 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithful, Unfaithful or Ambiguous? Multi-Agent Debate with Initial Stance for Summary Evaluation
Feb 12, 2025Faithfulness evaluators based on large language models (LLMs) are often fooled by the fluency of the text and struggle with identifying errors in the summaries. We propose an approach to summary faithfulness evaluation in which multiple LLM-based agents are assigned initial stances (regardless of what their belief might be) and forced to come up with a reason to justify the imposed belief, thus engaging in a multi-round debate to reach an agreement. The uniformly distributed initial assignments result in a greater diversity of stances leading to more meaningful debates and ultimately more errors identified. Furthermore, by analyzing the recent faithfulness evaluation datasets, we observe that naturally, it is not always the case for a summary to be either faithful to the source document or not. We therefore introduce a new dimension, ambiguity, and a detailed taxonomy to identify such special cases. Experiments demonstrate our approach can help identify ambiguities, and have even a stronger performance on non-ambiguous summaries.
Zero-resource Speech Translation and Recognition with LLMs
Dec 24, 2024


Despite recent advancements in speech processing, zero-resource speech translation (ST) and automatic speech recognition (ASR) remain challenging problems. In this work, we propose to leverage a multilingual Large Language Model (LLM) to perform ST and ASR in languages for which the model has never seen paired audio-text data. We achieve this by using a pre-trained multilingual speech encoder, a multilingual LLM, and a lightweight adaptation module that maps the audio representations to the token embedding space of the LLM. We perform several experiments both in ST and ASR to understand how to best train the model and what data has the most impact on performance in previously unseen languages. In ST, our best model is capable to achieve BLEU scores over 23 in CoVoST2 for two previously unseen languages, while in ASR, we achieve WERs of up to 28.2\%. We finally show that the performance of our system is bounded by the ability of the LLM to output text in the desired language.
PEAVS: Perceptual Evaluation of Audio-Visual Synchrony Grounded in Viewers' Opinion Scores
Apr 10, 2024



Recent advancements in audio-visual generative modeling have been propelled by progress in deep learning and the availability of data-rich benchmarks. However, the growth is not attributed solely to models and benchmarks. Universally accepted evaluation metrics also play an important role in advancing the field. While there are many metrics available to evaluate audio and visual content separately, there is a lack of metrics that offer a quantitative and interpretable measure of audio-visual synchronization for videos "in the wild". To address this gap, we first created a large scale human annotated dataset (100+ hrs) representing nine types of synchronization errors in audio-visual content and how human perceive them. We then developed a PEAVS (Perceptual Evaluation of Audio-Visual Synchrony) score, a novel automatic metric with a 5-point scale that evaluates the quality of audio-visual synchronization. We validate PEAVS using a newly generated dataset, achieving a Pearson correlation of 0.79 at the set level and 0.54 at the clip level when compared to human labels. In our experiments, we observe a relative gain 50% over a natural extension of Fr\'echet based metrics for Audio-Visual synchrony, confirming PEAVS efficacy in objectively modeling subjective perceptions of audio-visual synchronization for videos "in the wild".
