, enforcing an internal structure for the learned dynamics model by training isolated sub-networks for each task notably improves performance while using the same amount of parameters. We illustrate our findings by comparing both methods on a simple gridworld and a more complex vizdoom multi-task experiment.
Latent Representation Prediction Networks
Sep 20, 2020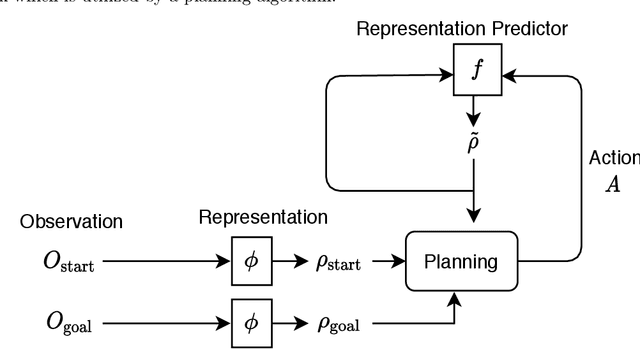
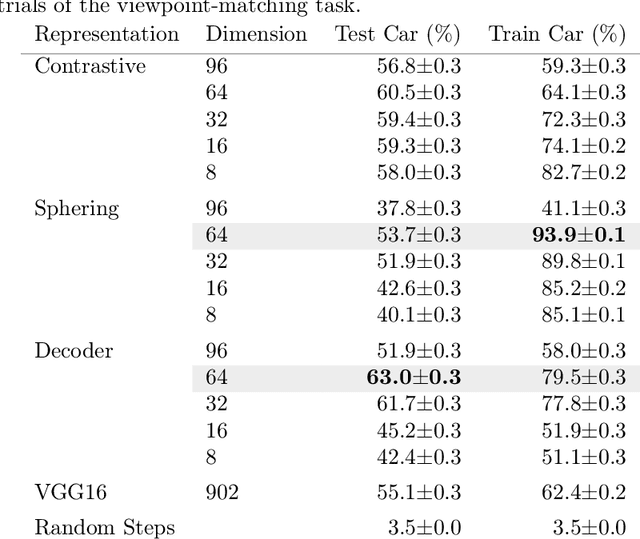
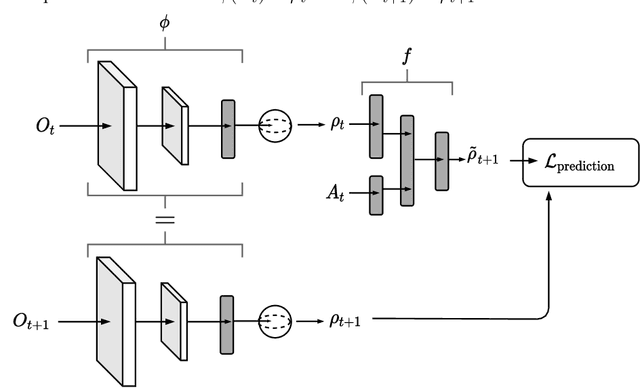
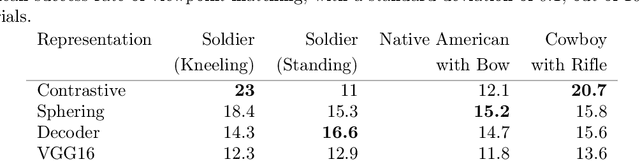
Deeply-learned planning methods are often based on learning representations that are optimized for unrelated tasks. For example, they might be trained on reconstructing the environment. These representations are then combined with predictor functions for simulating rollouts to navigate the environment. We find this principle of learning representations unsatisfying and propose to learn them such that they are directly optimized for the task at hand: to be maximally predictable for the predictor function. This results in representations that are by design optimal for the downstream task of planning, where the learned predictor function is used as a forward model. To this end, we propose a new way of jointly learning this representation along with the prediction function, a system we dub Latent Representation Prediction Network (LARP). The prediction function is used as a forward model for search on a graph in a viewpoint-matching task and the representation learned to maximize predictability is found to outperform a pre-trained representation. Our approach is shown to be more sample-efficient than standard reinforcement learning methods and our learned representation transfers successfully to dissimilar objects.