 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Speech frame implementation for speech analysis and recognition
Dec 15, 2021

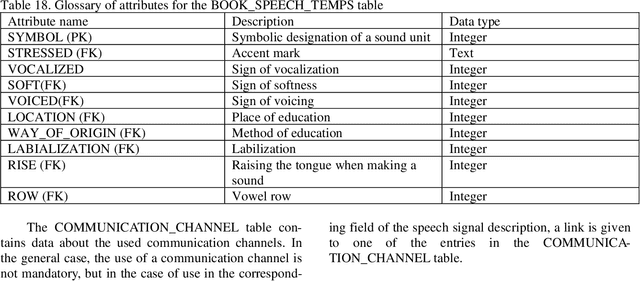

Distinctive features of the created speech frame are: the ability to take into account the emotional state of the speaker, sup-port for working with diseases of the speech-forming tract of speakers and the presence of manual segmentation of a num-ber of speech signals. In addition, the system is focused on Russian-language speech material, unlike most analogs.
Revisiting End-to-End Speech-to-Text Translation From Scratch
Jun 09, 2022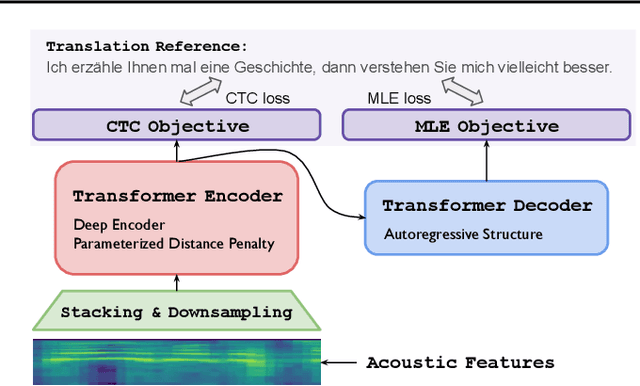
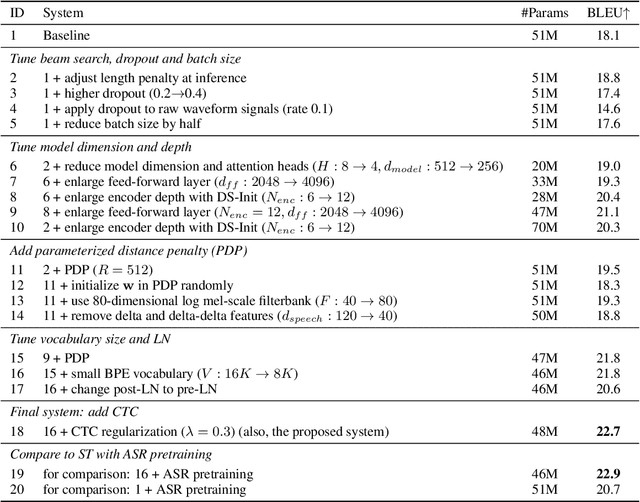
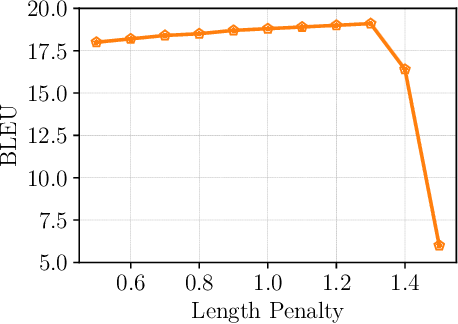
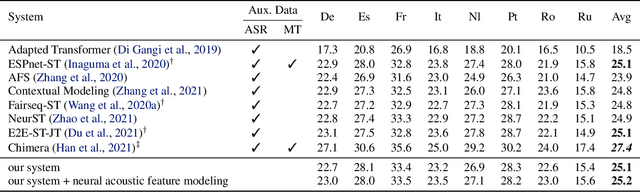
End-to-end (E2E) speech-to-text translation (ST) often depends on pretraining its encoder and/or decoder using source transcripts via speech recognition or text translation tasks, without which translation performance drops substantially. However, transcripts are not always available, and how significant such pretraining is for E2E ST has rarely been studied in the literature. In this paper, we revisit this question and explore the extent to which the quality of E2E ST trained on speech-translation pairs alone can be improved. We reexamine several techniques proven beneficial to ST previously, and offer a set of best practices that biases a Transformer-based E2E ST system toward training from scratch. Besides, we propose parameterized distance penalty to facilitate the modeling of locality in the self-attention model for speech. On four benchmarks covering 23 languages, our experiments show that, without using any transcripts or pretraining, the proposed system reaches and even outperforms previous studies adopting pretraining, although the gap remains in (extremely) low-resource settings. Finally, we discuss neural acoustic feature modeling, where a neural model is designed to extract acoustic features from raw speech signals directly, with the goal to simplify inductive biases and add freedom to the model in describing speech. For the first time, we demonstrate its feasibility and show encouraging results on ST tasks.
