 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multimodal Query-guided Object Localization
Dec 01, 2022
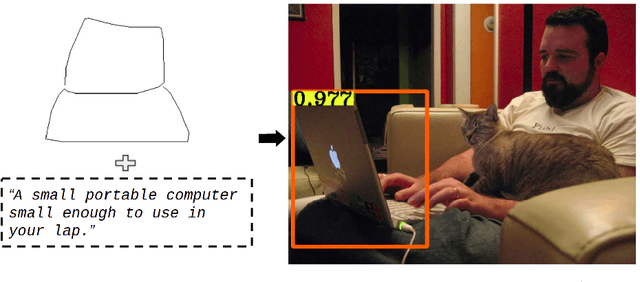
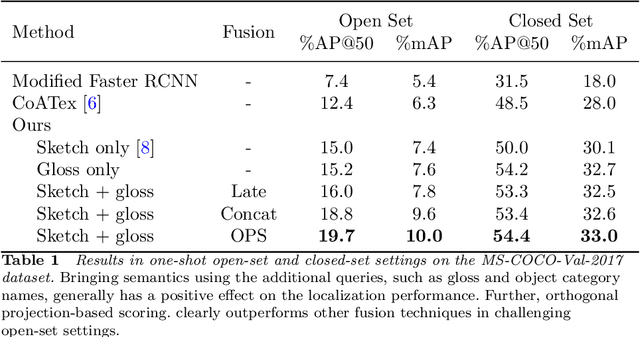
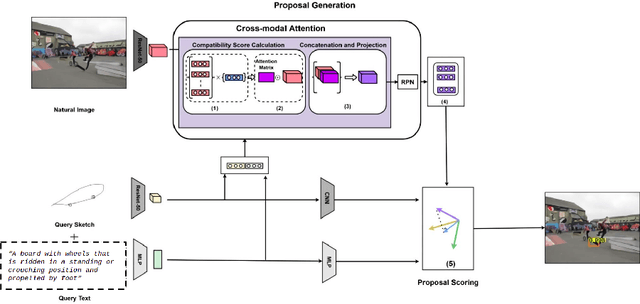

Consider a scenario in one-shot query-guided object localization where neither an image of the object nor the object category name is available as a query. In such a scenario, a hand-drawn sketch of the object could be a choice for a query. However, hand-drawn crude sketches alone, when used as queries, might be ambiguous for object localization, e.g., a sketch of a laptop could be confused for a sofa. On the other hand, a linguistic definition of the category, e.g., a small portable computer small enough to use in your lap" along with the sketch query, gives better visual and semantic cues for object localization. In this work, we present a multimodal query-guided object localization approach under the challenging open-set setting. In particular, we use queries from two modalities, namely, hand-drawn sketch and description of the object (also known as gloss), to perform object localization. Multimodal query-guided object localization is a challenging task, especially when a large domain gap exists between the queries and the natural images, as well as due to the challenge of combining the complementary and minimal information present across the queries. For example, hand-drawn crude sketches contain abstract shape information of an object, while the text descriptions often capture partial semantic information about a given object category. To address the aforementioned challenges, we present a novel cross-modal attention scheme that guides the region proposal network to generate object proposals relevant to the input queries and a novel orthogonal projection-based proposal scoring technique that scores each proposal with respect to the queries, thereby yielding the final localization results. ...
