 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Geometry of Robustness: Optimizing Loss Landscape Curvature and Feature Manifold Alignment for Robust Finetuning of Vision-Language Models
Mar 28, 2026Fine-tuning approaches for Vision-Language Models (VLMs) face a critical three-way trade-off between In-Distribution (ID) accuracy, Out-of-Distribution (OOD) generalization, and adversarial robustness. Existing robust fine-tuning strategies resolve at most two axes of this trade-off. Generalization-preserving methods retain ID/OOD performance but leave models vulnerable to adversarial attacks, while adversarial training improves robustness to targeted attacks but degrades ID/OOD accuracy. Our key insight is that the robustness trade-off stems from two geometric failures: sharp, anisotropic minima in parameter space and unstable feature representations that deform under perturbation. To address this, we propose GRACE (Gram-aligned Robustness via Adaptive Curvature Estimation), a unified fine-tuning framework that jointly regularizes the parameter-space curvature and feature-space invariance for VLMs. Grounded in Robust PAC-Bayes theory, GRACE employs adaptive weight perturbations scaled by local curvature to promote flatter minima, combined with a feature alignment loss that maintains representation consistency across clean, adversarial, and OOD inputs. On ImageNet fine-tuning of CLIP models, GRACE simultaneously improves ID accuracy by 10.8%, and adversarial accuracy by 13.5% while maintaining 57.0% OOD accuracy (vs. 57.4% zero-shot baseline). Geometric analysis confirms that GRACE converges to flatter minima without feature distortion across distribution shifts, providing a principled step toward generalized robustness in foundation VLMs.
MedMoE: Modality-Specialized Mixture of Experts for Medical Vision-Language Understanding
Jun 11, 2025Different medical imaging modalities capture diagnostic information at varying spatial resolutions, from coarse global patterns to fine-grained localized structures. However, most existing vision-language frameworks in the medical domain apply a uniform strategy for local feature extraction, overlooking the modality-specific demands. In this work, we present MedMoE, a modular and extensible vision-language processing framework that dynamically adapts visual representation based on the diagnostic context. MedMoE incorporates a Mixture-of-Experts (MoE) module conditioned on the report type, which routes multi-scale image features through specialized expert branches trained to capture modality-specific visual semantics. These experts operate over feature pyramids derived from a Swin Transformer backbone, enabling spatially adaptive attention to clinically relevant regions. This framework produces localized visual representations aligned with textual descriptions, without requiring modality-specific supervision at inference. Empirical results on diverse medical benchmarks demonstrate that MedMoE improves alignment and retrieval performance across imaging modalities, underscoring the value of modality-specialized visual representations in clinical vision-language systems.
Mimicking or Reasoning: Rethinking Multi-Modal In-Context Learning in Vision-Language Models
Jun 09, 2025



Vision-language models (VLMs) are widely assumed to exhibit in-context learning (ICL), a property similar to that of their language-only counterparts. While recent work suggests VLMs can perform multimodal ICL (MM-ICL), studies show they often rely on shallow heuristics -- such as copying or majority voting -- rather than true task understanding. We revisit this assumption by evaluating VLMs under distribution shifts, where support examples come from a dataset different from the query. Surprisingly, performance often degrades with more demonstrations, and models tend to copy answers rather than learn from them. To investigate further, we propose a new MM-ICL with Reasoning pipeline that augments each demonstration with a generated rationale alongside the answer. We conduct extensive and comprehensive experiments on both perception- and reasoning-required datasets with open-source VLMs ranging from 3B to 72B and proprietary models such as Gemini 2.0. We conduct controlled studies varying shot count, retrieval method, rationale quality, and distribution. Our results show limited performance sensitivity across these factors, suggesting that current VLMs do not effectively utilize demonstration-level information as intended in MM-ICL.
FRAMES-VQA: Benchmarking Fine-Tuning Robustness across Multi-Modal Shifts in Visual Question Answering
May 27, 2025Visual question answering (VQA) systems face significant challenges when adapting to real-world data shifts, especially in multi-modal contexts. While robust fine-tuning strategies are essential for maintaining performance across in-distribution (ID) and out-of-distribution (OOD) scenarios, current evaluation settings are primarily unimodal or particular to some types of OOD, offering limited insight into the complexities of multi-modal contexts. In this work, we propose a new benchmark FRAMES-VQA (Fine-Tuning Robustness across Multi-Modal Shifts in VQA) for evaluating robust fine-tuning for VQA tasks. We utilize ten existing VQA benchmarks, including VQAv2, IV-VQA, VQA-CP, OK-VQA and others, and categorize them into ID, near and far OOD datasets covering uni-modal, multi-modal and adversarial distribution shifts. We first conduct a comprehensive comparison of existing robust fine-tuning methods. We then quantify the distribution shifts by calculating the Mahalanobis distance using uni-modal and multi-modal embeddings extracted from various models. Further, we perform an extensive analysis to explore the interactions between uni- and multi-modal shifts as well as modality importance for ID and OOD samples. These analyses offer valuable guidance on developing more robust fine-tuning methods to handle multi-modal distribution shifts. The code is available at https://github.com/chengyuehuang511/FRAMES-VQA .
Directional Gradient Projection for Robust Fine-Tuning of Foundation Models
Feb 21, 2025