DAMO-NLP at NLPCC-2022 Task 2: Knowledge Enhanced Robust NER for Speech Entity Linking
Sep 29, 2022Speech Entity Linking aims to recognize and disambiguate named entities in spoken languages. Conventional methods suffer gravely from the unfettered speech styles and the noisy transcripts generated by ASR systems. In this paper, we propose a novel approach called Knowledge Enhanced Named Entity Recognition (KENER), which focuses on improving robustness through painlessly incorporating proper knowledge in the entity recognition stage and thus improving the overall performance of entity linking. KENER first retrieves candidate entities for a sentence without mentions, and then utilizes the entity descriptions as extra information to help recognize mentions. The candidate entities retrieved by a dense retrieval module are especially useful when the input is short or noisy. Moreover, we investigate various data sampling strategies and design effective loss functions, in order to improve the quality of retrieved entities in both recognition and disambiguation stages. Lastly, a linking with filtering module is applied as the final safeguard, making it possible to filter out wrongly-recognized mentions. Our system achieves 1st place in Track 1 and 2nd place in Track 2 of NLPCC-2022 Shared Task 2.
SVTS: Scalable Video-to-Speech Synthesis
May 04, 2022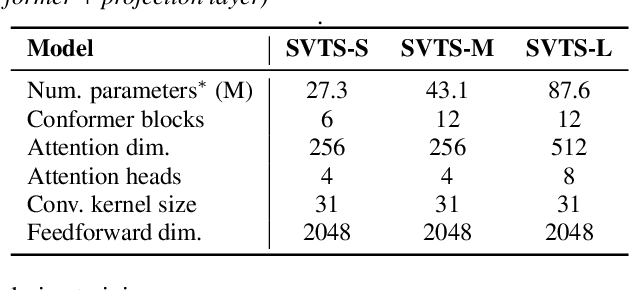
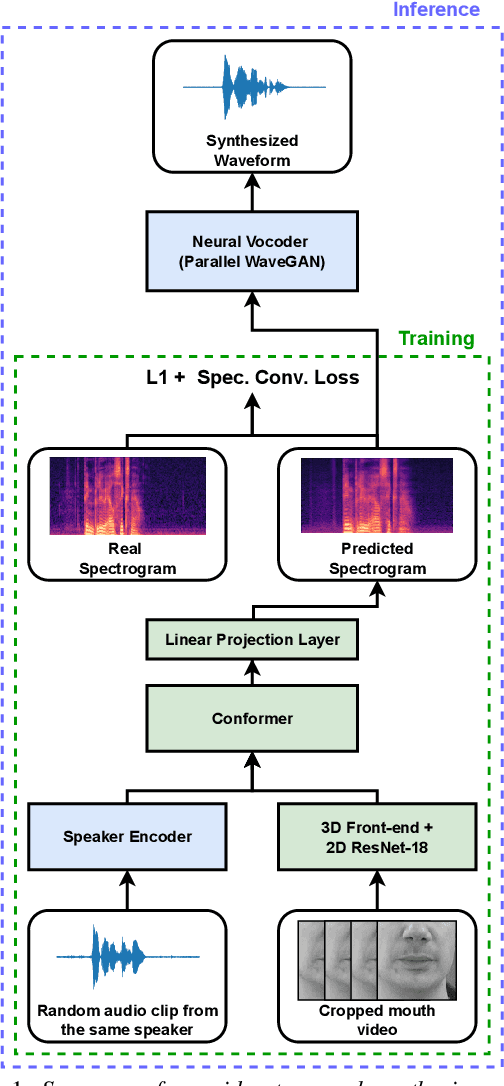
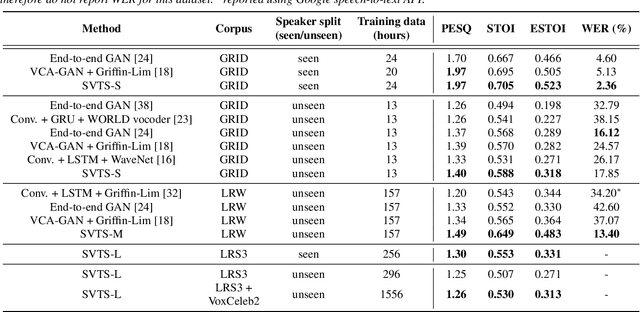
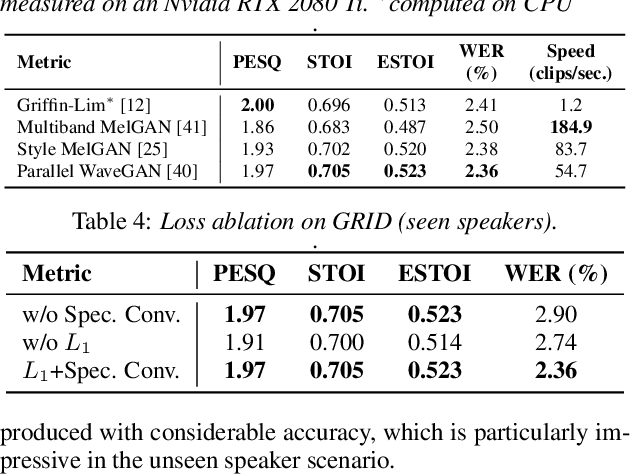
Video-to-speech synthesis (also known as lip-to-speech) refers to the translation of silent lip movements into the corresponding audio. This task has received an increasing amount of attention due to its self-supervised nature (i.e., can be trained without manual labelling) combined with the ever-growing collection of audio-visual data available online. Despite these strong motivations, contemporary video-to-speech works focus mainly on small- to medium-sized corpora with substantial constraints in both vocabulary and setting. In this work, we introduce a scalable video-to-speech framework consisting of two components: a video-to-spectrogram predictor and a pre-trained neural vocoder, which converts the mel-frequency spectrograms into waveform audio. We achieve state-of-the art results for GRID and considerably outperform previous approaches on LRW. More importantly, by focusing on spectrogram prediction using a simple feedforward model, we can efficiently and effectively scale our method to very large and unconstrained datasets: To the best of our knowledge, we are the first to show intelligible results on the challenging LRS3 dataset.