Automated, not Automatic: Needs and Practices in European Fact-checking Organizations as a basis for Designing Human-centered AI Systems
Nov 22, 2022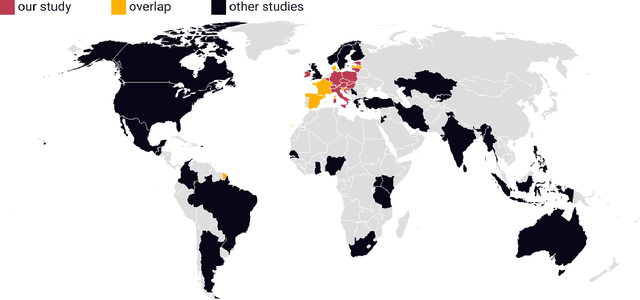
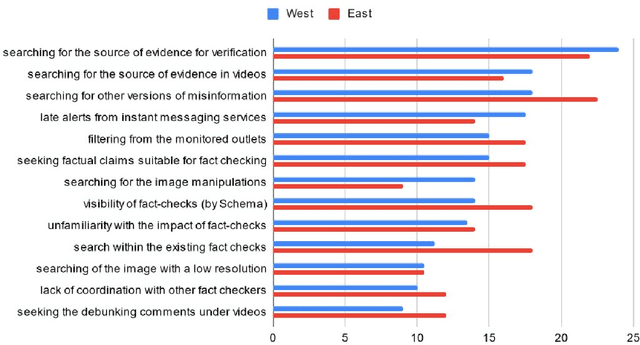
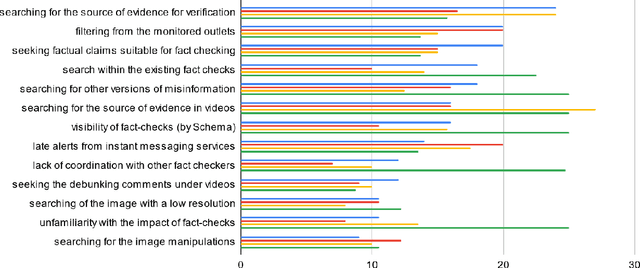
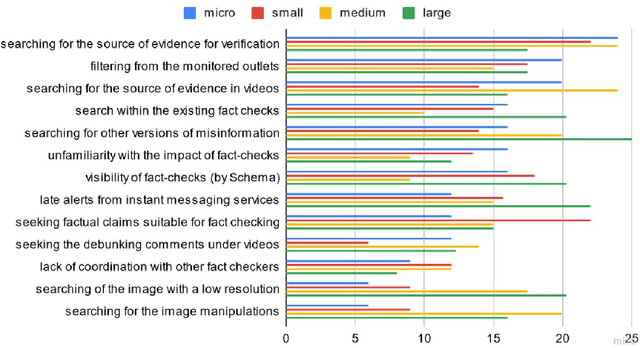
To mitigate the negative effects of false information more effectively, the development of automated AI (artificial intelligence) tools assisting fact-checkers is needed. Despite the existing research, there is still a gap between the fact-checking practitioners' needs and pains and the current AI research. We aspire to bridge this gap by employing methods of information behavior research to identify implications for designing better human-centered AI-based supporting tools. In this study, we conducted semi-structured in-depth interviews with Central European fact-checkers. The information behavior and requirements on desired supporting tools were analyzed using iterative bottom-up content analysis, bringing the techniques from grounded theory. The most significant needs were validated with a survey extended to fact-checkers from across Europe, in which we collected 24 responses from 20 European countries, i.e., 62% active European IFCN (International Fact-Checking Network) signatories. Our contributions are theoretical as well as practical. First, by being able to map our findings about the needs of fact-checking organizations to the relevant tasks for AI research, we have shown that the methods of information behavior research are relevant for studying the processes in the organizations and that these methods can be used to bridge the gap between the users and AI researchers. Second, we have identified fact-checkers' needs and pains focusing on so far unexplored dimensions and emphasizing the needs of fact-checkers from Central and Eastern Europe as well as from low-resource language groups which have implications for development of new resources (datasets) as well as for the focus of AI research in this domain.
