 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFollow the Clues, Frame the Truth: Hybrid-evidential Deductive Reasoning in Open-Vocabulary Multimodal Emotion Recognition
Mar 17, 2026Open-Vocabulary Multimodal Emotion Recognition (OV-MER) is inherently challenging due to the ambiguity of equivocal multimodal cues, which often stem from distinct unobserved situational dynamics. While Multimodal Large Language Models (MLLMs) offer extensive semantic coverage, their performance is often bottlenecked by premature commitment to dominant data priors, resulting in suboptimal heuristics that overlook crucial, complementary affective cues across modalities. We argue that effective affective reasoning requires more than surface-level association; it necessitates reconstructing nuanced emotional states by synthesizing multiple evidence-grounded rationales that reconcile these observations from diverse latent perspectives. We introduce HyDRA, a Hybrid-evidential Deductive Reasoning Architecture that formalizes inference as a Propose-Verify-Decide protocol. To internalize this abductive process, we employ reinforcement learning with hierarchical reward shaping, aligning the reasoning trajectories with final task performance to ensure they best reconcile the observed multimodal cues. Systematic evaluations validate our design choices, with HyDRA consistently outperforming strong baselines--especially in ambiguous or conflicting scenarios--while providing interpretable, diagnostic evidence traces.
From Coarse to Nuanced: Cross-Modal Alignment of Fine-Grained Linguistic Cues and Visual Salient Regions for Dynamic Emotion Recognition
Jul 16, 2025Dynamic Facial Expression Recognition (DFER) aims to identify human emotions from temporally evolving facial movements and plays a critical role in affective computing. While recent vision-language approaches have introduced semantic textual descriptions to guide expression recognition, existing methods still face two key limitations: they often underutilize the subtle emotional cues embedded in generated text, and they have yet to incorporate sufficiently effective mechanisms for filtering out facial dynamics that are irrelevant to emotional expression. To address these gaps, We propose GRACE, Granular Representation Alignment for Cross-modal Emotion recognition that integrates dynamic motion modeling, semantic text refinement, and token-level cross-modal alignment to facilitate the precise localization of emotionally salient spatiotemporal features. Our method constructs emotion-aware textual descriptions via a Coarse-to-fine Affective Text Enhancement (CATE) module and highlights expression-relevant facial motion through a motion-difference weighting mechanism. These refined semantic and visual signals are aligned at the token level using entropy-regularized optimal transport. Experiments on three benchmark datasets demonstrate that our method significantly improves recognition performance, particularly in challenging settings with ambiguous or imbalanced emotion classes, establishing new state-of-the-art (SOTA) results in terms of both UAR and WAR.
Emphasizing Unseen Words: New Vocabulary Acquisition for End-to-End Speech Recognition
Feb 21, 2023Due to the dynamic nature of human language, automatic speech recognition (ASR) systems need to continuously acquire new vocabulary. Out-Of-Vocabulary (OOV) words, such as trending words and new named entities, pose problems to modern ASR systems that require long training times to adapt their large numbers of parameters. Different from most previous research focusing on language model post-processing, we tackle this problem on an earlier processing level and eliminate the bias in acoustic modeling to recognize OOV words acoustically. We propose to generate OOV words using text-to-speech systems and to rescale losses to encourage neural networks to pay more attention to OOV words. Specifically, we enlarge the classification loss used for training neural networks' parameters of utterances containing OOV words (sentence-level), or rescale the gradient used for back-propagation for OOV words (word-level), when fine-tuning a previously trained model on synthetic audio. To overcome catastrophic forgetting, we also explore the combination of loss rescaling and model regularization, i.e. L2 regularization and elastic weight consolidation (EWC). Compared with previous methods that just fine-tune synthetic audio with EWC, the experimental results on the LibriSpeech benchmark reveal that our proposed loss rescaling approach can achieve significant improvement on the recall rate with only a slight decrease on word error rate. Moreover, word-level rescaling is more stable than utterance-level rescaling and leads to higher recall rates and precision on OOV word recognition. Furthermore, our proposed combined loss rescaling and weight consolidation methods can support continual learning of an ASR system.
Disentangling Prosody Representations with Unsupervised Speech Reconstruction
Dec 14, 2022



Human speech can be characterized by different components, including semantic content, speaker identity and prosodic information. Significant progress has been made in disentangling representations for semantic content and speaker identity in Automatic Speech Recognition (ASR) and speaker verification tasks respectively. However, it is still an open challenging research question to extract prosodic information because of the intrinsic association of different attributes, such as timbre and rhythm, and because of the need for unsupervised training schemes to achieve robust large-scale and speaker-independent ASR. The aim of this paper is to address the disentanglement of emotional prosody from speech based on unsupervised reconstruction. Specifically, we identify, design, implement and integrate three crucial components in our proposed speech reconstruction model Prosody2Vec: (1) a unit encoder that transforms speech signals into discrete units for semantic content, (2) a pretrained speaker verification model to generate speaker identity embeddings, and (3) a trainable prosody encoder to learn prosody representations. We first pretrain the Prosody2Vec representations on unlabelled emotional speech corpora, then fine-tune the model on specific datasets to perform Speech Emotion Recognition (SER) and Emotional Voice Conversion (EVC) tasks. Both objective and subjective evaluations on the EVC task suggest that Prosody2Vec effectively captures general prosodic features that can be smoothly transferred to other emotional speech. In addition, our SER experiments on the IEMOCAP dataset reveal that the prosody features learned by Prosody2Vec are complementary and beneficial for the performance of widely used speech pretraining models and surpass the state-of-the-art methods when combining Prosody2Vec with HuBERT representations. Some audio samples can be found on our demo website.
Data Augmentation with Unsupervised Speaking Style Transfer for Speech Emotion Recognition
Nov 16, 2022



