 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning Elicits Contextual Learning of Unseen Language Translation
Jun 04, 2026Prior work has shown that large language models (LLMs) can translate unseen or low-resource languages by undergoing continued training or even by encoding a grammar book in their context. However, both methods typically overfit specific languages, with limited zero-shot transfer at test time. To translate extremely low-resource languages at scale, we argue that LLMs must acquire the meta-skill of utilizing in-context linguistic knowledge rather than memorizing specific languages. In this paper, we propose a reinforcement learning (RL) approach to unseen language translation given rich linguistic context, using a surface-level translation metric (chrF) as the reward. Empirically, despite the lightweight reward, our RL-trained models effectively extract and apply relevant linguistic information from the provided context, leading to better translations on completely unseen languages than in-context learning or supervised fine-tuning. Our analyses suggest that outcome-based RL can extend beyond conventional reasoning tasks like math and coding to serve as a recipe for language learning from context.
Attention Calibration for Position-Fair Dense Information Retrieval
Jun 01, 2026Dense retrieval models exhibit positional bias: retrieval effectiveness degrades when relevant information appears later in a passage (Zeng et al., 2025). We ask whether this bias can be reduced at inference time, without retraining and without sacrificing overall retrieval effectiveness. To this end, we adapt inference-time attention calibration (Schuhmacher et al., 2026) to downstream retrieval and extend it with a strength coefficient lambda that interpolates between the original and fully calibrated attention distributions. Across three embedding models on SQuAD-PosQ and FineWeb-PosQ, we examine how basket size, calibrated layer set, and strength affect the trade-off between positional fairness and retrieval effectiveness, finding that partial calibration frequently outperforms full calibration. A single configuration (B=128, lambda=0.5, 50% layer depth) improves the harmonic mean of nDCG@10 across positional groups on FineWeb-PosQ for all three models without per-model tuning, and applies to both <s>-pooled and last-token-pooled architectures. This default configuration transfers without modification to PosIR, which spans 10 languages and 31 domains, reducing the Position Sensitivity Index in all 16 length-quartile x model x retrieval-setting combinations, while preserving or improving aggregate nDCG@10. We release our extended codebase at https://github.com/impresso/fair-sentence-transformers
CommonMorph: Participatory Morphological Documentation Platform
Apr 06, 2026Collecting and annotating morphological data present significant challenges, requiring linguistic expertise, methodological rigour, and substantial resources. These barriers are particularly acute for low-resource languages and varieties. To accelerate this process, we introduce \texttt{CommonMorph}, a comprehensive platform that streamlines morphological data collection development through a three-tiered approach: expert linguistic definition, contributor elicitation, and community validation. The platform minimises manual work by incorporating active learning, annotation suggestions, and tools to import and adapt materials from related languages. It accommodates diverse morphological systems, including fusional, agglutinative, and root-and-pattern morphologies. Its open-source design and UniMorph-compatible outputs ensure accessibility and interoperability with NLP tools. Our platform is accessible at https://common-morph.com, offering a replicable model for preserving linguistic diversity through collaborative technology.
Translation Asymmetry in LLMs as a Data Augmentation Factor: A Case Study for 6 Romansh Language Varieties
Mar 26, 2026Recent strategies for low-resource machine translation rely on LLMs to generate synthetic data from higher-resource languages. We find that this method fails for Romansh, because LLMs tend to confuse its 6 distinct language varieties. Our experiments show that instead, the direction of data augmentation should be aligned with the resource gradient between source and target language. This approach surpasses Gemini 3 Pro in the lowest-resource variety of Romansh by 23 BLEU. A human evaluation confirms that our experiments yield the first model that generates fluent translations in the individual Romansh varieties.