Transfer Learning Framework for Low-Resource Text-to-Speech using a Large-Scale Unlabeled Speech Corpus
Mar 29, 2022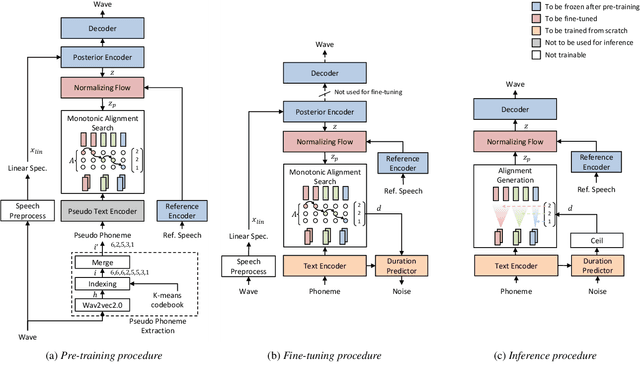
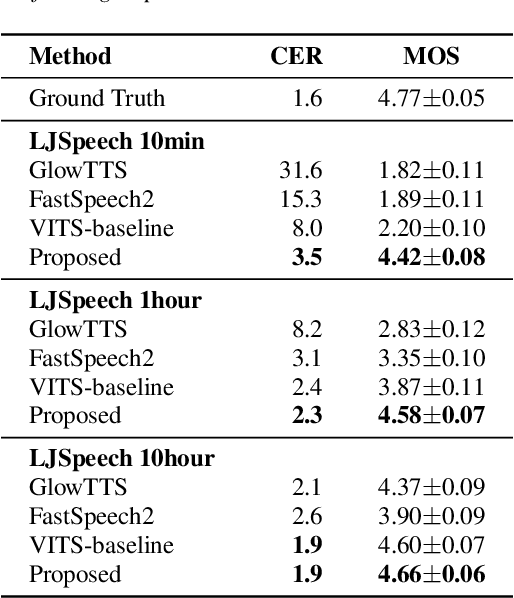
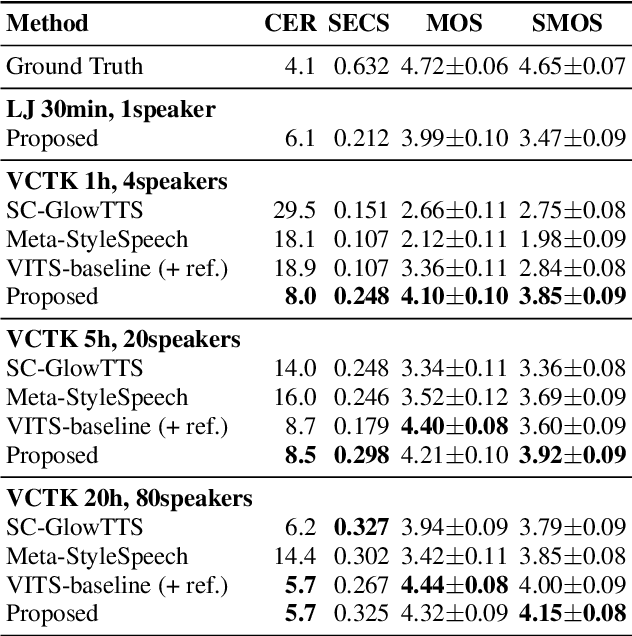
Training a text-to-speech (TTS) model requires a large scale text labeled speech corpus, which is troublesome to collect. In this paper, we propose a transfer learning framework for TTS that utilizes a large amount of unlabeled speech dataset for pre-training. By leveraging wav2vec2.0 representation, unlabeled speech can highly improve performance, especially in the lack of labeled speech. We also extend the proposed method to zero-shot multi-speaker TTS (ZS-TTS). The experimental results verify the effectiveness of the proposed method in terms of naturalness, intelligibility, and speaker generalization. We highlight that the single speaker TTS model fine-tuned on the only 10 minutes of labeled dataset outperforms the other baselines, and the ZS-TTS model fine-tuned on the only 30 minutes of single speaker dataset can generate the voice of the arbitrary speaker, by pre-training on unlabeled multi-speaker speech corpus.
