 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMakeSinger: A Semi-Supervised Training Method for Data-Efficient Singing Voice Synthesis via Classifier-free Diffusion Guidance
Jun 10, 2024


In this paper, we propose MakeSinger, a semi-supervised training method for singing voice synthesis (SVS) via classifier-free diffusion guidance. The challenge in SVS lies in the costly process of gathering aligned sets of text, pitch, and audio data. MakeSinger enables the training of the diffusion-based SVS model from any speech and singing voice data regardless of its labeling, thereby enhancing the quality of generated voices with large amount of unlabeled data. At inference, our novel dual guiding mechanism gives text and pitch guidance on the reverse diffusion step by estimating the score of masked input. Experimental results show that the model trained in a semi-supervised manner outperforms other baselines trained only on the labeled data in terms of pronunciation, pitch accuracy and overall quality. Furthermore, we demonstrate that by adding Text-to-Speech (TTS) data in training, the model can synthesize the singing voices of TTS speakers even without their singing voices.
Utilizing Neural Transducers for Two-Stage Text-to-Speech via Semantic Token Prediction
Jan 03, 2024



We propose a novel text-to-speech (TTS) framework centered around a neural transducer. Our approach divides the whole TTS pipeline into semantic-level sequence-to-sequence (seq2seq) modeling and fine-grained acoustic modeling stages, utilizing discrete semantic tokens obtained from wav2vec2.0 embeddings. For a robust and efficient alignment modeling, we employ a neural transducer named token transducer for the semantic token prediction, benefiting from its hard monotonic alignment constraints. Subsequently, a non-autoregressive (NAR) speech generator efficiently synthesizes waveforms from these semantic tokens. Additionally, a reference speech controls temporal dynamics and acoustic conditions at each stage. This decoupled framework reduces the training complexity of TTS while allowing each stage to focus on semantic and acoustic modeling. Our experimental results on zero-shot adaptive TTS demonstrate that our model surpasses the baseline in terms of speech quality and speaker similarity, both objectively and subjectively. We also delve into the inference speed and prosody control capabilities of our approach, highlighting the potential of neural transducers in TTS frameworks.
Transduce and Speak: Neural Transducer for Text-to-Speech with Semantic Token Prediction
Nov 08, 2023We introduce a text-to-speech(TTS) framework based on a neural transducer. We use discretized semantic tokens acquired from wav2vec2.0 embeddings, which makes it easy to adopt a neural transducer for the TTS framework enjoying its monotonic alignment constraints. The proposed model first generates aligned semantic tokens using the neural transducer, then synthesizes a speech sample from the semantic tokens using a non-autoregressive(NAR) speech generator. This decoupled framework alleviates the training complexity of TTS and allows each stage to focus on 1) linguistic and alignment modeling and 2) fine-grained acoustic modeling, respectively. Experimental results on the zero-shot adaptive TTS show that the proposed model exceeds the baselines in speech quality and speaker similarity via objective and subjective measures. We also investigate the inference speed and prosody controllability of our proposed model, showing the potential of the neural transducer for TTS frameworks.
SNAC: Speaker-normalized affine coupling layer in flow-based architecture for zero-shot multi-speaker text-to-speech
Nov 30, 2022Zero-shot multi-speaker text-to-speech (ZSM-TTS) models aim to generate a speech sample with the voice characteristic of an unseen speaker. The main challenge of ZSM-TTS is to increase the overall speaker similarity for unseen speakers. One of the most successful speaker conditioning methods for flow-based multi-speaker text-to-speech (TTS) models is to utilize the functions which predict the scale and bias parameters of the affine coupling layers according to the given speaker embedding vector. In this letter, we improve on the previous speaker conditioning method by introducing a speaker-normalized affine coupling (SNAC) layer which allows for unseen speaker speech synthesis in a zero-shot manner leveraging a normalization-based conditioning technique. The newly designed coupling layer explicitly normalizes the input by the parameters predicted from a speaker embedding vector while training, enabling an inverse process of denormalizing for a new speaker embedding at inference. The proposed conditioning scheme yields the state-of-the-art performance in terms of the speech quality and speaker similarity in a ZSM-TTS setting.