E-Branchformer: Branchformer with Enhanced merging for speech recognition
Sep 30, 2022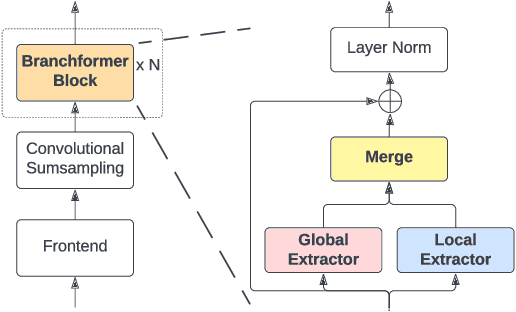
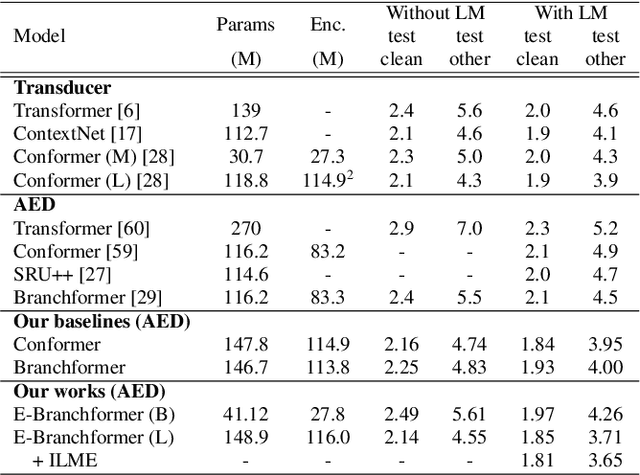
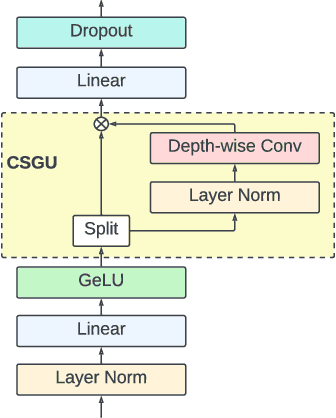
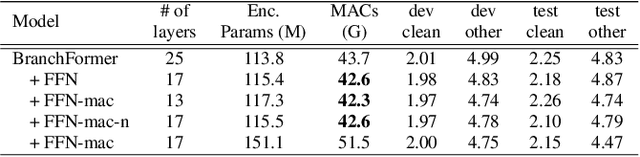
Conformer, combining convolution and self-attention sequentially to capture both local and global information, has shown remarkable performance and is currently regarded as the state-of-the-art for automatic speech recognition (ASR). Several other studies have explored integrating convolution and self-attention but they have not managed to match Conformer's performance. The recently introduced Branchformer achieves comparable performance to Conformer by using dedicated branches of convolution and self-attention and merging local and global context from each branch. In this paper, we propose E-Branchformer, which enhances Branchformer by applying an effective merging method and stacking additional point-wise modules. E-Branchformer sets new state-of-the-art word error rates (WERs) 1.81% and 3.65% on LibriSpeech test-clean and test-other sets without using any external training data.
On the Use of External Data for Spoken Named Entity Recognition
Dec 14, 2021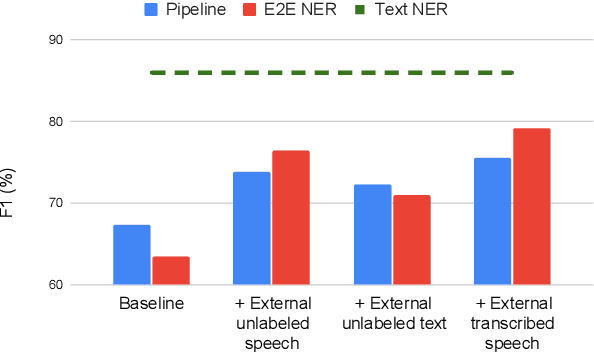

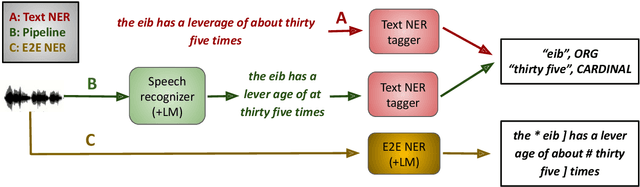
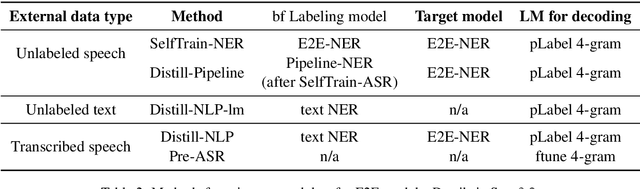
Spoken language understanding (SLU) tasks involve mapping from speech audio signals to semantic labels. Given the complexity of such tasks, good performance might be expected to require large labeled datasets, which are difficult to collect for each new task and domain. However, recent advances in self-supervised speech representations have made it feasible to consider learning SLU models with limited labeled data. In this work we focus on low-resource spoken named entity recognition (NER) and address the question: Beyond self-supervised pre-training, how can we use external speech and/or text data that are not annotated for the task? We draw on a variety of approaches, including self-training, knowledge distillation, and transfer learning, and consider their applicability to both end-to-end models and pipeline (speech recognition followed by text NER model) approaches. We find that several of these approaches improve performance in resource-constrained settings beyond the benefits from pre-trained representations alone. Compared to prior work, we find improved F1 scores of up to 16%. While the best baseline model is a pipeline approach, the best performance when using external data is ultimately achieved by an end-to-end model. We provide detailed comparisons and analyses, showing for example that end-to-end models are able to focus on the more NER-specific words.