DeReason: A Difficulty-Aware Curriculum Improves Decoupled SFT-then-RL Training for General Reasoning
Mar 11, 2026Reinforcement learning with Verifiable Rewards (RLVR) has emerged as a powerful paradigm for eliciting reasoning capabilities in large language models, particularly in mathematics and coding. While recent efforts have extended this paradigm to broader general scientific (STEM) domains, the complex interplay between supervised fine-tuning (SFT) and RL in these contexts remains underexplored. In this paper, we conduct controlled experiments revealing a critical challenge: for general STEM domains, RL applied directly to base models is highly sample-inefficient and is consistently surpassed by supervised fine-tuning (SFT) on moderate-quality responses. Yet sequential SFT followed by RL can further improve performance, suggesting that the two stages play complementary roles, and that how training data is allocated between them matters. Therefore, we propose DeReason, a difficulty-based data decoupling strategy for general reasoning. DeReason partitions training data by reasoning intensity estimated via LLM-based scoring into reasoning-intensive and non-reasoning-intensive subsets. It allocates broad-coverage, non-reasoning-intensive problems to SFT to establish foundational domain knowledge, and reserves a focused subset of difficult problems for RL to cultivate complex reasoning. We demonstrate that this principled decoupling yields better performance than randomly splitting the data for sequential SFT and RL. Extensive experiments on general STEM and mathematical benchmarks demonstrate that our decoupled curriculum training significantly outperforms SFT-only, RL-only, and random-split baselines. Our work provides a systematic study of the interplay between SFT and RL for general reasoning, offering a highly effective and generalized post-training recipe.
Information Representation Fairness in Long-Document Embeddings: The Peculiar Interaction of Positional and Language Bias
Jan 23, 2026To be discoverable in an embedding-based search process, each part of a document should be reflected in its embedding representation. To quantify any potential reflection biases, we introduce a permutation-based evaluation framework. With this, we observe that state-of-the-art embedding models exhibit systematic positional and language biases when documents are longer and consist of multiple segments. Specifically, early segments and segments in higher-resource languages like English are over-represented, while later segments and segments in lower-resource languages are marginalized. In our further analysis, we find that the positional bias stems from front-loaded attention distributions in pooling-token embeddings, where early tokens receive more attention. To mitigate this issue, we introduce an inference-time attention calibration method that redistributes attention more evenly across document positions, increasing discoverabiltiy of later segments. Our evaluation framework and attention calibration is available at https://github.com/impresso/fair-sentence-transformers
SwissGov-RSD: A Human-annotated, Cross-lingual Benchmark for Token-level Recognition of Semantic Differences Between Related Documents
Dec 08, 2025Recognizing semantic differences across documents, especially in different languages, is crucial for text generation evaluation and multilingual content alignment. However, as a standalone task it has received little attention. We address this by introducing SwissGov-RSD, the first naturalistic, document-level, cross-lingual dataset for semantic difference recognition. It encompasses a total of 224 multi-parallel documents in English-German, English-French, and English-Italian with token-level difference annotations by human annotators. We evaluate a variety of open-source and closed source large language models as well as encoder models across different fine-tuning settings on this new benchmark. Our results show that current automatic approaches perform poorly compared to their performance on monolingual, sentence-level, and synthetic benchmarks, revealing a considerable gap for both LLMs and encoder models. We make our code and datasets publicly available.