NLIP: Noise-robust Language-Image Pre-training
Dec 14, 2022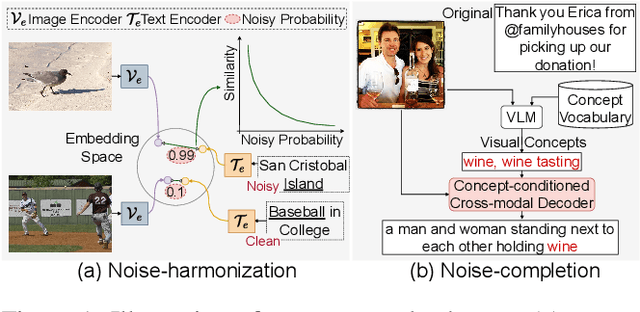
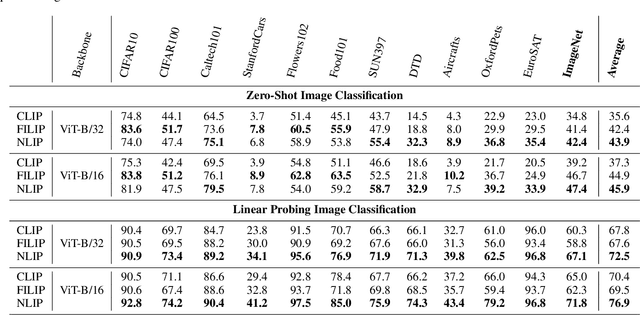
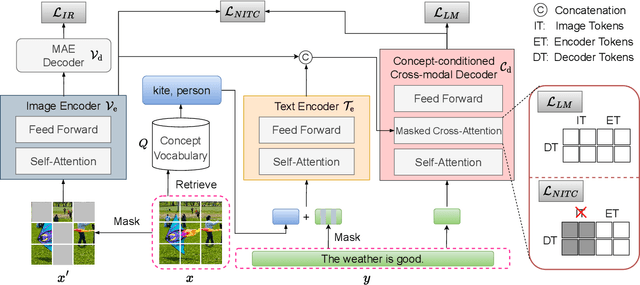
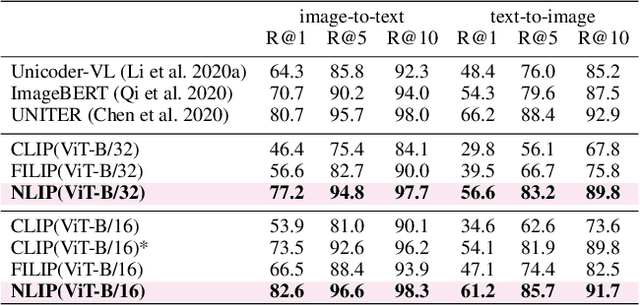
Large-scale cross-modal pre-training paradigms have recently shown ubiquitous success on a wide range of downstream tasks, e.g., zero-shot classification, retrieval and image captioning. However, their successes highly rely on the scale and quality of web-crawled data that naturally contain incomplete and noisy information (e.g., wrong or irrelevant content). Existing works either design manual rules to clean data or generate pseudo-targets as auxiliary signals for reducing noise impact, which do not explicitly tackle both the incorrect and incomplete challenges simultaneously. In this paper, to automatically mitigate the impact of noise by solely mining over existing data, we propose a principled Noise-robust Language-Image Pre-training framework (NLIP) to stabilize pre-training via two schemes: noise-harmonization and noise-completion. First, in noise-harmonization scheme, NLIP estimates the noise probability of each pair according to the memorization effect of cross-modal transformers, then adopts noise-adaptive regularization to harmonize the cross-modal alignments with varying degrees. Second, in noise-completion scheme, to enrich the missing object information of text, NLIP injects a concept-conditioned cross-modal decoder to obtain semantic-consistent synthetic captions to complete noisy ones, which uses the retrieved visual concepts (i.e., objects' names) for the corresponding image to guide captioning generation. By collaboratively optimizing noise-harmonization and noise-completion schemes, our NLIP can alleviate the common noise effects during image-text pre-training in a more efficient way. Extensive experiments show the significant performance improvements of our NLIP using only 26M data over existing pre-trained models (e.g., CLIP, FILIP and BLIP) on 12 zero-shot classification datasets, MSCOCO image captioning and zero-shot image-text retrieval tasks.
