 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePay Attention to CTC: Fast and Robust Pseudo-Labelling for Unified Speech Recognition
Feb 22, 2026Unified Speech Recognition (USR) has emerged as a semi-supervised framework for training a single model for audio, visual, and audiovisual speech recognition, achieving state-of-the-art results on in-distribution benchmarks. However, its reliance on autoregressive pseudo-labelling makes training expensive, while its decoupled supervision of CTC and attention branches increases susceptibility to self-reinforcing errors, particularly under distribution shifts involving longer sequences, noise, or unseen domains. We propose CTC-driven teacher forcing, where greedily decoded CTC pseudo-labels are fed into the decoder to generate attention targets in a single forward pass. Although these can be globally incoherent, in the pseudo-labelling setting they enable efficient and effective knowledge transfer. Because CTC and CTC-driven attention pseudo-labels have the same length, the decoder can predict both simultaneously, benefiting from the robustness of CTC and the expressiveness of attention without costly beam search. We further propose mixed sampling to mitigate the exposure bias of the decoder relying solely on CTC inputs. The resulting method, USR 2.0, halves training time, improves robustness to out-of-distribution inputs, and achieves state-of-the-art results on LRS3, LRS2, and WildVSR, surpassing USR and modality-specific self-supervised baselines.
Unified Speech Recognition: A Single Model for Auditory, Visual, and Audiovisual Inputs
Nov 04, 2024



Research in auditory, visual, and audiovisual speech recognition (ASR, VSR, and AVSR, respectively) has traditionally been conducted independently. Even recent self-supervised studies addressing two or all three tasks simultaneously tend to yield separate models, leading to disjoint inference pipelines with increased memory requirements and redundancies. This paper proposes unified training strategies for these systems. We demonstrate that training a single model for all three tasks enhances VSR and AVSR performance, overcoming typical optimisation challenges when training from scratch. Moreover, we introduce a greedy pseudo-labelling approach to more effectively leverage unlabelled samples, addressing shortcomings in related self-supervised methods. Finally, we develop a self-supervised pre-training method within our framework, proving its effectiveness alongside our semi-supervised approach. Despite using a single model for all tasks, our unified approach achieves state-of-the-art performance compared to recent methods on LRS3 and LRS2 for ASR, VSR, and AVSR, as well as on the newly released WildVSR dataset. Code and models are available at https://github.com/ahaliassos/usr.
BRAVEn: Improving Self-Supervised Pre-training for Visual and Auditory Speech Recognition
Apr 02, 2024Self-supervision has recently shown great promise for learning visual and auditory speech representations from unlabelled data. In this work, we propose BRAVEn, an extension to the recent RAVEn method, which learns speech representations entirely from raw audio-visual data. Our modifications to RAVEn enable BRAVEn to achieve state-of-the-art results among self-supervised methods in various settings. Moreover, we observe favourable scaling behaviour by increasing the amount of unlabelled data well beyond other self-supervised works. In particular, we achieve 20.0% / 1.7% word error rate for VSR / ASR on the LRS3 test set, with only 30 hours of labelled data and no external ASR models. Our results suggest that readily available unlabelled audio-visual data can largely replace costly transcribed data.
SparseVSR: Lightweight and Noise Robust Visual Speech Recognition
Jul 10, 2023



Recent advances in deep neural networks have achieved unprecedented success in visual speech recognition. However, there remains substantial disparity between current methods and their deployment in resource-constrained devices. In this work, we explore different magnitude-based pruning techniques to generate a lightweight model that achieves higher performance than its dense model equivalent, especially under the presence of visual noise. Our sparse models achieve state-of-the-art results at 10% sparsity on the LRS3 dataset and outperform the dense equivalent up to 70% sparsity. We evaluate our 50% sparse model on 7 different visual noise types and achieve an overall absolute improvement of more than 2% WER compared to the dense equivalent. Our results confirm that sparse networks are more resistant to noise than dense networks.