SLUE: New Benchmark Tasks for Spoken Language Understanding Evaluation on Natural Speech
Nov 19, 2021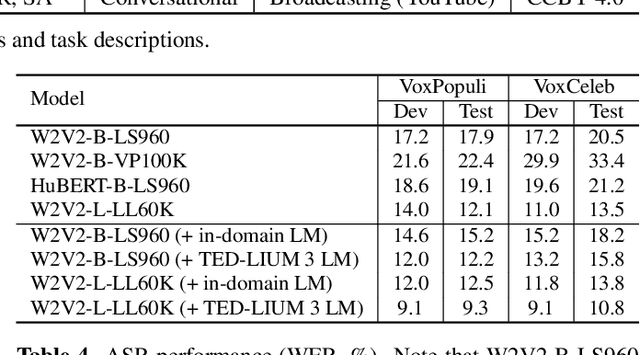
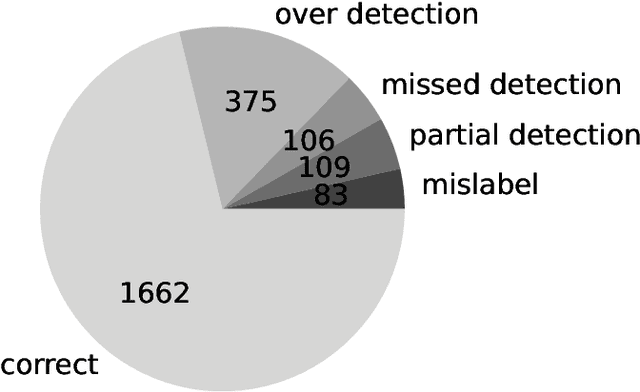
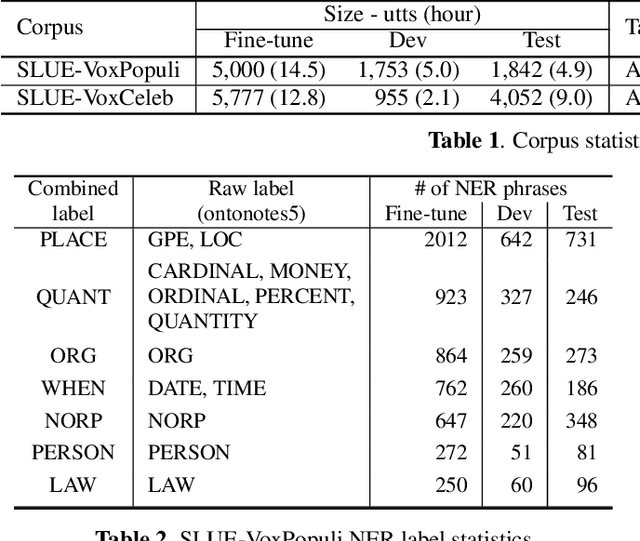
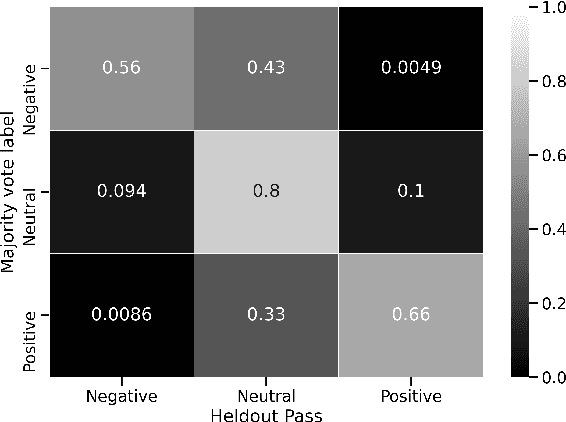
Progress in speech processing has been facilitated by shared datasets and benchmarks. Historically these have focused on automatic speech recognition (ASR), speaker identification, or other lower-level tasks. Interest has been growing in higher-level spoken language understanding tasks, including using end-to-end models, but there are fewer annotated datasets for such tasks. At the same time, recent work shows the possibility of pre-training generic representations and then fine-tuning for several tasks using relatively little labeled data. We propose to create a suite of benchmark tasks for Spoken Language Understanding Evaluation (SLUE) consisting of limited-size labeled training sets and corresponding evaluation sets. This resource would allow the research community to track progress, evaluate pre-trained representations for higher-level tasks, and study open questions such as the utility of pipeline versus end-to-end approaches. We present the first phase of the SLUE benchmark suite, consisting of named entity recognition, sentiment analysis, and ASR on the corresponding datasets. We focus on naturally produced (not read or synthesized) speech, and freely available datasets. We provide new transcriptions and annotations on subsets of the VoxCeleb and VoxPopuli datasets, evaluation metrics and results for baseline models, and an open-source toolkit to reproduce the baselines and evaluate new models.