Disentangling Prosody Representations with Unsupervised Speech Reconstruction
Dec 14, 2022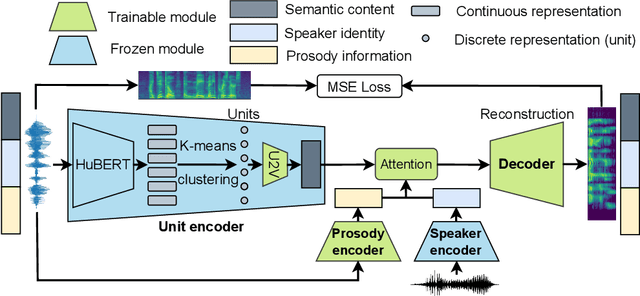
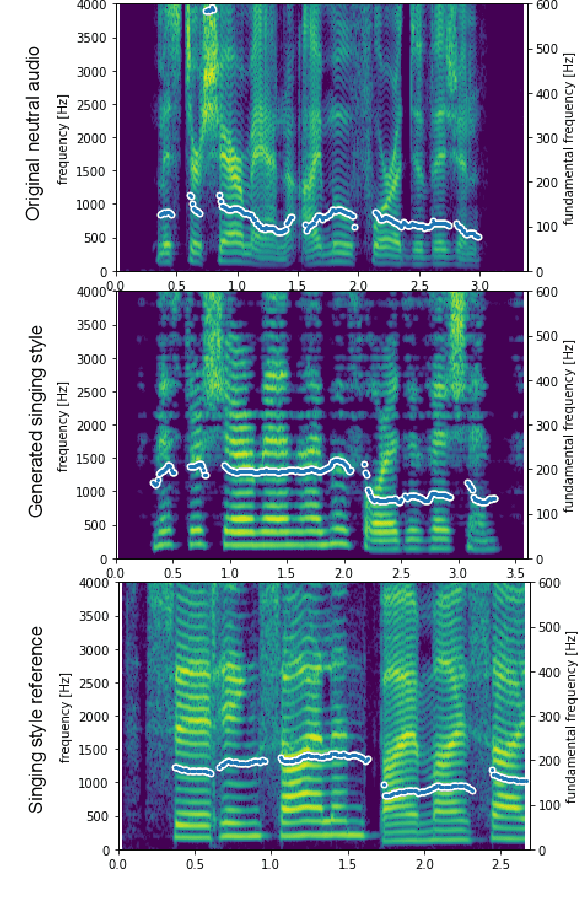
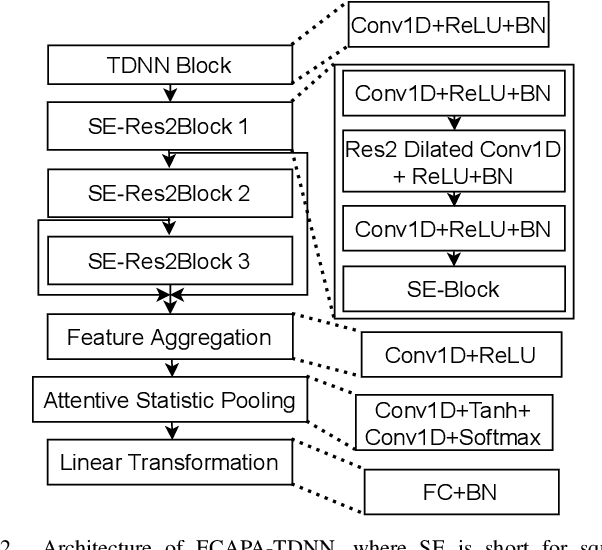
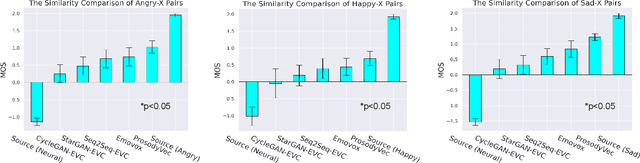
Human speech can be characterized by different components, including semantic content, speaker identity and prosodic information. Significant progress has been made in disentangling representations for semantic content and speaker identity in Automatic Speech Recognition (ASR) and speaker verification tasks respectively. However, it is still an open challenging research question to extract prosodic information because of the intrinsic association of different attributes, such as timbre and rhythm, and because of the need for unsupervised training schemes to achieve robust large-scale and speaker-independent ASR. The aim of this paper is to address the disentanglement of emotional prosody from speech based on unsupervised reconstruction. Specifically, we identify, design, implement and integrate three crucial components in our proposed speech reconstruction model Prosody2Vec: (1) a unit encoder that transforms speech signals into discrete units for semantic content, (2) a pretrained speaker verification model to generate speaker identity embeddings, and (3) a trainable prosody encoder to learn prosody representations. We first pretrain the Prosody2Vec representations on unlabelled emotional speech corpora, then fine-tune the model on specific datasets to perform Speech Emotion Recognition (SER) and Emotional Voice Conversion (EVC) tasks. Both objective and subjective evaluations on the EVC task suggest that Prosody2Vec effectively captures general prosodic features that can be smoothly transferred to other emotional speech. In addition, our SER experiments on the IEMOCAP dataset reveal that the prosody features learned by Prosody2Vec are complementary and beneficial for the performance of widely used speech pretraining models and surpass the state-of-the-art methods when combining Prosody2Vec with HuBERT representations. Some audio samples can be found on our demo website.