E-Branchformer: Branchformer with Enhanced merging for speech recognition
Sep 30, 2022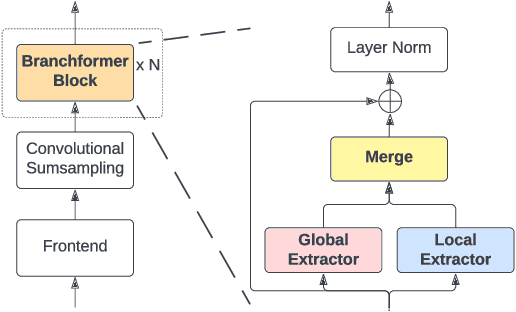
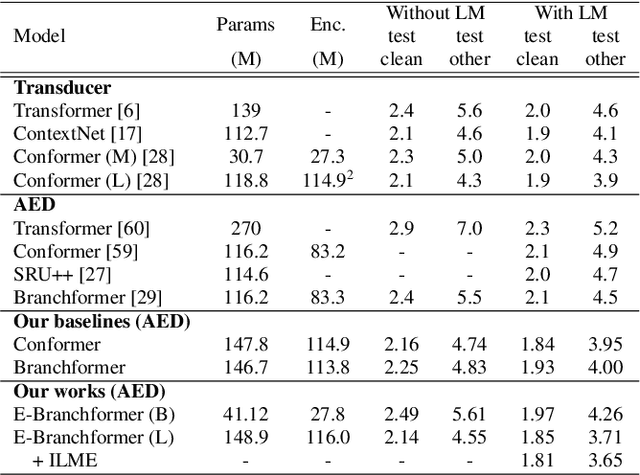
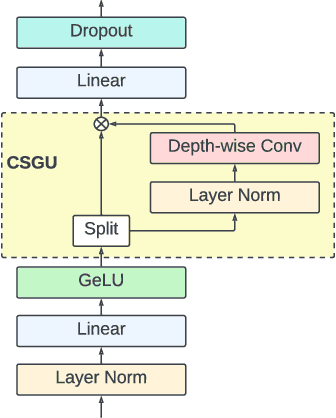
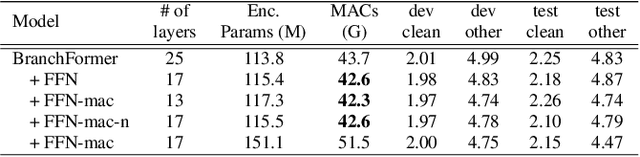
Conformer, combining convolution and self-attention sequentially to capture both local and global information, has shown remarkable performance and is currently regarded as the state-of-the-art for automatic speech recognition (ASR). Several other studies have explored integrating convolution and self-attention but they have not managed to match Conformer's performance. The recently introduced Branchformer achieves comparable performance to Conformer by using dedicated branches of convolution and self-attention and merging local and global context from each branch. In this paper, we propose E-Branchformer, which enhances Branchformer by applying an effective merging method and stacking additional point-wise modules. E-Branchformer sets new state-of-the-art word error rates (WERs) 1.81% and 3.65% on LibriSpeech test-clean and test-other sets without using any external training data.