Multi-mode Transformer Transducer with Stochastic Future Context
Jun 17, 2021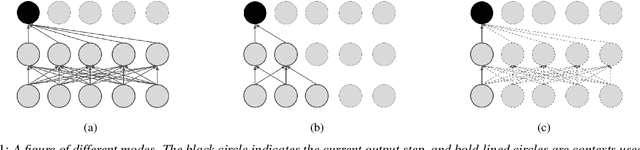
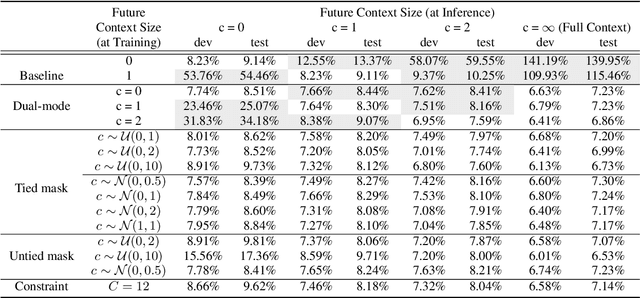
Automatic speech recognition (ASR) models make fewer errors when more surrounding speech information is presented as context. Unfortunately, acquiring a larger future context leads to higher latency. There exists an inevitable trade-off between speed and accuracy. Naively, to fit different latency requirements, people have to store multiple models and pick the best one under the constraints. Instead, a more desirable approach is to have a single model that can dynamically adjust its latency based on different constraints, which we refer to as Multi-mode ASR. A Multi-mode ASR model can fulfill various latency requirements during inference -- when a larger latency becomes acceptable, the model can process longer future context to achieve higher accuracy and when a latency budget is not flexible, the model can be less dependent on future context but still achieve reliable accuracy. In pursuit of Multi-mode ASR, we propose Stochastic Future Context, a simple training procedure that samples one streaming configuration in each iteration. Through extensive experiments on AISHELL-1 and LibriSpeech datasets, we show that a Multi-mode ASR model rivals, if not surpasses, a set of competitive streaming baselines trained with different latency budgets.
