 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscreteSLU: A Large Language Model with Self-Supervised Discrete Speech Units for Spoken Language Understanding
Jun 13, 2024



The integration of pre-trained text-based large language models (LLM) with speech input has enabled instruction-following capabilities for diverse speech tasks. This integration requires the use of a speech encoder, a speech adapter, and an LLM, trained on diverse tasks. We propose the use of discrete speech units (DSU), rather than continuous-valued speech encoder outputs, that are converted to the LLM token embedding space using the speech adapter. We generate DSU using a self-supervised speech encoder followed by k-means clustering. The proposed model shows robust performance on speech inputs from seen/unseen domains and instruction-following capability in spoken question answering. We also explore various types of DSU extracted from different layers of the self-supervised speech encoder, as well as Mel frequency Cepstral Coefficients (MFCC). Our findings suggest that the ASR task and datasets are not crucial in instruction-tuning for spoken question answering tasks.
Improving ASR Contextual Biasing with Guided Attention
Jan 16, 2024



In this paper, we propose a Guided Attention (GA) auxiliary training loss, which improves the effectiveness and robustness of automatic speech recognition (ASR) contextual biasing without introducing additional parameters. A common challenge in previous literature is that the word error rate (WER) reduction brought by contextual biasing diminishes as the number of bias phrases increases. To address this challenge, we employ a GA loss as an additional training objective besides the Transducer loss. The proposed GA loss aims to teach the cross attention how to align bias phrases with text tokens or audio frames. Compared to studies with similar motivations, the proposed loss operates directly on the cross attention weights and is easier to implement. Through extensive experiments based on Conformer Transducer with Contextual Adapter, we demonstrate that the proposed method not only leads to a lower WER but also retains its effectiveness as the number of bias phrases increases. Specifically, the GA loss decreases the WER of rare vocabularies by up to 19.2% on LibriSpeech compared to the contextual biasing baseline, and up to 49.3% compared to a vanilla Transducer.
Generative Context-aware Fine-tuning of Self-supervised Speech Models
Dec 15, 2023



When performing tasks like automatic speech recognition or spoken language understanding for a given utterance, access to preceding text or audio provides contextual information can improve performance. Considering the recent advances in generative large language models (LLM), we hypothesize that an LLM could generate useful context information using the preceding text. With appropriate prompts, LLM could generate a prediction of the next sentence or abstractive text like titles or topics. In this paper, we study the use of LLM-generated context information and propose an approach to distill the generated information during fine-tuning of self-supervised speech models, which we refer to as generative context-aware fine-tuning. This approach allows the fine-tuned model to make improved predictions without access to the true surrounding segments or to the LLM at inference time, while requiring only a very small additional context module. We evaluate the proposed approach using the SLUE and Libri-light benchmarks for several downstream tasks: automatic speech recognition, named entity recognition, and sentiment analysis. The results show that generative context-aware fine-tuning outperforms a context injection fine-tuning approach that accesses the ground-truth previous text, and is competitive with a generative context injection fine-tuning approach that requires the LLM at inference time.
A Comparative Study on E-Branchformer vs Conformer in Speech Recognition, Translation, and Understanding Tasks
May 18, 2023



Conformer, a convolution-augmented Transformer variant, has become the de facto encoder architecture for speech processing due to its superior performance in various tasks, including automatic speech recognition (ASR), speech translation (ST) and spoken language understanding (SLU). Recently, a new encoder called E-Branchformer has outperformed Conformer in the LibriSpeech ASR benchmark, making it promising for more general speech applications. This work compares E-Branchformer and Conformer through extensive experiments using different types of end-to-end sequence-to-sequence models. Results demonstrate that E-Branchformer achieves comparable or better performance than Conformer in almost all evaluation sets across 15 ASR, 2 ST, and 3 SLU benchmarks, while being more stable during training. We will release our training configurations and pre-trained models for reproducibility, which can benefit the speech community.
Structured Pruning of Self-Supervised Pre-trained Models for Speech Recognition and Understanding
Feb 27, 2023



Self-supervised speech representation learning (SSL) has shown to be effective in various downstream tasks, but SSL models are usually large and slow. Model compression techniques such as pruning aim to reduce the model size and computation without degradation in accuracy. Prior studies focus on the pruning of Transformers; however, speech models not only utilize a stack of Transformer blocks, but also combine a frontend network based on multiple convolutional layers for low-level feature representation learning. This frontend has a small size but a heavy computational cost. In this work, we propose three task-specific structured pruning methods to deal with such heterogeneous networks. Experiments on LibriSpeech and SLURP show that the proposed method is more accurate than the original wav2vec2-base with 10% to 30% less computation, and is able to reduce the computation by 40% to 50% without any degradation.
Context-aware Fine-tuning of Self-supervised Speech Models
Dec 16, 2022