Auto-AVSR: Audio-Visual Speech Recognition with Automatic Labels
Mar 25, 2023



Audio-visual speech recognition has received a lot of attention due to its robustness against acoustic noise. Recently, the performance of automatic, visual, and audio-visual speech recognition (ASR, VSR, and AV-ASR, respectively) has been substantially improved, mainly due to the use of larger models and training sets. However, accurate labelling of datasets is time-consuming and expensive. Hence, in this work, we investigate the use of automatically-generated transcriptions of unlabelled datasets to increase the training set size. For this purpose, we use publicly-available pre-trained ASR models to automatically transcribe unlabelled datasets such as AVSpeech and VoxCeleb2. Then, we train ASR, VSR and AV-ASR models on the augmented training set, which consists of the LRS2 and LRS3 datasets as well as the additional automatically-transcribed data. We demonstrate that increasing the size of the training set, a recent trend in the literature, leads to reduced WER despite using noisy transcriptions. The proposed model achieves new state-of-the-art performance on AV-ASR on LRS2 and LRS3. In particular, it achieves a WER of 0.9% on LRS3, a relative improvement of 30% over the current state-of-the-art approach, and outperforms methods that have been trained on non-publicly available datasets with 26 times more training data.
Learning Cross-lingual Visual Speech Representations
Mar 14, 2023



Cross-lingual self-supervised learning has been a growing research topic in the last few years. However, current works only explored the use of audio signals to create representations. In this work, we study cross-lingual self-supervised visual representation learning. We use the recently-proposed Raw Audio-Visual Speech Encoders (RAVEn) framework to pre-train an audio-visual model with unlabelled multilingual data, and then fine-tune the visual model on labelled transcriptions. Our experiments show that: (1) multi-lingual models with more data outperform monolingual ones, but, when keeping the amount of data fixed, monolingual models tend to reach better performance; (2) multi-lingual outperforms English-only pre-training; (3) using languages which are more similar yields better results; and (4) fine-tuning on unseen languages is competitive to using the target language in the pre-training set. We hope our study inspires future research on non-English-only speech representation learning.
Jointly Learning Visual and Auditory Speech Representations from Raw Data
Dec 12, 2022We present RAVEn, a self-supervised multi-modal approach to jointly learn visual and auditory speech representations. Our pre-training objective involves encoding masked inputs, and then predicting contextualised targets generated by slowly-evolving momentum encoders. Driven by the inherent differences between video and audio, our design is asymmetric w.r.t. the two modalities' pretext tasks: Whereas the auditory stream predicts both the visual and auditory targets, the visual one predicts only the auditory targets. We observe strong results in low- and high-resource labelled data settings when fine-tuning the visual and auditory encoders resulting from a single pre-training stage, in which the encoders are jointly trained. Notably, RAVEn surpasses all self-supervised methods on visual speech recognition (VSR) on LRS3, and combining RAVEn with self-training using only 30 hours of labelled data even outperforms a recent semi-supervised method trained on 90,000 hours of non-public data. At the same time, we achieve state-of-the-art results in the LRS3 low-resource setting for auditory speech recognition (as well as for VSR). Our findings point to the viability of learning powerful speech representations entirely from raw video and audio, i.e., without relying on handcrafted features. Code and models will be made public.