Leveraging Pre-trained Language Model for Speech Sentiment Analysis
Jun 11, 2021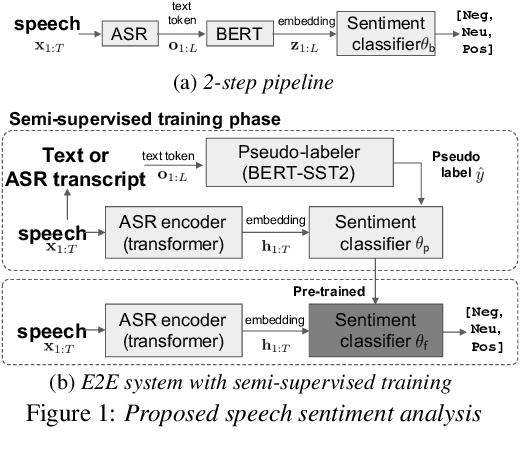
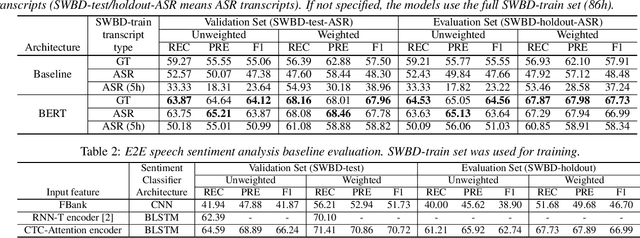
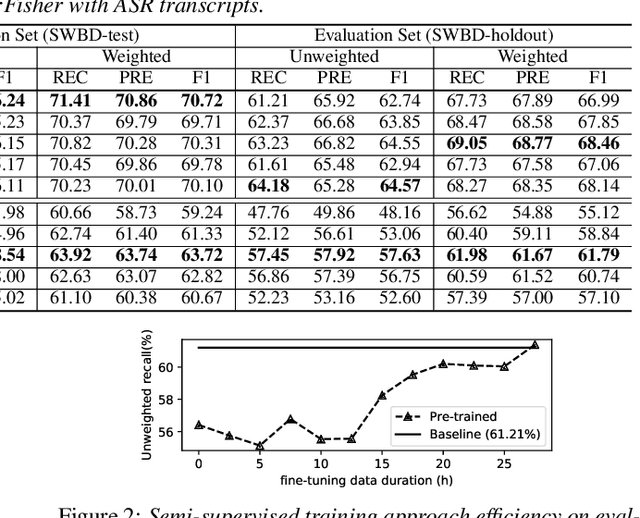
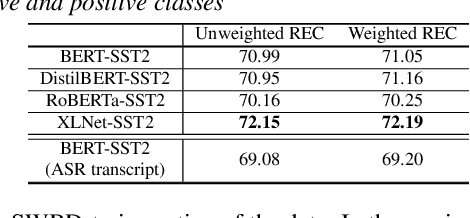
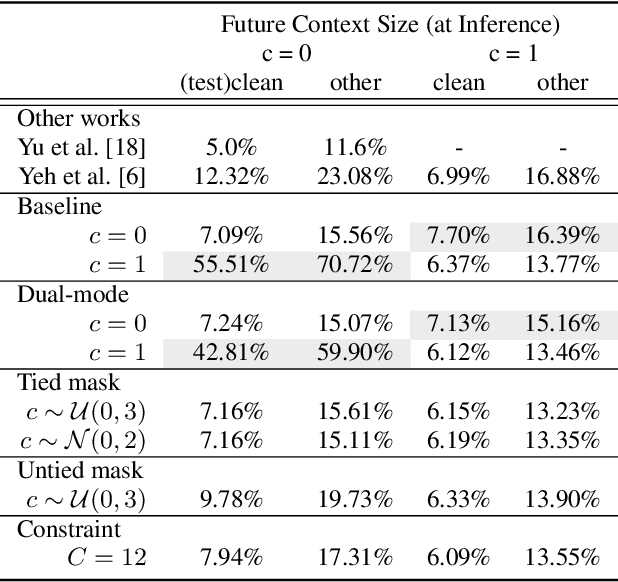
In this paper, we explore the use of pre-trained language models to learn sentiment information of written texts for speech sentiment analysis. First, we investigate how useful a pre-trained language model would be in a 2-step pipeline approach employing Automatic Speech Recognition (ASR) and transcripts-based sentiment analysis separately. Second, we propose a pseudo label-based semi-supervised training strategy using a language model on an end-to-end speech sentiment approach to take advantage of a large, but unlabeled speech dataset for training. Although spoken and written texts have different linguistic characteristics, they can complement each other in understanding sentiment. Therefore, the proposed system can not only model acoustic characteristics to bear sentiment-specific information in speech signals, but learn latent information to carry sentiments in the text representation. In these experiments, we demonstrate the proposed approaches improve F1 scores consistently compared to systems without a language model. Moreover, we also show that the proposed framework can reduce 65% of human supervision by leveraging a large amount of data without human sentiment annotation and boost performance in a low-resource condition where the human sentiment annotation is not available enough.