Self-supervised pre-trained transformers have improved the state of the art on a variety of speech tasks. Due to the quadratic time and space complexity of self-attention, they usually operate at the level of relatively short (e.g., utterance) segments. In this paper, we study the use of context, i.e., surrounding segments, during fine-tuning and propose a new approach called context-aware fine-tuning. We attach a context module on top of the last layer of a pre-trained model to encode the whole segment into a context embedding vector which is then used as an additional feature for the final prediction. During the fine-tuning stage, we introduce an auxiliary loss that encourages this context embedding vector to be similar to context vectors of surrounding segments. This allows the model to make predictions without access to these surrounding segments at inference time and requires only a tiny overhead compared to standard fine-tuned models. We evaluate the proposed approach using the SLUE and Librilight benchmarks for several downstream tasks: Automatic speech recognition (ASR), named entity recognition (NER), and sentiment analysis (SA). The results show that context-aware fine-tuning not only outperforms a standard fine-tuning baseline but also rivals a strong context injection baseline that uses neighboring speech segments during inference.
E-Branchformer: Branchformer with Enhanced merging for speech recognition
Sep 30, 2022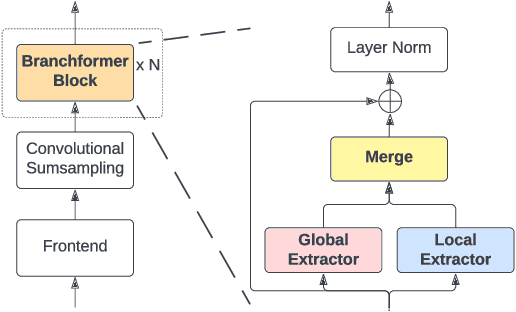
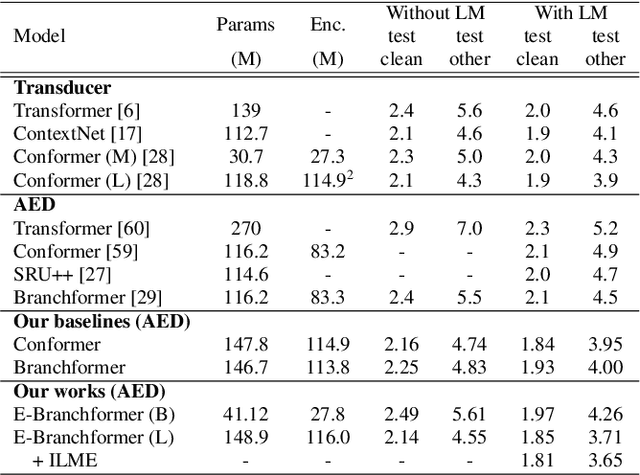
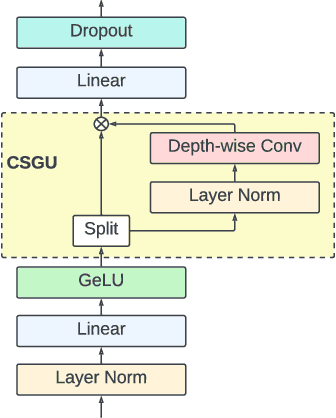
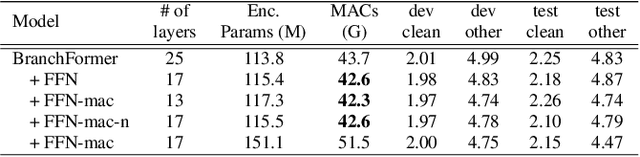
Conformer, combining convolution and self-attention sequentially to capture both local and global information, has shown remarkable performance and is currently regarded as the state-of-the-art for automatic speech recognition (ASR). Several other studies have explored integrating convolution and self-attention but they have not managed to match Conformer's performance. The recently introduced Branchformer achieves