Weakly Supervised 3D Multi-person Pose Estimation for Large-scale Scenes based on Monocular Camera and Single LiDAR
Nov 30, 2022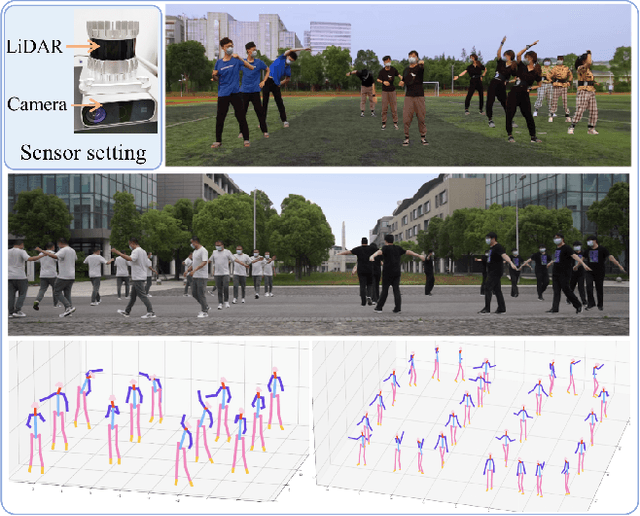
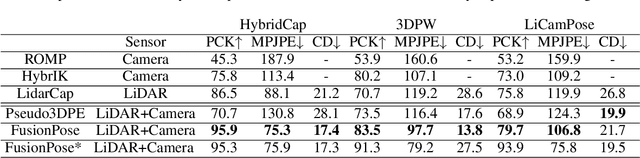
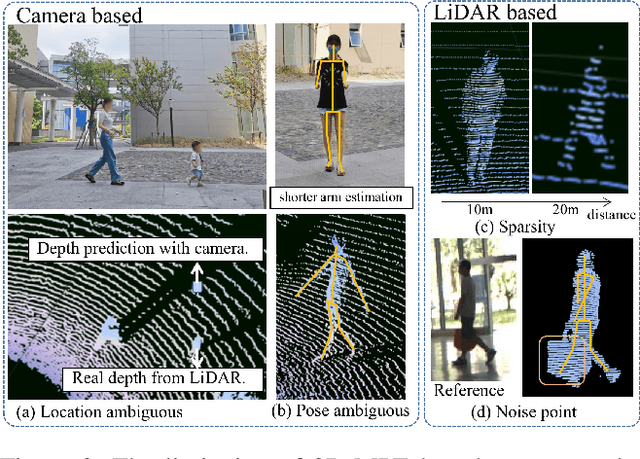
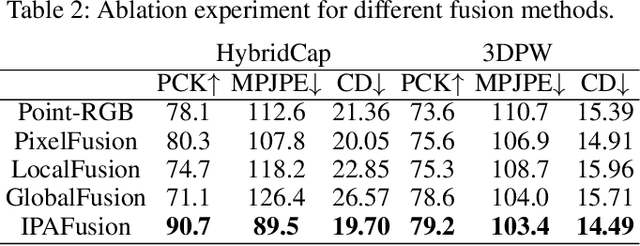
Depth estimation is usually ill-posed and ambiguous for monocular camera-based 3D multi-person pose estimation. Since LiDAR can capture accurate depth information in long-range scenes, it can benefit both the global localization of individuals and the 3D pose estimation by providing rich geometry features. Motivated by this, we propose a monocular camera and single LiDAR-based method for 3D multi-person pose estimation in large-scale scenes, which is easy to deploy and insensitive to light. Specifically, we design an effective fusion strategy to take advantage of multi-modal input data, including images and point cloud, and make full use of temporal information to guide the network to learn natural and coherent human motions. Without relying on any 3D pose annotations, our method exploits the inherent geometry constraints of point cloud for self-supervision and utilizes 2D keypoints on images for weak supervision. Extensive experiments on public datasets and our newly collected dataset demonstrate the superiority and generalization capability of our proposed method.