Parity-Aware Byte-Pair Encoding: Improving Cross-lingual Fairness in Tokenization
Aug 06, 2025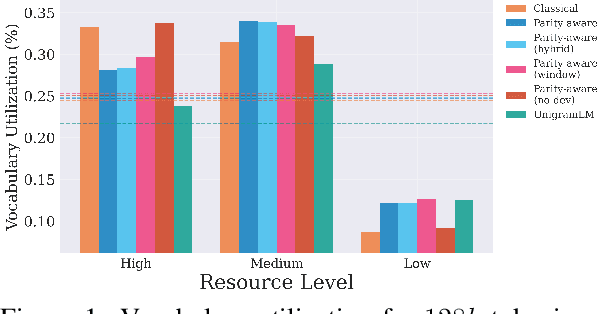
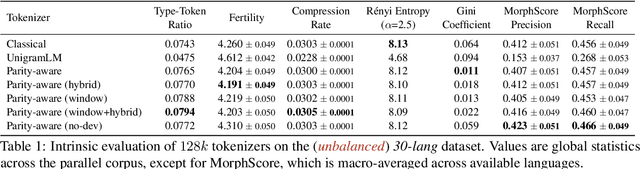
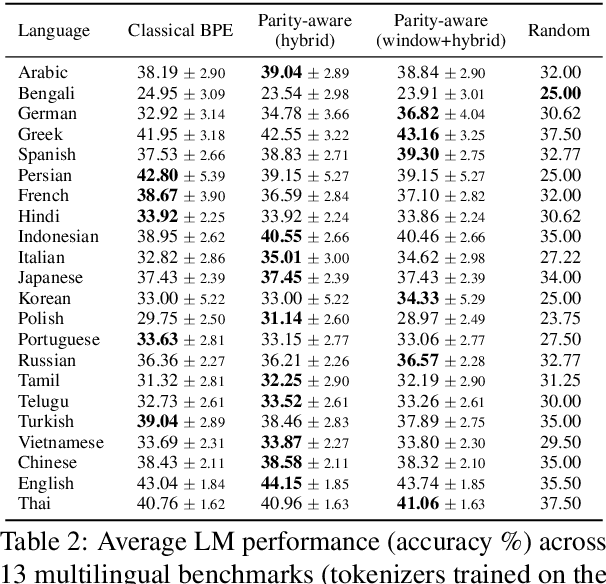
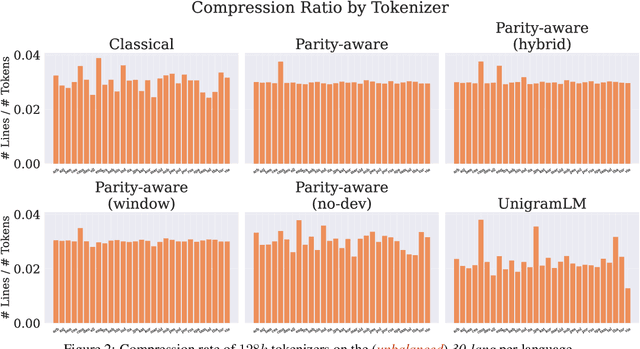
Tokenization is the first -- and often least scrutinized -- step of most NLP pipelines. Standard algorithms for learning tokenizers rely on frequency-based objectives, which favor languages dominant in the training data and consequently leave lower-resource languages with tokenizations that are disproportionately longer, morphologically implausible, or even riddled with <UNK> placeholders. This phenomenon ultimately amplifies computational and financial inequalities between users from different language backgrounds. To remedy this, we introduce Parity-aware Byte Pair Encoding (BPE), a variant of the widely-used BPE algorithm. At every merge step, Parity-aware BPE maximizes the compression gain of the currently worst-compressed language, trading a small amount of global compression for cross-lingual parity. We find empirically that Parity-aware BPE leads to more equitable token counts across languages, with negligible impact on global compression rate and no substantial effect on language-model performance in downstream tasks.
20min-XD: A Comparable Corpus of Swiss News Articles
Apr 30, 2025



We present 20min-XD (20 Minuten cross-lingual document-level), a French-German, document-level comparable corpus of news articles, sourced from the Swiss online news outlet 20 Minuten/20 minutes. Our dataset comprises around 15,000 article pairs spanning 2015 to 2024, automatically aligned based on semantic similarity. We detail the data collection process and alignment methodology. Furthermore, we provide a qualitative and quantitative analysis of the corpus. The resulting dataset exhibits a broad spectrum of cross-lingual similarity, ranging from near-translations to loosely related articles, making it valuable for various NLP applications and broad linguistically motivated studies. We publicly release the dataset in document- and sentence-aligned versions and code for the described experiments.
CHARM: Calibrating Reward Models With Chatbot Arena Scores
Apr 14, 2025Reward models (RMs) play a crucial role in Reinforcement Learning from Human Feedback by serving as proxies for human preferences in aligning large language models. In this paper, we identify a model preference bias in RMs, where they systematically assign disproportionately high scores to responses from certain policy models. This bias distorts ranking evaluations and leads to unfair judgments. To address this issue, we propose a calibration method named CHatbot Arena calibrated Reward Modeling (CHARM) that leverages Elo scores from the Chatbot Arena leaderboard to mitigate RM overvaluation. We also introduce a Mismatch Degree metric to measure this preference bias. Our approach is computationally efficient, requiring only a small preference dataset for continued training of the RM. We conduct extensive experiments on reward model benchmarks and human preference alignment. Results demonstrate that our calibrated RMs (1) achieve improved evaluation accuracy on RM-Bench and the Chat-Hard domain of RewardBench, and (2) exhibit a stronger correlation with human preferences by producing scores more closely aligned with Elo rankings. By mitigating model preference bias, our method provides a generalizable and efficient solution for building fairer and more reliable reward models.