comparable performance to Conformer by using dedicated branches of convolution and self-attention and merging local and global context from each branch. In this paper, we propose E-Branchformer, which enhances Branchformer by applying an effective merging method and stacking additional point-wise modules. E-Branchformer sets new state-of-the-art word error rates (WERs) 1.81% and 3.65% on LibriSpeech test-clean and test-other sets without using any external training data.
Multi-mode Transformer Transducer with Stochastic Future Context
Jun 17, 2021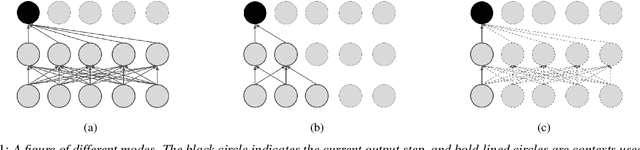
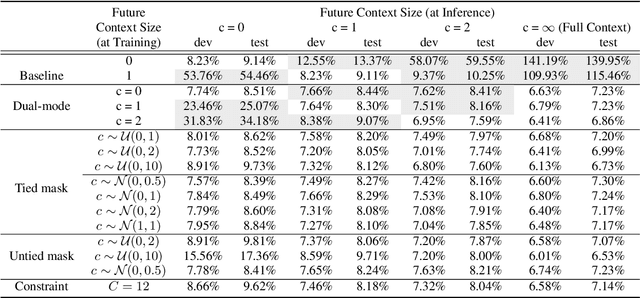
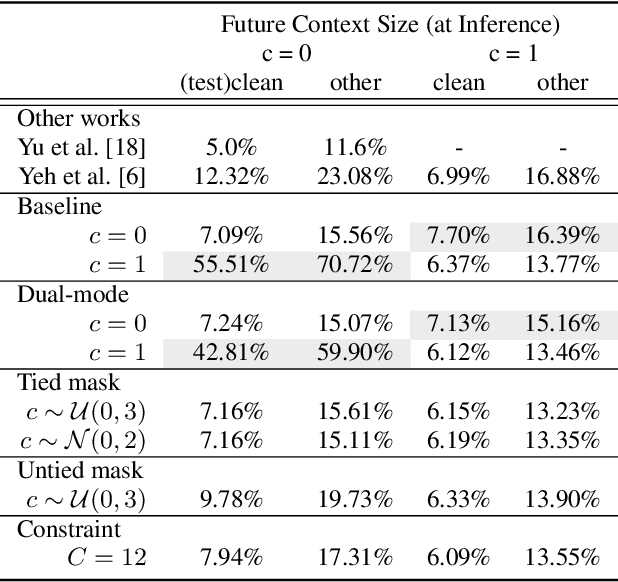
Automatic speech recognition (ASR) models make fewer errors when more surrounding speech information is presented as context. Unfortunately, acquiring a larger future context leads to higher latency. There exists an inevitable trade-off between speed and accuracy. Naively, to fit different latency requirements, people have to store multiple models and pick the best one under the constraints. Instead, a more desirable approach is to have a single model that can dynamically adjust its latency based on different constraints, which we refer to as Multi-mode ASR. A Multi-mode ASR model can fulfill various latency requirements during inference -- when a larger latency becomes acceptable, the model can process longer future context to achieve higher accuracy and when a latency budget is not flexible, the model can be less dependent on future context but still achieve reliable accuracy. In pursuit of Multi-mode ASR, we propose Stochastic Future Context, a simple training procedure that samples one streaming configuration in each iteration. Through extensive experiments on AISHELL-1 and LibriSpeech datasets, we show that a Multi-mode ASR model rivals, if not surpasses, a set of competitive streaming baselines trained with different latency budgets.
Tuplemax Loss for Language Identification
Nov 29, 2018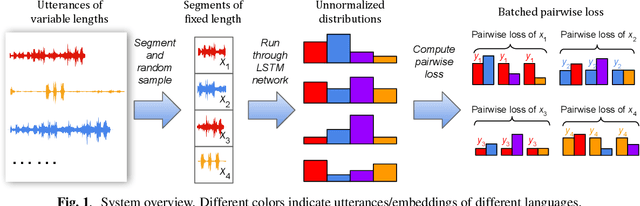