Silence is Sweeter Than Speech: Self-Supervised Model Using Silence to Store Speaker Information
May 08, 2022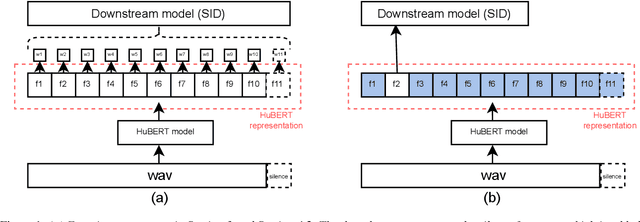
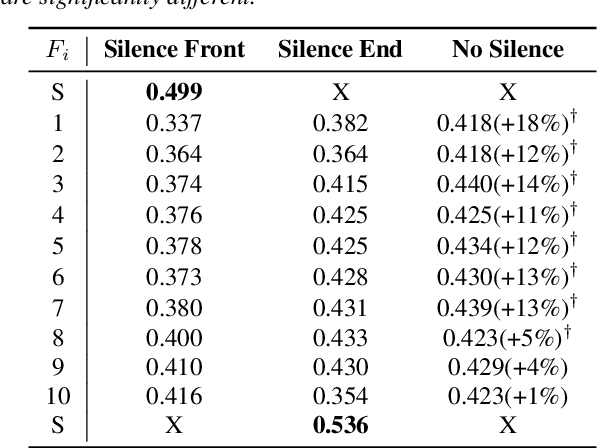
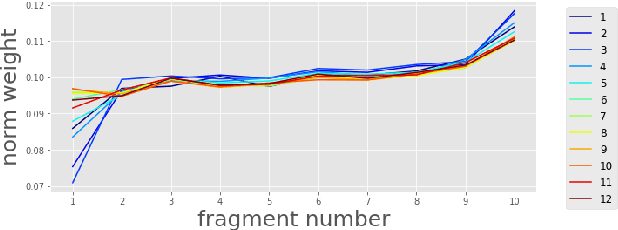
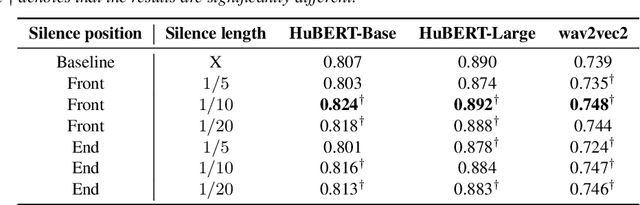
Self-Supervised Learning (SSL) has made great strides recently. SSL speech models achieve decent performance on a wide range of downstream tasks, suggesting that they extract different aspects of information from speech. However, how SSL models store various information in hidden representations without interfering is still poorly understood. Taking the recently successful SSL model, HuBERT, as an example, we explore how the SSL model processes and stores speaker information in the representation. We found that HuBERT stores speaker information in representations whose positions correspond to silences in a waveform. There are several pieces of evidence. (1) We find that the utterances with more silent parts in the waveforms have better Speaker Identification (SID) accuracy. (2) If we use the whole utterances for SID, the silence part always contributes more to the SID task. (3) If we only use the representation of a part of the utterance for SID, the silenced part has higher accuracy than the other parts. Our findings not only contribute to a better understanding of SSL models but also improve performance. By simply adding silence to the original waveform, HuBERT improved its accuracy on SID by nearly 2%.