Robust fine-tuning aims to adapt large foundation models to downstream tasks while preserving their robustness to distribution shifts. Existing methods primarily focus on constraining and projecting current model towards the pre-trained initialization based on the magnitudes between fine-tuned and pre-trained weights, which often require extensive hyper-parameter tuning and can sometimes result in underfitting. In this work, we propose Directional Gradient Projection (DiGraP), a novel layer-wise trainable method that incorporates directional information from gradients to bridge regularization and multi-objective optimization. Besides demonstrating our method on image classification, as another contribution we generalize this area to the multi-modal evaluation settings for robust fine-tuning. Specifically, we first bridge the uni-modal and multi-modal gap by performing analysis on Image Classification reformulated Visual Question Answering (VQA) benchmarks and further categorize ten out-of-distribution (OOD) VQA datasets by distribution shift types and degree (i.e. near versus far OOD). Experimental results show that DiGraP consistently outperforms existing baselines across Image Classfication and VQA tasks with discriminative and generative backbones, improving both in-distribution (ID) generalization and OOD robustness.
Refining Text-to-Image Generation: Towards Accurate Training-Free Glyph-Enhanced Image Generation
Mar 25, 2024



Over the past few years, Text-to-Image (T2I) generation approaches based on diffusion models have gained significant attention. However, vanilla diffusion models often suffer from spelling inaccuracies in the text displayed within the generated images. The capability to generate visual text is crucial, offering both academic interest and a wide range of practical applications. To produce accurate visual text images, state-of-the-art techniques adopt a glyph-controlled image generation approach, consisting of a text layout generator followed by an image generator that is conditioned on the generated text layout. Nevertheless, our study reveals that these models still face three primary challenges, prompting us to develop a testbed to facilitate future research. We introduce a benchmark, LenCom-Eval, specifically designed for testing models' capability in generating images with Lengthy and Complex visual text. Subsequently, we introduce a training-free framework to enhance the two-stage generation approaches. We examine the effectiveness of our approach on both LenCom-Eval and MARIO-Eval benchmarks and demonstrate notable improvements across a range of evaluation metrics, including CLIPScore, OCR precision, recall, F1 score, accuracy, and edit distance scores. For instance, our proposed framework improves the backbone model, TextDiffuser, by more than 23\% and 13.5\% in terms of OCR word F1 on LenCom-Eval and MARIO-Eval, respectively. Our work makes a unique contribution to the field by focusing on generating images with long and rare text sequences, a niche previously unexplored by existing literature
Source-Free Domain Adaptation with Diffusion-Guided Source Data Generation
Feb 07, 2024



This paper introduces a novel approach to leverage the generalizability capability of Diffusion Models for Source-Free Domain Adaptation (DM-SFDA). Our proposed DM-SFDA method involves fine-tuning a pre-trained text-to-image diffusion model to generate source domain images using features from the target images to guide the diffusion process. Specifically, the pre-trained diffusion model is fine-tuned to generate source samples that minimize entropy and maximize confidence for the pre-trained source model. We then apply established unsupervised domain adaptation techniques to align the generated source images with target domain data. We validate our approach through comprehensive experiments across a range of datasets, including Office-31, Office-Home, and VisDA. The results highlight significant improvements in SFDA performance, showcasing the potential of diffusion models in generating contextually relevant, domain-specific images.
Learning to Discern: Imitating Heterogeneous Human Demonstrations with Preference and Representation Learning
Oct 22, 2023



Practical Imitation Learning (IL) systems rely on large human demonstration datasets for successful policy learning. However, challenges lie in maintaining the quality of collected data and addressing the suboptimal nature of some demonstrations, which can compromise the overall dataset quality and hence the learning outcome. Furthermore, the intrinsic heterogeneity in human behavior can produce equally successful but disparate demonstrations, further exacerbating the challenge of discerning demonstration quality. To address these challenges, this paper introduces Learning to Discern (L2D), an offline imitation learning framework for learning from demonstrations with diverse quality and style. Given a small batch of demonstrations with sparse quality labels, we learn a latent representation for temporally embedded trajectory segments. Preference learning in this latent space trains a quality evaluator that generalizes to new demonstrators exhibiting different styles. Empirically, we show that L2D can effectively assess and learn from varying demonstrations, thereby leading to improved policy performance across a range of tasks in both simulations and on a physical robot.
Transcending Domains through Text-to-Image Diffusion: A Source-Free Approach to Domain Adaptation
Oct 14, 2023