BibleTTS: a large, high-fidelity, multilingual, and uniquely African speech corpus
Jul 07, 2022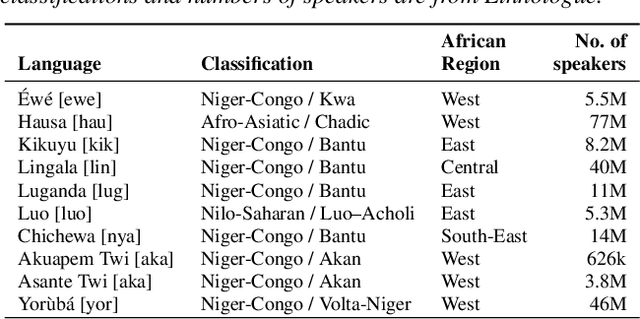
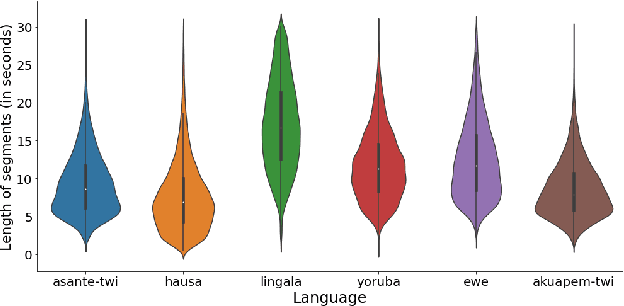
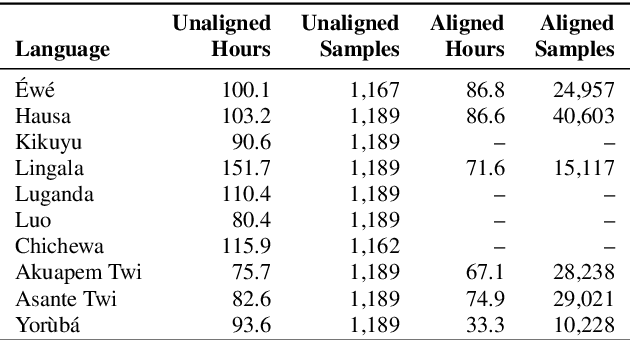
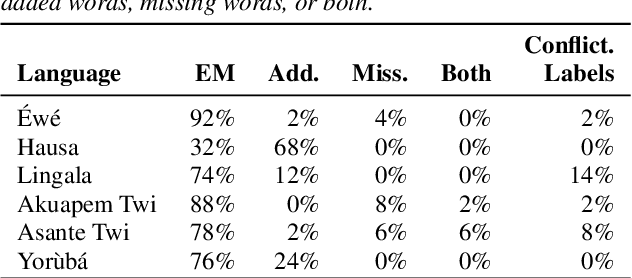
BibleTTS is a large, high-quality, open speech dataset for ten languages spoken in Sub-Saharan Africa. The corpus contains up to 86 hours of aligned, studio quality 48kHz single speaker recordings per language, enabling the development of high-quality text-to-speech models. The ten languages represented are: Akuapem Twi, Asante Twi, Chichewa, Ewe, Hausa, Kikuyu, Lingala, Luganda, Luo, and Yoruba. This corpus is a derivative work of Bible recordings made and released by the Open.Bible project from Biblica. We have aligned, cleaned, and filtered the original recordings, and additionally hand-checked a subset of the alignments for each language. We present results for text-to-speech models with Coqui TTS. The data is released under a commercial-friendly CC-BY-SA license.
Exploiting Hidden Representations from a DNN-based Speech Recogniser for Speech Intelligibility Prediction in Hearing-impaired Listeners