A Review of Speaker Diarization: Recent Advances with Deep Learning
Jan 24, 2021
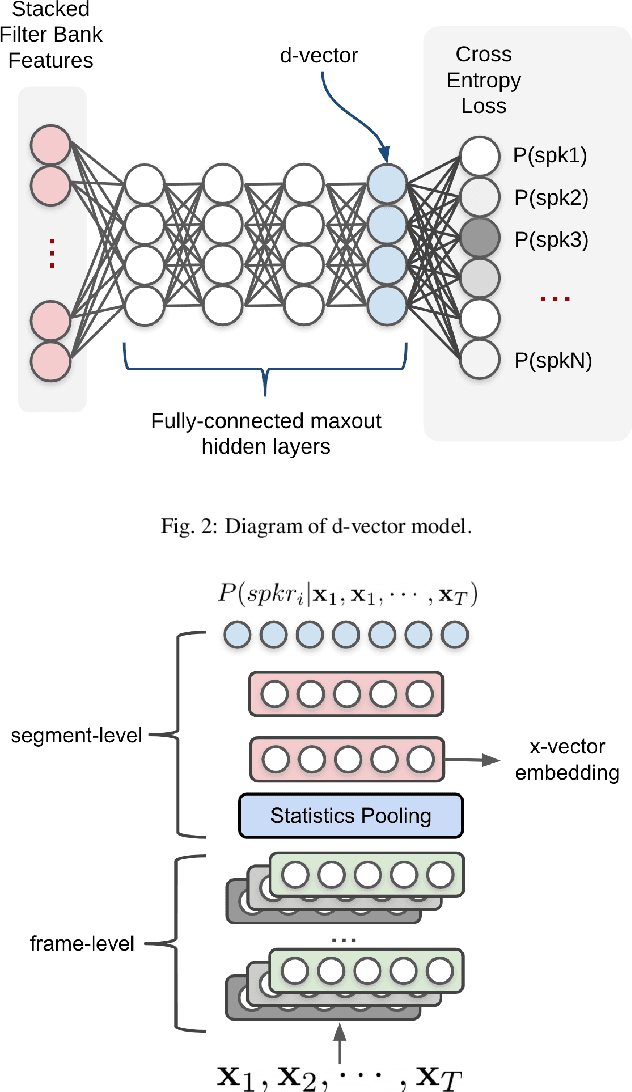
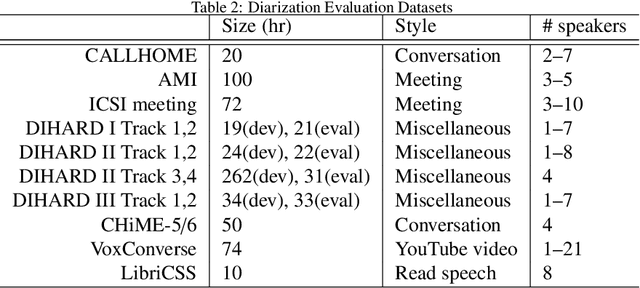
Speaker diarization is a task to label audio or video recordings with classes corresponding to speaker identity, or in short, a task to identify "who spoke when". In the early years, speaker diarization algorithms were developed for speech recognition on multi-speaker audio recordings to enable speaker adaptive processing, but also gained its own value as a stand-alone application over time to provide speaker-specific meta information for downstream tasks such as audio retrieval. More recently, with the rise of deep learning technology that has been a driving force to revolutionary changes in research and practices across speech application domains in the past decade, more rapid advancements have been made for speaker diarization. In this paper, we review not only the historical development of speaker diarization technology but also the recent advancements in neural speaker diarization approaches. We also discuss how speaker diarization systems have been integrated with speech recognition applications and how the recent surge of deep learning is leading the way of jointly modeling these two components to be complementary to each other. By considering such exciting technical trends, we believe that it is a valuable contribution to the community to provide a survey work by consolidating the recent developments with neural methods and thus facilitating further progress towards a more efficient speaker diarization.
