 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
PHI-S: Distribution Balancing for Label-Free Multi-Teacher Distillation
Oct 02, 2024



Various visual foundation models have distinct strengths and weaknesses, both of which can be improved through heterogeneous multi-teacher knowledge distillation without labels, termed "agglomerative models." We build upon this body of work by studying the effect of the teachers' activation statistics, particularly the impact of the loss function on the resulting student model quality. We explore a standard toolkit of statistical normalization techniques to better align the different distributions and assess their effects. Further, we examine the impact on downstream teacher-matching metrics, which motivates the use of Hadamard matrices. With these matrices, we demonstrate useful properties, showing how they can be used for isotropic standardization, where each dimension of a multivariate distribution is standardized using the same scale. We call this technique "PHI Standardization" (PHI-S) and empirically demonstrate that it produces the best student model across the suite of methods studied.
NVLM: Open Frontier-Class Multimodal LLMs
Sep 17, 2024



We introduce NVLM 1.0, a family of frontier-class multimodal large language models (LLMs) that achieve state-of-the-art results on vision-language tasks, rivaling the leading proprietary models (e.g., GPT-4o) and open-access models (e.g., Llama 3-V 405B and InternVL 2). Remarkably, NVLM 1.0 shows improved text-only performance over its LLM backbone after multimodal training. In terms of model design, we perform a comprehensive comparison between decoder-only multimodal LLMs (e.g., LLaVA) and cross-attention-based models (e.g., Flamingo). Based on the strengths and weaknesses of both approaches, we propose a novel architecture that enhances both training efficiency and multimodal reasoning capabilities. Furthermore, we introduce a 1-D tile-tagging design for tile-based dynamic high-resolution images, which significantly boosts performance on multimodal reasoning and OCR-related tasks. Regarding training data, we meticulously curate and provide detailed information on our multimodal pretraining and supervised fine-tuning datasets. Our findings indicate that dataset quality and task diversity are more important than scale, even during the pretraining phase, across all architectures. Notably, we develop production-grade multimodality for the NVLM-1.0 models, enabling them to excel in vision-language tasks while maintaining and even improving text-only performance compared to their LLM backbones. To achieve this, we craft and integrate a high-quality text-only dataset into multimodal training, alongside a substantial amount of multimodal math and reasoning data, leading to enhanced math and coding capabilities across modalities. To advance research in the field, we are releasing the model weights and will open-source the code for the community: https://nvlm-project.github.io/.
Using Speech Foundational Models in Loss Functions for Hearing Aid Speech Enhancement
Jul 18, 2024



Machine learning techniques are an active area of research for speech enhancement for hearing aids, with one particular focus on improving the intelligibility of a noisy speech signal. Recent work has shown that feature encodings from self-supervised speech representation models can effectively capture speech intelligibility. In this work, it is shown that the distance between self-supervised speech representations of clean and noisy speech correlates more strongly with human intelligibility ratings than other signal-based metrics. Experiments show that training a speech enhancement model using this distance as part of a loss function improves the performance over using an SNR-based loss function, demonstrated by an increase in HASPI, STOI, PESQ and SI-SNR scores. This method takes inference of a high parameter count model only at training time, meaning the speech enhancement model can remain smaller, as is required for hearing aids.
Non-Intrusive Speech Intelligibility Prediction for Hearing-Impaired Users using Intermediate ASR Features and Human Memory Models
Jan 24, 2024



Neural networks have been successfully used for non-intrusive speech intelligibility prediction. Recently, the use of feature representations sourced from intermediate layers of pre-trained self-supervised and weakly-supervised models has been found to be particularly useful for this task. This work combines the use of Whisper ASR decoder layer representations as neural network input features with an exemplar-based, psychologically motivated model of human memory to predict human intelligibility ratings for hearing-aid users. Substantial performance improvement over an established intrusive HASPI baseline system is found, including on enhancement systems and listeners unseen in the training data, with a root mean squared error of 25.3 compared with the baseline of 28.7.
Overview Of The 2023 Icassp Sp Clarity Challenge: Speech Enhancement For Hearing Aids
Nov 24, 2023