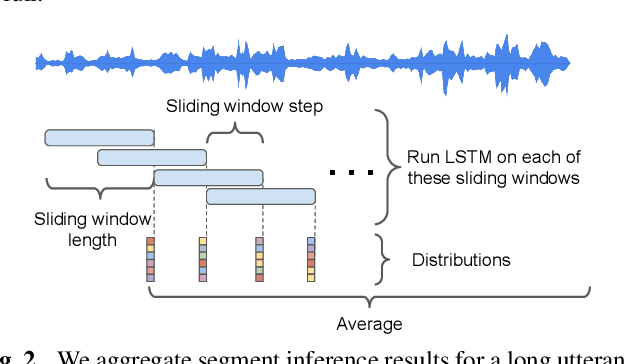
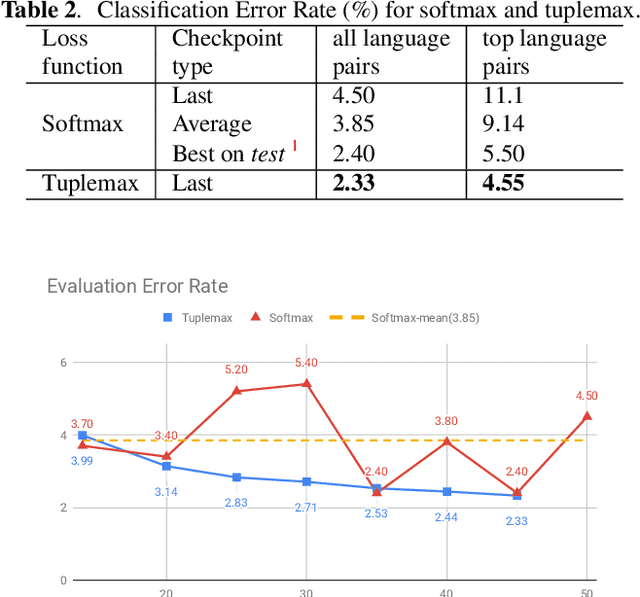
In many scenarios of a language identification task, the user will specify a small set of languages which he/she can speak instead of a large set of all possible languages. We want to model such prior knowledge into the way we train our neural networks, by replacing the commonly used softmax loss function with a novel loss function named tuplemax loss. As a matter of fact, a typical language identification system launched in North America has about 95% users who could speak no more than two languages. Using the tuplemax loss, our system achieved a 2.33% error rate, which is a relative 39.4% improvement over the 3.85% error rate of standard softmax loss method.
VoiceFilter: Targeted Voice Separation by Speaker-Conditioned Spectrogram Masking
Oct 27, 2018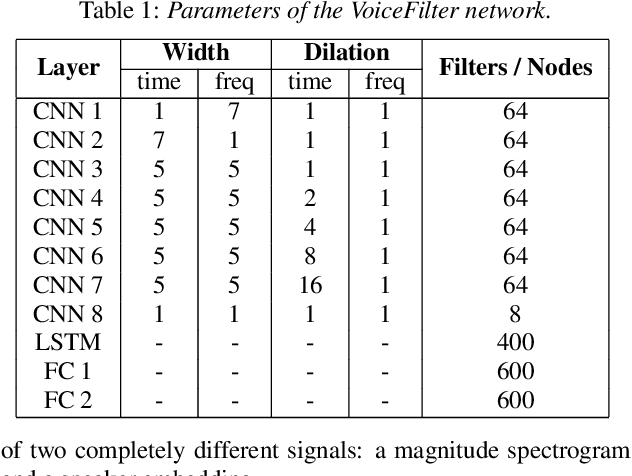
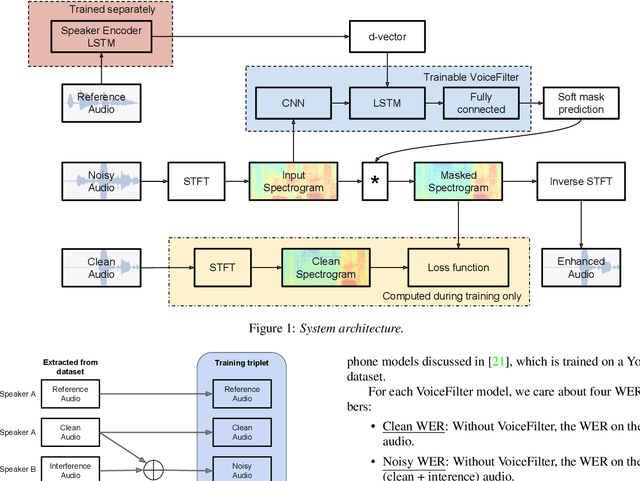
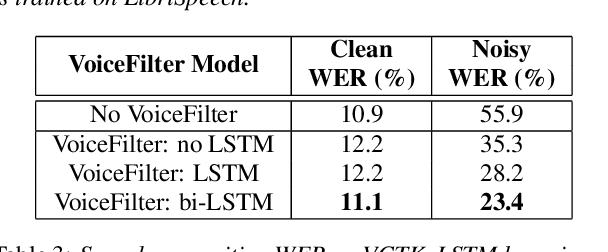
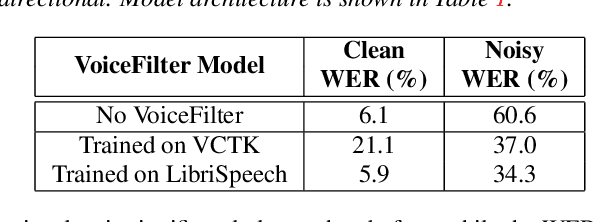
In this paper, we present a novel system that separates the voice of a target speaker from multi-speaker signals, by making use of a reference signal from the target speaker. We achieve this by training two separate neural networks: (1) A speaker recognition network that produces speaker-discriminative embeddings; (2) A spectrogram masking network that takes both noisy spectrogram and speaker embedding as input, and produces a mask. Our system significantly reduces the speech recognition WER on multi-speaker signals, with minimal WER degradation on single-speaker signals.