Adversarial Speaker-Consistency Learning Using Untranscribed Speech Data for Zero-Shot Multi-Speaker Text-to-Speech
Oct 12, 2022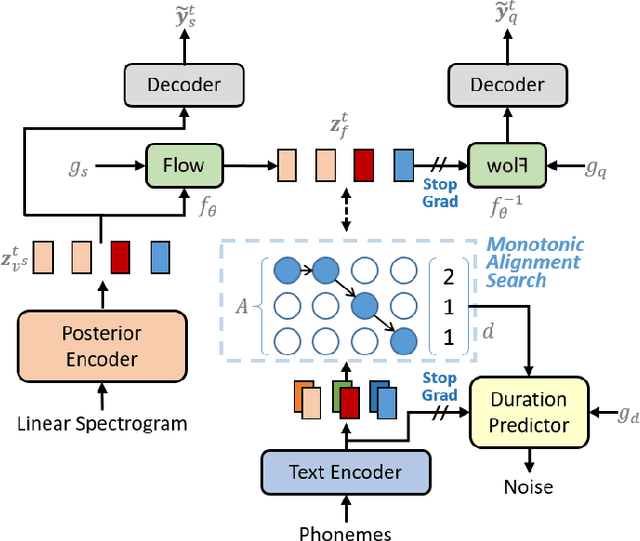
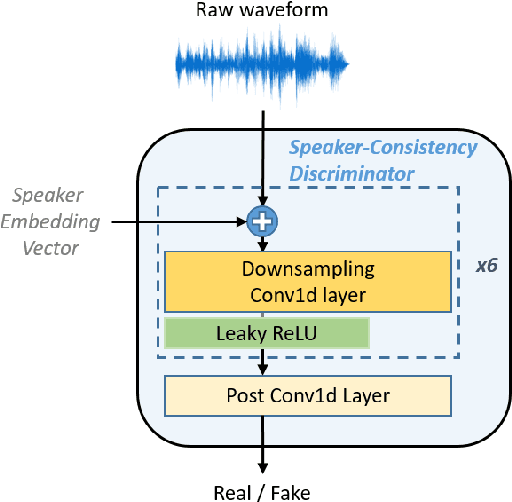
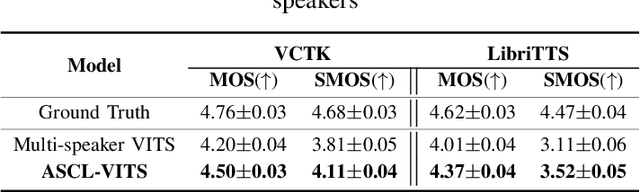
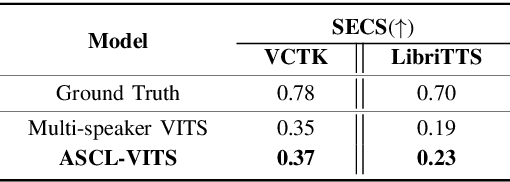
Several recently proposed text-to-speech (TTS) models achieved to generate the speech samples with the human-level quality in the single-speaker and multi-speaker TTS scenarios with a set of pre-defined speakers. However, synthesizing a new speaker's voice with a single reference audio, commonly known as zero-shot multi-speaker text-to-speech (ZSM-TTS), is still a very challenging task. The main challenge of ZSM-TTS is the speaker domain shift problem upon the speech generation of a new speaker. To mitigate this problem, we propose adversarial speaker-consistency learning (ASCL). The proposed method first generates an additional speech of a query speaker using the external untranscribed datasets at each training iteration. Then, the model learns to consistently generate the speech sample of the same speaker as the corresponding speaker embedding vector by employing an adversarial learning scheme. The experimental results show that the proposed method is effective compared to the baseline in terms of the quality and speaker similarity in ZSM-TTS.
Transfer Learning Framework for Low-Resource Text-to-Speech using a Large-Scale Unlabeled Speech Corpus
Mar 29, 2022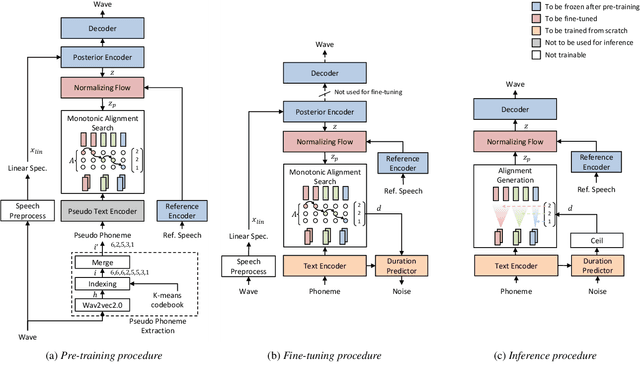
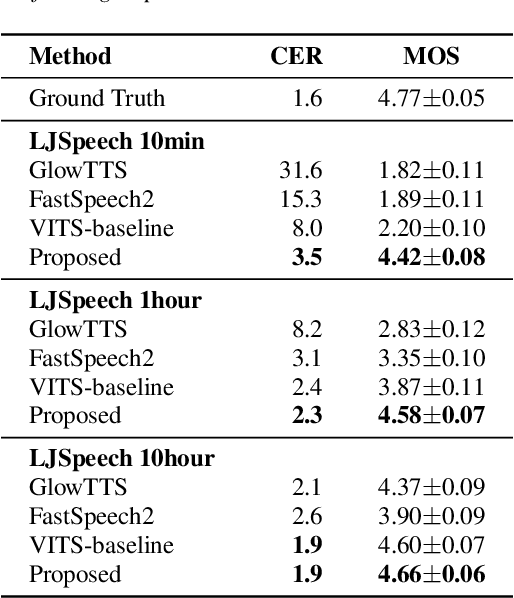
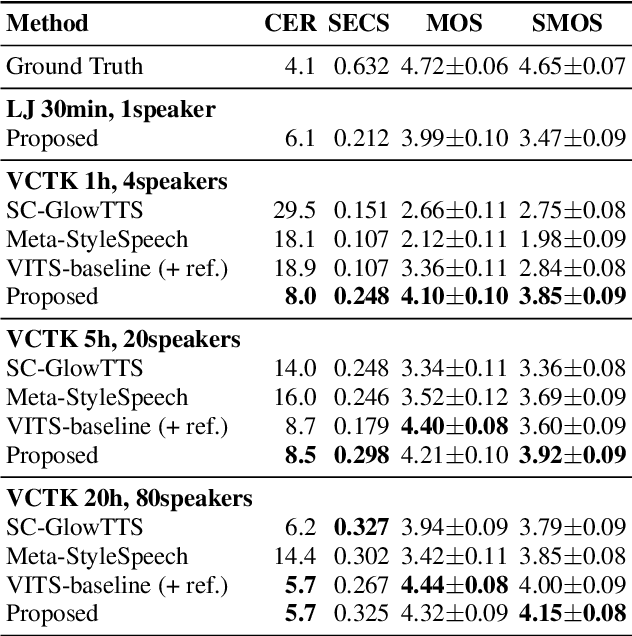