Domain Adaptation (DA) is a method for enhancing a model's performance on a target domain with inadequate annotated data by applying the information the model has acquired from a related source domain with sufficient labeled data. The escalating enforcement of data-privacy regulations like HIPAA, COPPA, FERPA, etc. have sparked a heightened interest in adapting models to novel domains while circumventing the need for direct access to the source data, a problem known as Source-Free Domain Adaptation (SFDA). In this paper, we propose a novel framework for SFDA that generates source data using a text-to-image diffusion model trained on the target domain samples. Our method starts by training a text-to-image diffusion model on the labeled target domain samples, which is then fine-tuned using the pre-trained source model to generate samples close to the source data. Finally, we use Domain Adaptation techniques to align the artificially generated source data with the target domain data, resulting in significant performance improvements of the model on the target domain. Through extensive comparison against several baselines on the standard Office-31, Office-Home, and VisDA benchmarks, we demonstrate the effectiveness of our approach for the SFDA task.
Active Data Discovery: Mining Unknown Data using Submodular Information Measures
Jun 17, 2022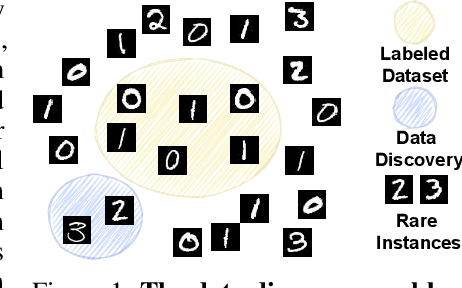
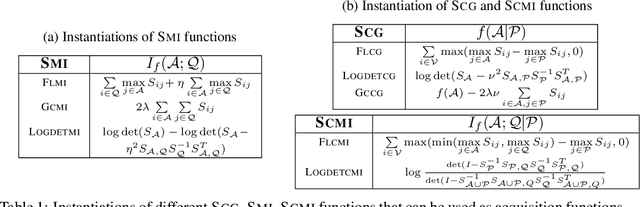
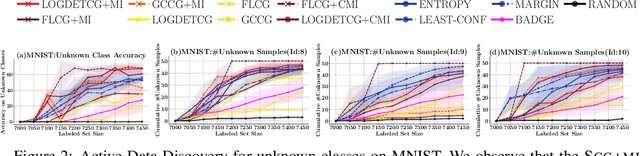
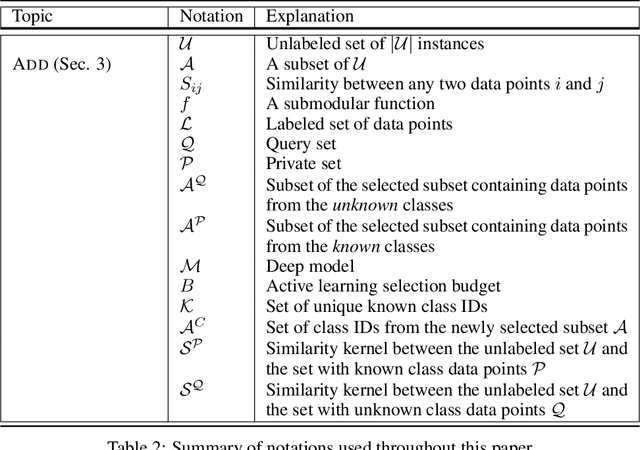
Active Learning is a very common yet powerful framework for iteratively and adaptively sampling subsets of the unlabeled sets with a human in the loop with the goal of achieving labeling efficiency. Most real world datasets have imbalance either in classes and slices, and correspondingly, parts of the dataset are rare. As a result, there has been a lot of work in designing active learning approaches for mining these rare data instances. Most approaches assume access to a seed set of instances which contain these rare data instances. However, in the event of more extreme rareness, it is reasonable to assume that these rare data instances (either classes or slices) may not even be present in the seed labeled set, and a critical need for the active learning paradigm is to efficiently discover these rare data instances. In this work, we provide an active data discovery framework which can mine unknown data slices and classes efficiently using the submodular conditional gain and submodular conditional mutual information functions. We provide a general algorithmic framework which works in a number of scenarios including image classification and object detection and works with both rare classes and rare slices present in the unlabeled set. We show significant accuracy and labeling efficiency gains with our approach compared to existing state-of-the-art active learning approaches for actively discovering these rare classes and slices.