SVTS: Scalable Video-to-Speech Synthesis
May 04, 2022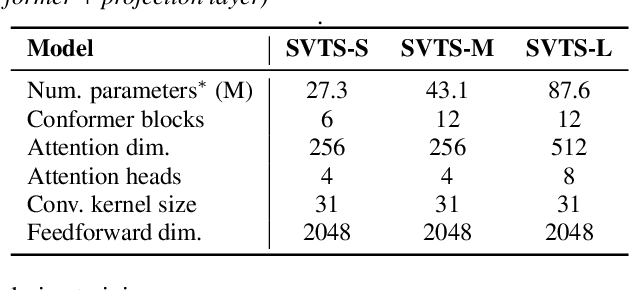
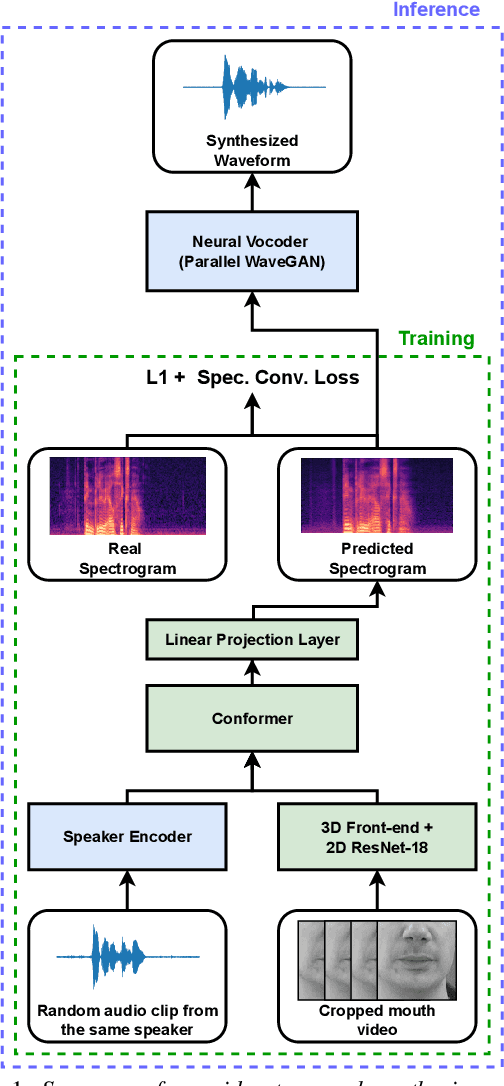
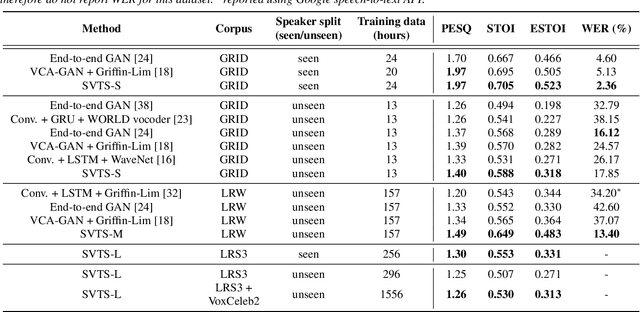
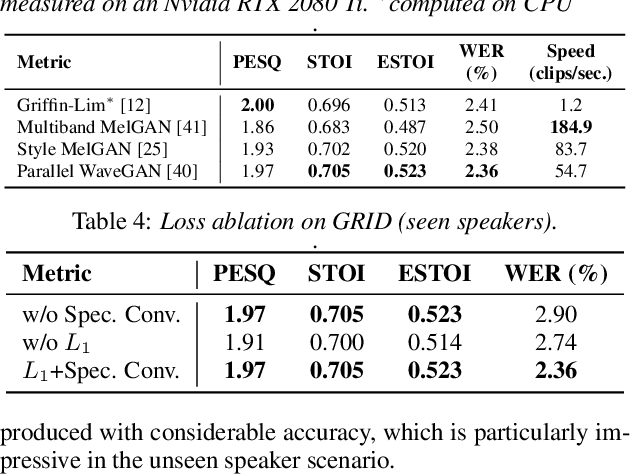
Video-to-speech synthesis (also known as lip-to-speech) refers to the translation of silent lip movements into the corresponding audio. This task has received an increasing amount of attention due to its self-supervised nature (i.e., can be trained without manual labelling) combined with the ever-growing collection of audio-visual data available online. Despite these strong motivations, contemporary video-to-speech works focus mainly on small- to medium-sized corpora with substantial constraints in both vocabulary and setting. In this work, we introduce a scalable video-to-speech framework consisting of two components: a video-to-spectrogram predictor and a pre-trained neural vocoder, which converts the mel-frequency spectrograms into waveform audio. We achieve state-of-the art results for GRID and considerably outperform previous approaches on LRW. More importantly, by focusing on spectrogram prediction using a simple feedforward model, we can efficiently and effectively scale our method to very large and unconstrained datasets: To the best of our knowledge, we are the first to show intelligible results on the challenging LRS3 dataset.