This paper reports on the design and outcomes of the ICASSP SP Clarity Challenge: Speech Enhancement for Hearing Aids. The scenario was a listener attending to a target speaker in a noisy, domestic environment. There were multiple interferers and head rotation by the listener. The challenge extended the second Clarity Enhancement Challenge (CEC2) by fixing the amplification stage of the hearing aid; evaluating with a combined metric for speech intelligibility and quality; and providing two evaluation sets, one based on simulation and the other on real-room measurements. Five teams improved on the baseline system for the simulated evaluation set, but the performance on the measured evaluation set was much poorer. Investigations are on-going to determine the exact cause of the mismatch between the simulated and measured data sets. The presence of transducer noise in the measurements, lower order Ambisonics harming the ability for systems to exploit binaural cues and the differences between real and simulated room impulse responses are suggested causes
Intelligibility prediction with a pretrained noise-robust automatic speech recognition model
Oct 20, 2023This paper describes two intelligibility prediction systems derived from a pretrained noise-robust automatic speech recognition (ASR) model for the second Clarity Prediction Challenge (CPC2). One system is intrusive and leverages the hidden representations of the ASR model. The other system is non-intrusive and makes predictions with derived ASR uncertainty. The ASR model is only pretrained with a simulated noisy speech corpus and does not take advantage of the CPC2 data. For that reason, the intelligibility prediction systems are robust to unseen scenarios given the accurate prediction performance on the CPC2 evaluation.
The First Cadenza Signal Processing Challenge: Improving Music for Those With a Hearing Loss
Oct 09, 2023The Cadenza project aims to improve the audio quality of music for those who have a hearing loss. This is being done through a series of signal processing challenges, to foster better and more inclusive technologies. In the first round, two common listening scenarios are considered: listening to music over headphones, and with a hearing aid in a car. The first scenario is cast as a demixing-remixing problem, where the music is decomposed into vocals, bass, drums and other components. These can then be intelligently remixed in a personalized way, to increase the audio quality for a person who has a hearing loss. In the second scenario, music is coming from car loudspeakers, and the music has to be enhanced to overcome the masking effect of the car noise. This is done by taking into account the music, the hearing ability of the listener, the hearing aid and the speed of the car. The audio quality of the submissions will be evaluated using the Hearing Aid Audio Quality Index (HAAQI) for objective assessment and by a panel of people with hearing loss for subjective evaluation.
The Cadenza ICASSP 2024 Grand Challenge
Oct 05, 2023


The Cadenza project aims to enhance the audio quality of music for individuals with hearing loss. As part of this, the project is organizing the ICASSP SP Cadenza Challenge: Music Demixing/Remixing for Hearing Aids. The challenge can be tackled by decomposing the music at the hearing aid microphones into vocals, bass, drums, and other components. These can then be intelligently remixed in a personalized manner to improve audio quality. Alternatively, an end-to-end approach could be used. Processes need to consider the music itself, the gain applied to each component, and the listener's hearing loss. The submitted entries will be evaluated using the intrusive objective metric, the Hearing Aid Audio Quality Index (HAAQI). This paper outlines the challenge.
On monoaural speech enhancement for automatic recognition of real noisy speech using mixture invariant training
May 03, 2022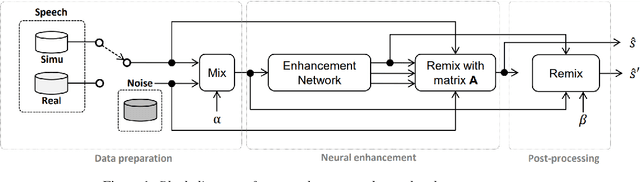
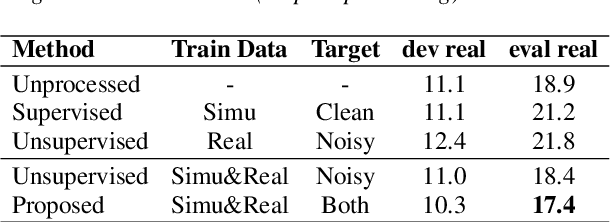
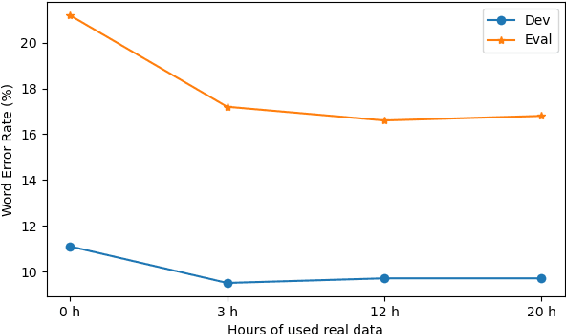
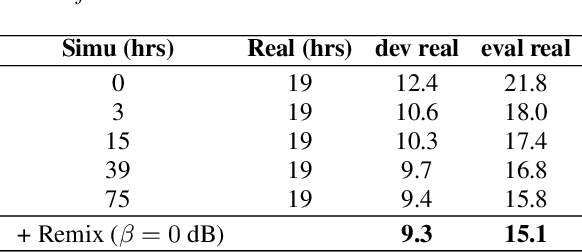
In this paper, we explore an improved framework to train a monoaural neural enhancement model for robust speech recognition. The designed training framework extends the existing mixture invariant training criterion to exploit both unpaired clean speech and real noisy data. It is found that the unpaired clean speech is crucial to improve quality of separated speech from real noisy speech. The proposed method also performs remixing of processed and unprocessed signals to alleviate the processing artifacts. Experiments on the single-channel CHiME-3 real test sets show that the proposed method improves significantly in terms of speech recognition performance over the enhancement system trained either on the mismatched simulated data in a supervised fashion or on the matched real data in an unsupervised fashion. Between 16% and 39% relative WER reduction has been achieved by the proposed system compared to the unprocessed signal using end-to-end and hybrid acoustic models without retraining on distorted data.