 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison of parameters of vowel sounds of russian and english languages
Jan 26, 2024In multilingual speech recognition systems, a situation can often arise when the language is not known in advance, but the signal has already been received and is being processed. For such cases, some generalized model is needed that will be able to respond to phonetic differences and, depending on them, correctly recog-nize speech in the desired language. To build such a model, it is necessary to set the values of phonetic parameters, and then compare similar sounds, establishing significant differences.
Speech frame implementation for speech analysis and recognition
Dec 15, 2021
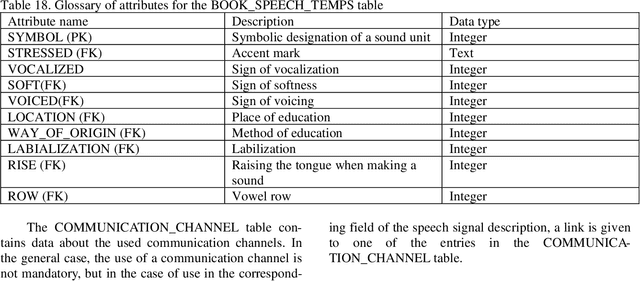

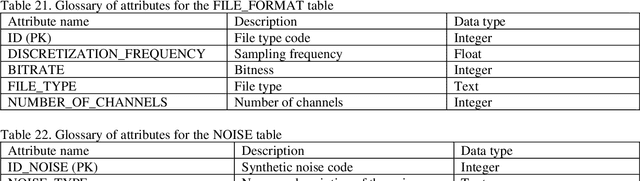
Distinctive features of the created speech frame are: the ability to take into account the emotional state of the speaker, sup-port for working with diseases of the speech-forming tract of speakers and the presence of manual segmentation of a num-ber of speech signals. In addition, the system is focused on Russian-language speech material, unlike most analogs.