Leveraging Real Talking Faces via Self-Supervision for Robust Forgery Detection
Jan 18, 2022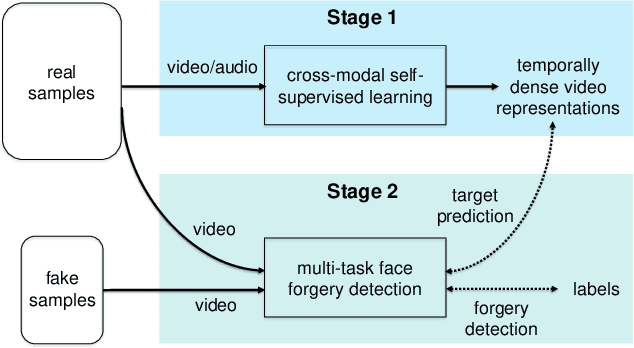
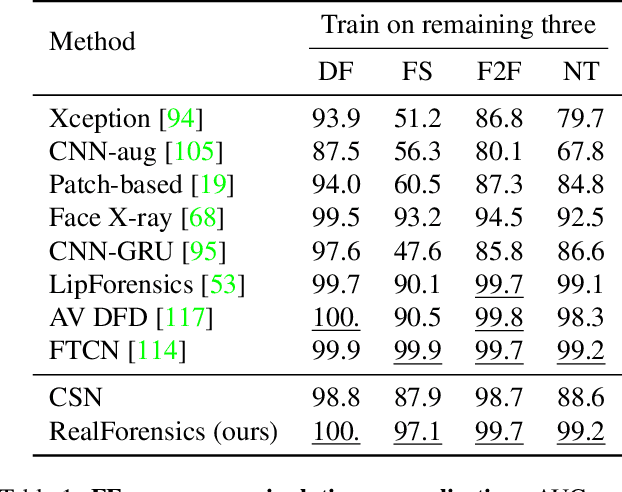

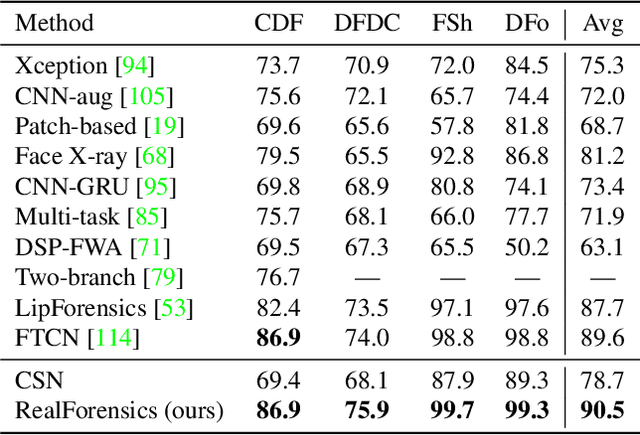
One of the most pressing challenges for the detection of face-manipulated videos is generalising to forgery methods not seen during training while remaining effective under common corruptions such as compression. In this paper, we question whether we can tackle this issue by harnessing videos of real talking faces, which contain rich information on natural facial appearance and behaviour and are readily available in large quantities online. Our method, termed RealForensics, consists of two stages. First, we exploit the natural correspondence between the visual and auditory modalities in real videos to learn, in a self-supervised cross-modal manner, temporally dense video representations that capture factors such as facial movements, expression, and identity. Second, we use these learned representations as targets to be predicted by our forgery detector along with the usual binary forgery classification task; this encourages it to base its real/fake decision on said factors. We show that our method achieves state-of-the-art performance on cross-manipulation generalisation and robustness experiments, and examine the factors that contribute to its performance. Our results suggest that leveraging natural and unlabelled videos is a promising direction for the development of more robust face forgery detectors.