Enabling Augmented Segmentation and Registration in Ultrasound-Guided Spinal Surgery via Realistic Ultrasound Synthesis from Diagnostic CT Volume
Jan 05, 2023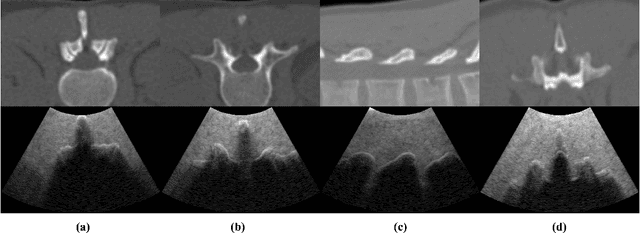
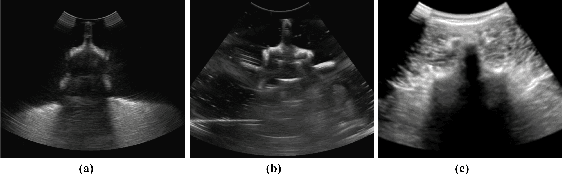


This paper aims to tackle the issues on unavailable or insufficient clinical US data and meaningful annotation to enable bone segmentation and registration for US-guided spinal surgery. While the US is not a standard paradigm for spinal surgery, the scarcity of intra-operative clinical US data is an insurmountable bottleneck in training a neural network. Moreover, due to the characteristics of US imaging, it is difficult to clearly annotate bone surfaces which causes the trained neural network missing its attention to the details. Hence, we propose an In silico bone US simulation framework that synthesizes realistic US images from diagnostic CT volume. Afterward, using these simulated bone US we train a lightweight vision transformer model that can achieve accurate and on-the-fly bone segmentation for spinal sonography. In the validation experiments, the realistic US simulation was conducted by deriving from diagnostic spinal CT volume to facilitate a radiation-free US-guided pedicle screw placement procedure. When it is employed for training bone segmentation task, the Chamfer distance achieves 0.599mm; when it is applied for CT-US registration, the associated bone segmentation accuracy achieves 0.93 in Dice, and the registration accuracy based on the segmented point cloud is 0.13~3.37mm in a complication-free manner. While bone US images exhibit strong echoes at the medium interface, it may enable the model indistinguishable between thin interfaces and bone surfaces by simply relying on small neighborhood information. To overcome these shortcomings, we propose to utilize a Long-range Contrast Learning Module to fully explore the Long-range Contrast between the candidates and their surrounding pixels.
Active Data Discovery: Mining Unknown Data using Submodular Information Measures
Jun 17, 2022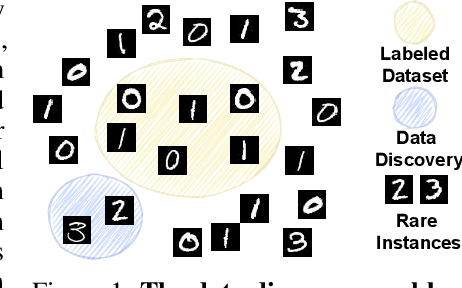
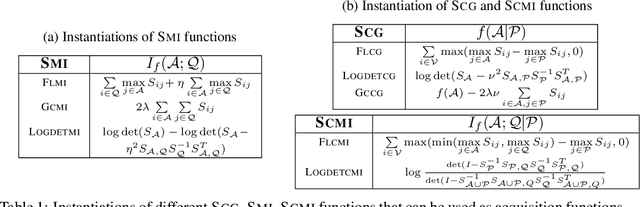
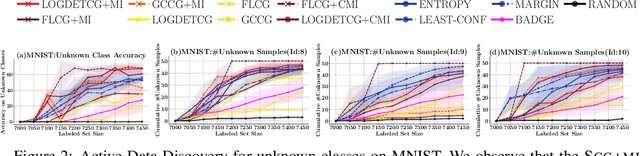
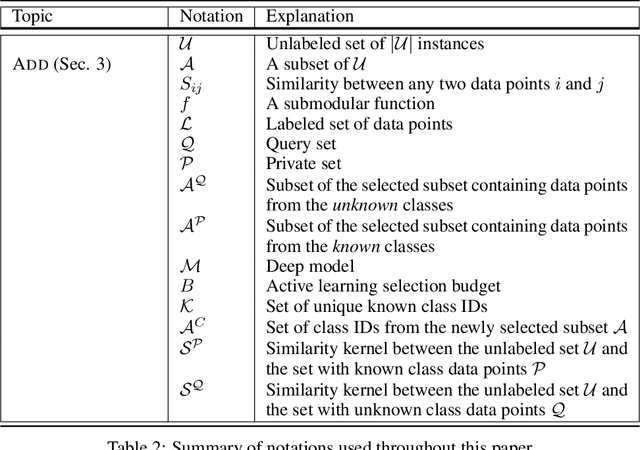
Active Learning is a very common yet powerful framework for iteratively and adaptively sampling subsets of the unlabeled sets with a human in the loop with the goal of achieving labeling efficiency. Most real world datasets have imbalance either in classes and slices, and correspondingly, parts of the dataset are rare. As a result, there has been a lot of work in designing active learning approaches for mining these rare data instances. Most approaches assume access to a seed set of instances which contain these rare data instances. However, in the event of more extreme rareness, it is reasonable to assume that these rare data instances (either classes or slices) may not even be present in the seed labeled set, and a critical need for the active learning paradigm is to efficiently discover these rare data instances. In this work, we provide an active data discovery framework which can mine unknown data slices and classes efficiently using the submodular conditional gain and submodular conditional mutual information functions. We provide a general algorithmic framework which works in a number of scenarios including image classification and object detection and works with both rare classes and rare slices present in the unlabeled set. We show significant accuracy and labeling efficiency gains with our approach compared to existing state-of-the-art active learning approaches for actively discovering these rare classes and slices.