Training a text-to-speech (TTS) model requires a large scale text labeled speech corpus, which is troublesome to collect. In this paper, we propose a transfer learning framework for TTS that utilizes a large amount of unlabeled speech dataset for pre-training. By leveraging wav2vec2.0 representation, unlabeled speech can highly improve performance, especially in the lack of labeled speech. We also extend the proposed method to zero-shot multi-speaker TTS (ZS-TTS). The experimental results verify the effectiveness of the proposed method in terms of naturalness, intelligibility, and speaker generalization. We highlight that the single speaker TTS model fine-tuned on the only 10 minutes of labeled dataset outperforms the other baselines, and the ZS-TTS model fine-tuned on the only 30 minutes of single speaker dataset can generate the voice of the arbitrary speaker, by pre-training on unlabeled multi-speaker speech corpus.
Diff-TTS: A Denoising Diffusion Model for Text-to-Speech
Apr 03, 2021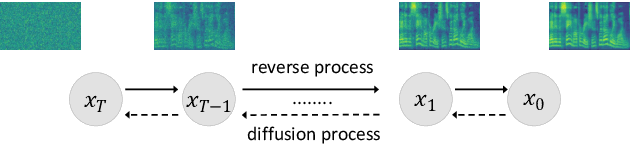

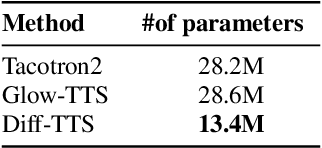
Although neural text-to-speech (TTS) models have attracted a lot of attention and succeeded in generating human-like speech, there is still room for improvements to its naturalness and architectural efficiency. In this work, we propose a novel non-autoregressive TTS model, namely Diff-TTS, which achieves highly natural and efficient speech synthesis. Given the text, Diff-TTS exploits a denoising diffusion framework to transform the noise signal into a mel-spectrogram via diffusion time steps. In order to learn the mel-spectrogram distribution conditioned on the text, we present a likelihood-based optimization method for TTS. Furthermore, to boost up the inference speed, we leverage the accelerated sampling method that allows Diff-TTS to generate raw waveforms much faster without significantly degrading perceptual quality. Through experiments, we verified that Diff-TTS generates 28 times faster than the real-time with a single NVIDIA 2080Ti GPU.