Lips Don't Lie: A Generalisable and Robust Approach to Face Forgery Detection
Dec 14, 2020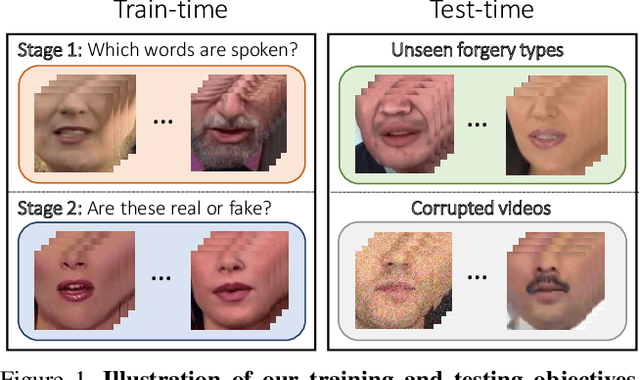
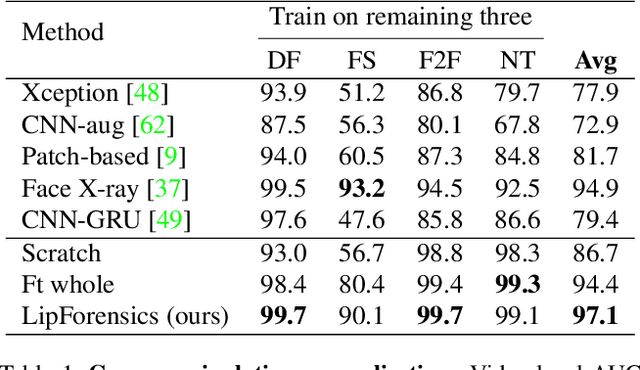
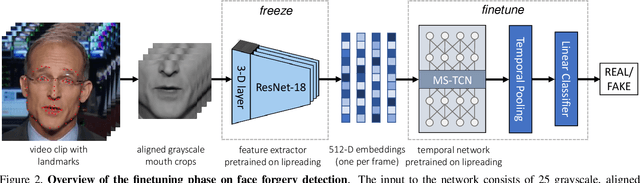
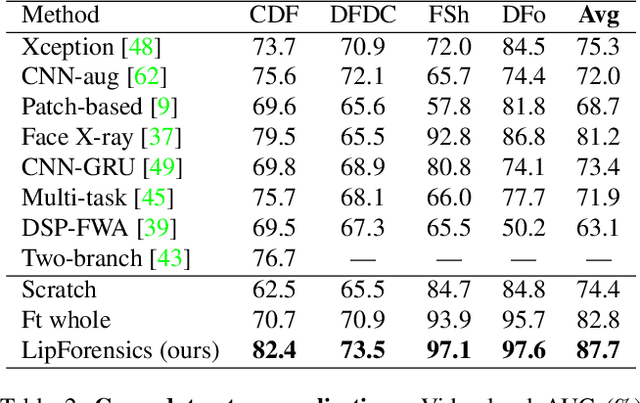
Although current deep learning-based face forgery detectors achieve impressive performance in constrained scenarios, they are vulnerable to samples created by unseen manipulation methods. Some recent works show improvements in generalisation but rely on cues that are easily corrupted by common post-processing operations such as compression. In this paper, we propose LipForensics, a detection approach capable of both generalising to novel manipulations and withstanding various distortions. LipForensics targets high-level semantic irregularities in mouth movements, which are common in many generated videos. It consists in first pretraining a spatio-temporal network to perform visual speech recognition (lipreading), thus learning rich internal representations related to natural mouth motion. A temporal network is subsequently finetuned on fixed mouth embeddings of real and forged data in order to detect fake videos based on mouth movements without overfitting to low-level, manipulation-specific artefacts. Extensive experiments show that this simple approach significantly surpasses the state-of-the-art in terms of generalisation to unseen manipulations and robustness to perturbations, as well as shed light on the factors responsible for its performance.