Apr 08, 2022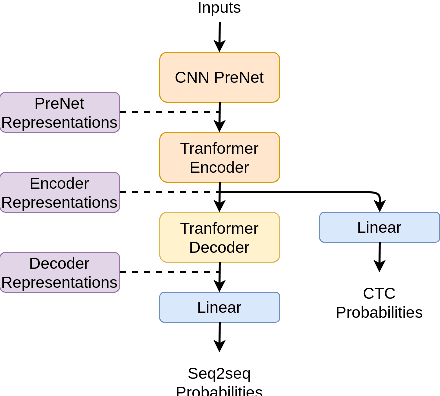
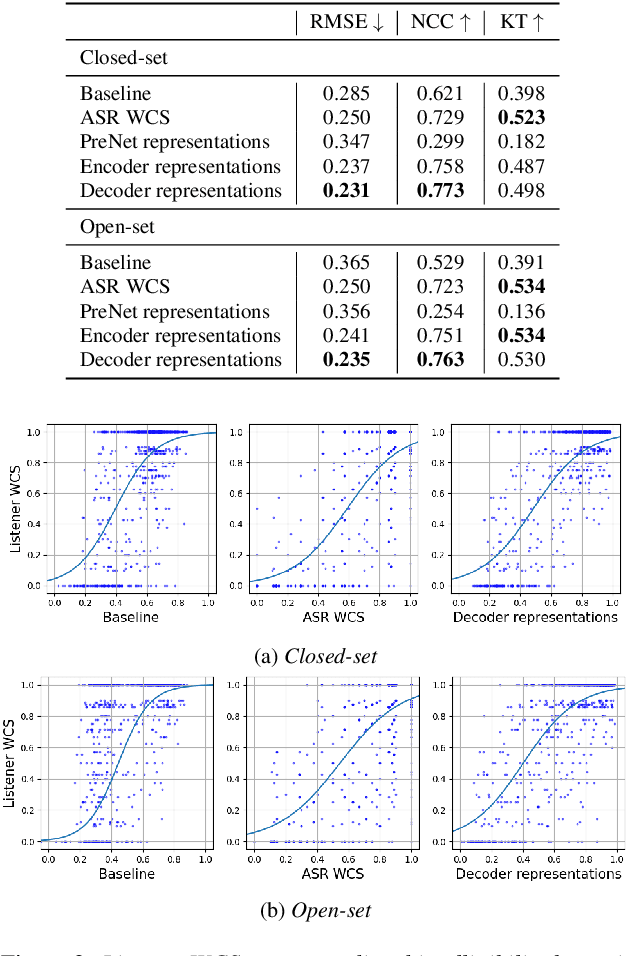
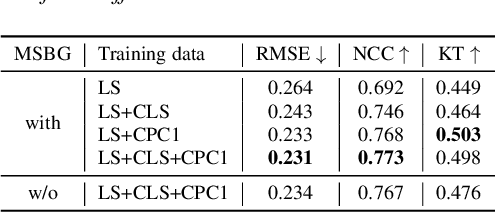
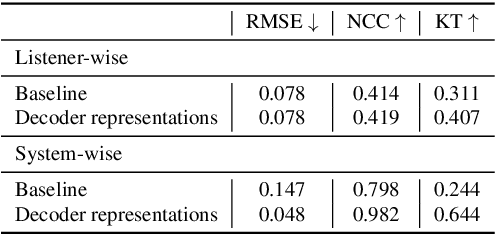
An accurate objective speech intelligibility prediction algorithms is of great interest for many applications such as speech enhancement for hearing aids. Most algorithms measures the signal-to-noise ratios or correlations between the acoustic features of clean reference signals and degraded signals. However, these hand-picked acoustic features are usually not explicitly correlated with recognition. Meanwhile, deep neural network (DNN) based automatic speech recogniser (ASR) is approaching human performance in some speech recognition tasks. This work leverages the hidden representations from DNN-based ASR as features for speech intelligibility prediction in hearing-impaired listeners. The experiments based on a hearing aid intelligibility database show that the proposed method could make better prediction than a widely used short-time objective intelligibility (STOI) based binaural measure.