TriPINet: Tripartite Progressive Integration Network for Image Manipulation Localization
Dec 25, 2022Image manipulation localization aims at distinguishing forged regions from the whole test image. Although many outstanding prior arts have been proposed for this task, there are still two issues that need to be further studied: 1) how to fuse diverse types of features with forgery clues; 2) how to progressively integrate multistage features for better localization performance. In this paper, we propose a tripartite progressive integration network (TriPINet) for end-to-end image manipulation localization. First, we extract both visual perception information, e.g., RGB input images, and visual imperceptible features, e.g., frequency and noise traces for forensic feature learning. Second, we develop a guided cross-modality dual-attention (gCMDA) module to fuse different types of forged clues. Third, we design a set of progressive integration squeeze-and-excitation (PI-SE) modules to improve localization performance by appropriately incorporating multiscale features in the decoder. Extensive experiments are conducted to compare our method with state-of-the-art image forensics approaches. The proposed TriPINet obtains competitive results on several benchmark datasets.
Does unsupervised grammar induction need pixels?
Dec 20, 2022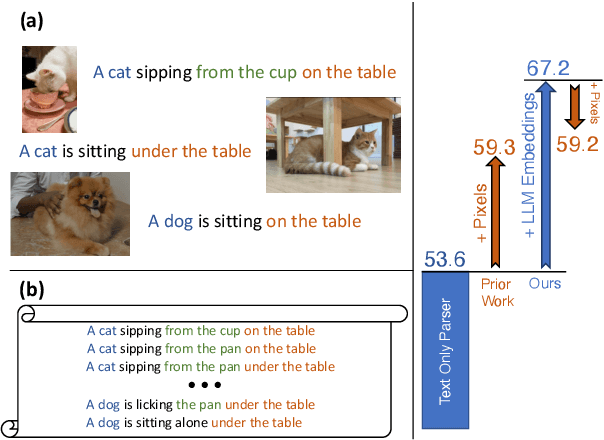

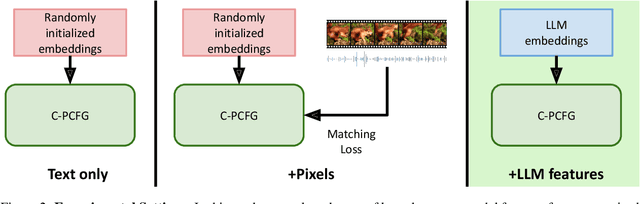
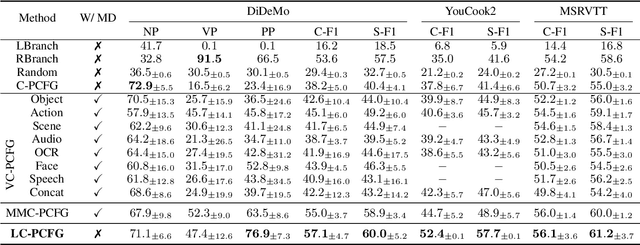
Are extralinguistic signals such as image pixels crucial for inducing constituency grammars? While past work has shown substantial gains from multimodal cues, we investigate whether such gains persist in the presence of rich information from large language models (LLMs). We find that our approach, LLM-based C-PCFG (LC-PCFG), outperforms previous multi-modal methods on the task of unsupervised constituency parsing, achieving state-of-the-art performance on a variety of datasets. Moreover, LC-PCFG results in an over 50% reduction in parameter count, and speedups in training time of 1.7x for image-aided models and more than 5x for video-aided models, respectively. These results challenge the notion that extralinguistic signals such as image pixels are needed for unsupervised grammar induction, and point to the need for better text-only baselines in evaluating the need of multi-modality for the task.