Multistream CNN for Robust Acoustic Modeling
May 21, 2020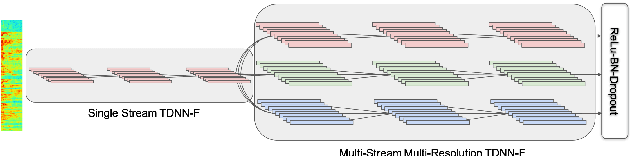
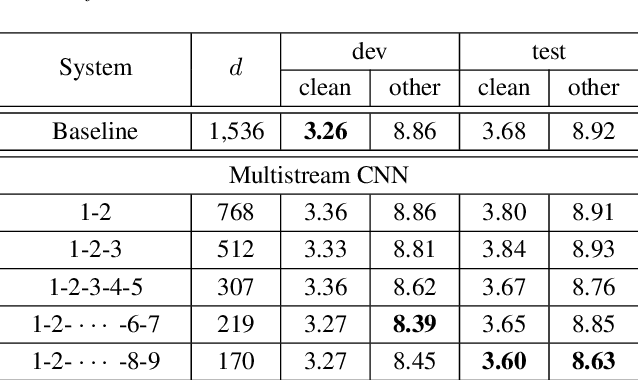
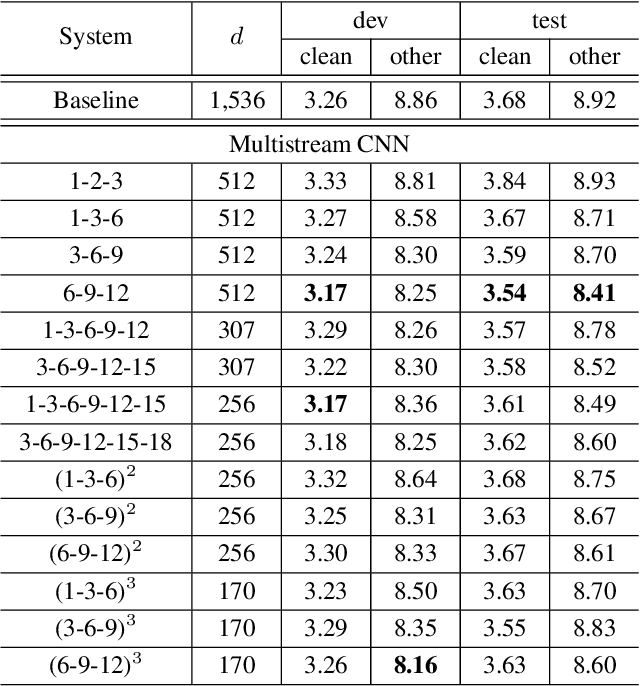
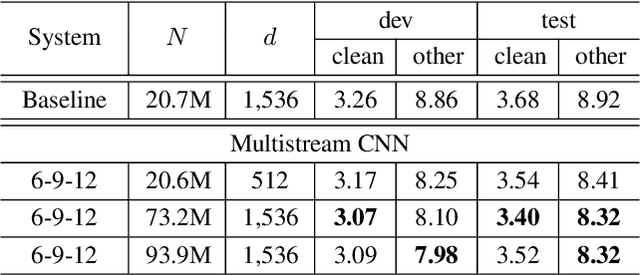
This paper presents multistream CNN, a novel neural network architecture for robust acoustic modeling in speech recognition tasks. The proposed architecture accommodates diverse temporal resolutions in multiple streams to achieve robustness in acoustic modeling. For the diversity of temporal resolution in embedding processing, we consider dilation on TDNN-F, a variant of 1D-CNN. Each stream stacks narrower TDNN-F layers whose kernel has a unique, stream-specific dilation rate when processing input speech frames in parallel. Hence it can better represent acoustic events without the increase of model complexity. We validate the effectiveness of the proposed multistream CNN architecture by showing consistent improvement across various data sets. Trained with data augmentation methods, multistream CNN improves the WER of the test-other set in the LibriSpeech corpus by 12% (relative). On custom data from ASAPP's production system for a contact center, it records a relative WER improvement of 11% for the customer channel audios (10% on average for the agent and customer channel recordings) to prove the superiority of the proposed model architecture in the wild. In terms of real-time factor (RTF), multistream CNN outperforms the normal TDNN-F by 15%, which also suggests its practicality on production systems or applications.