Expressive Text-to-Speech using Style Tag
Apr 01, 2021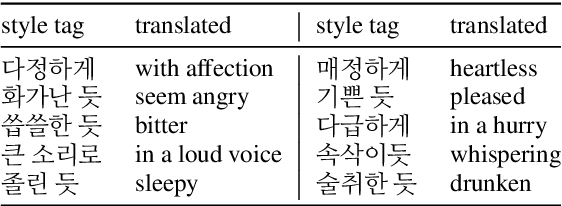
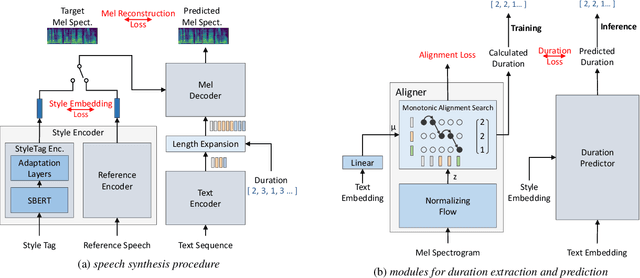
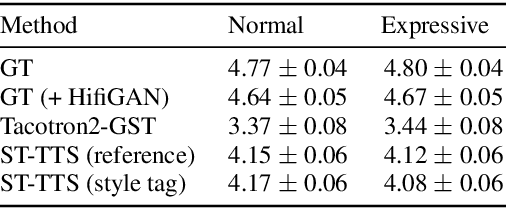
As recent text-to-speech (TTS) systems have been rapidly improved in speech quality and generation speed, many researchers now focus on a more challenging issue: expressive TTS. To control speaking styles, existing expressive TTS models use categorical style index or reference speech as style input. In this work, we propose StyleTagging-TTS (ST-TTS), a novel expressive TTS model that utilizes a style tag written in natural language. Using a style-tagged TTS dataset and a pre-trained language model, we modeled the relationship between linguistic embedding and speaking style domain, which enables our model to work even with style tags unseen during training. As style tag is written in natural language, it can control speaking style in a more intuitive, interpretable, and scalable way compared with style index or reference speech. In addition, in terms of model architecture, we propose an efficient non-autoregressive (NAR) TTS architecture with single-stage training. The experimental result shows that ST-TTS outperforms the existing expressive TTS model, Tacotron2-GST in speech quality and expressiveness.
WaveNODE: A Continuous Normalizing Flow for Speech Synthesis
Jul 02, 2020
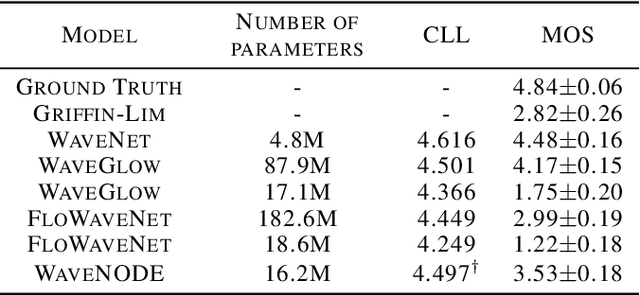
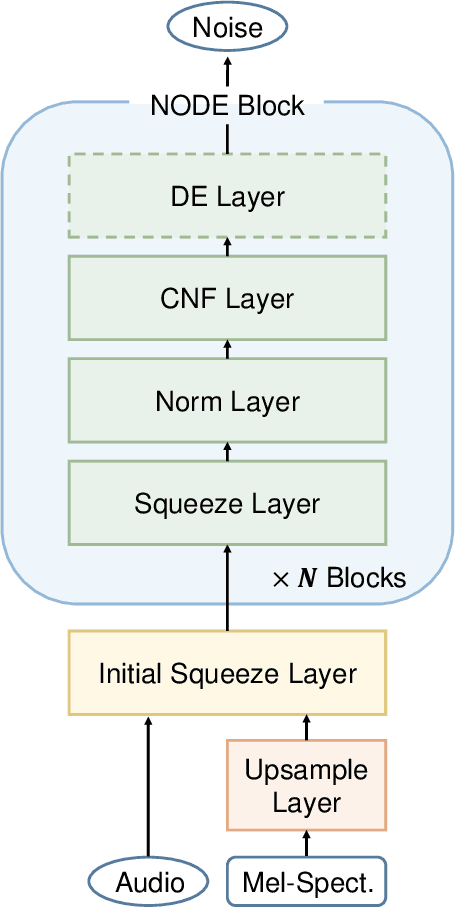

In recent years, various flow-based generative models have been proposed to generate high-fidelity waveforms in real-time. However, these models require either a well-trained teacher network or a number of flow steps making them memory-inefficient. In this paper, we propose a novel generative model called WaveNODE which exploits a continuous normalizing flow for speech synthesis. Unlike the conventional models, WaveNODE places no constraint on the function used for flow operation, thus allowing the usage of more flexible and complex functions. Moreover, WaveNODE can be optimized to maximize the likelihood without requiring any teacher network or auxiliary loss terms. We experimentally show that WaveNODE achieves comparable performance with fewer parameters compared to the conventional flow-based vocoders.