StyleTTS: A Style-Based Generative Model for Natural and Diverse Text-to-Speech Synthesis
May 30, 2022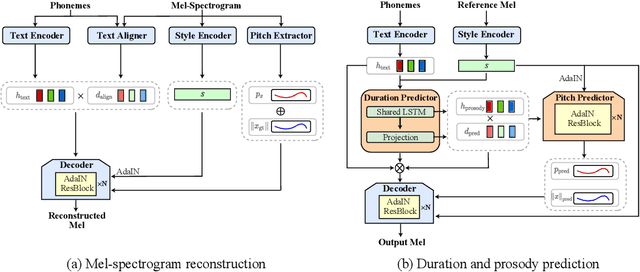

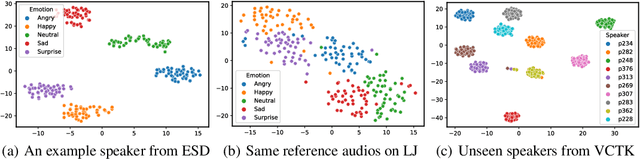

Text-to-Speech (TTS) has recently seen great progress in synthesizing high-quality speech owing to the rapid development of parallel TTS systems, but producing speech with naturalistic prosodic variations, speaking styles and emotional tones remains challenging. Moreover, since duration and speech are generated separately, parallel TTS models still have problems finding the best monotonic alignments that are crucial for naturalistic speech synthesis. Here, we propose StyleTTS, a style-based generative model for parallel TTS that can synthesize diverse speech with natural prosody from a reference speech utterance. With novel Transferable Monotonic Aligner (TMA) and duration-invariant data augmentation schemes, our method significantly outperforms state-of-the-art models on both single and multi-speaker datasets in subjective tests of speech naturalness and speaker similarity. Through self-supervised learning of the speaking styles, our model can synthesize speech with the same prosodic and emotional tone as any given reference speech without the need for explicitly labeling these categories.
Streaming, fast and accurate on-device Inverse Text Normalization for Automatic Speech Recognition
Nov 07, 2022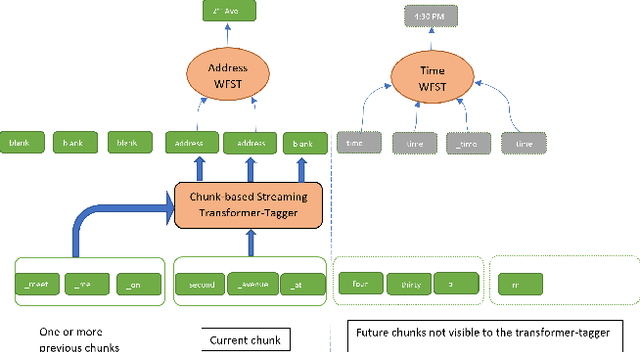
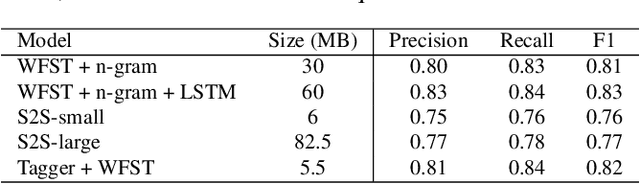
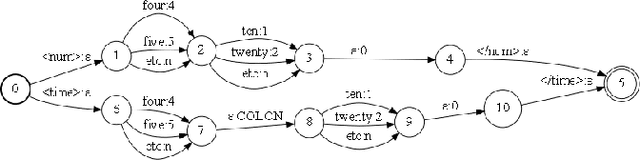
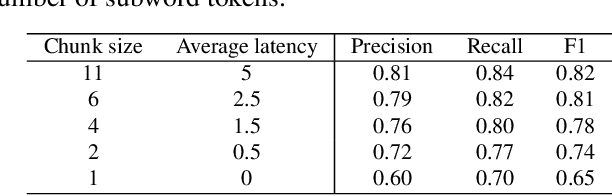
Automatic Speech Recognition (ASR) systems typically yield output in lexical form. However, humans prefer a written form output. To bridge this gap, ASR systems usually employ Inverse Text Normalization (ITN). In previous works, Weighted Finite State Transducers (WFST) have been employed to do ITN. WFSTs are nicely suited to this task but their size and run-time costs can make deployment on embedded applications challenging. In this paper, we describe the development of an on-device ITN system that is streaming, lightweight & accurate. At the core of our system is a streaming transformer tagger, that tags lexical tokens from ASR. The tag informs which ITN category might be applied, if at all. Following that, we apply an ITN-category-specific WFST, only on the tagged text, to reliably perform the ITN conversion. We show that the proposed ITN solution performs equivalent to strong baselines, while being significantly smaller in size and retaining customization capabilities.