Currently, the performance of Speech Emotion Recognition (SER) systems is mainly constrained by the absence of large-scale labelled corpora. Data augmentation is regarded as a promising approach, which borrows methods from Automatic Speech Recognition (ASR), for instance, perturbation on speed and pitch, or generating emotional speech utilizing generative adversarial networks. In this paper, we propose EmoAug, a novel style transfer model to augment emotion expressions, in which a semantic encoder and a paralinguistic encoder represent verbal and non-verbal information respectively. Additionally, a decoder reconstructs speech signals by conditioning on the aforementioned two information flows in an unsupervised fashion. Once training is completed, EmoAug enriches expressions of emotional speech in different prosodic attributes, such as stress, rhythm and intensity, by feeding different styles into the paralinguistic encoder. In addition, we can also generate similar numbers of samples for each class to tackle the data imbalance issue. Experimental results on the IEMOCAP dataset demonstrate that EmoAug can successfully transfer different speaking styles while retaining the speaker identity and semantic content. Furthermore, we train a SER model with data augmented by EmoAug and show that it not only surpasses the state-of-the-art supervised and self-supervised methods but also overcomes overfitting problems caused by data imbalance. Some audio samples can be found on our demo website.
A Multimodal German Dataset for Automatic Lip Reading Systems and Transfer Learning
Feb 27, 2022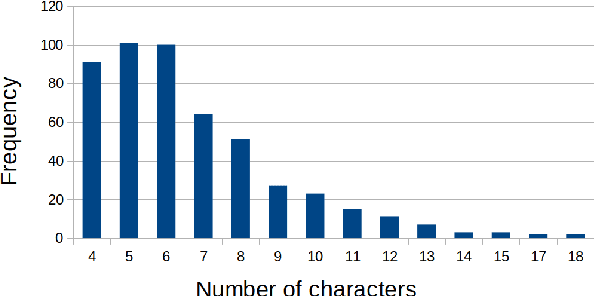
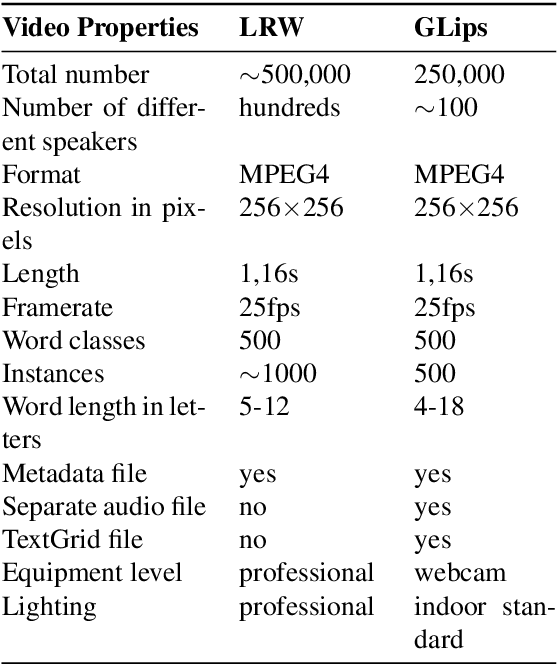

Large datasets as required for deep learning of lip reading do not exist in many languages. In this paper we present the dataset GLips (German Lips) consisting of 250,000 publicly available videos of the faces of speakers of the Hessian Parliament, which was processed for word-level lip reading using an automatic pipeline. The format is similar to that of the English language LRW (Lip Reading in the Wild) dataset, with each video encoding one word of interest in a context of 1.16 seconds duration, which yields compatibility for studying transfer learning between both datasets. By training a deep neural network, we investigate whether lip reading has language-independent features, so that datasets of different languages can be used to improve lip reading models. We demonstrate learning from scratch and show that transfer learning from LRW to GLips and vice versa improves learning speed and performance, in particular for the validation set.
LipSound2: Self-Supervised Pre-Training for Lip-to-Speech Reconstruction and Lip Reading
Dec 09, 2021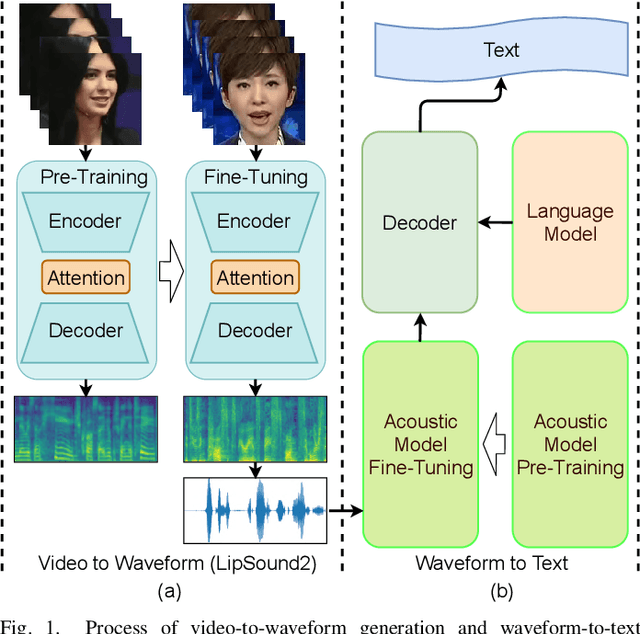
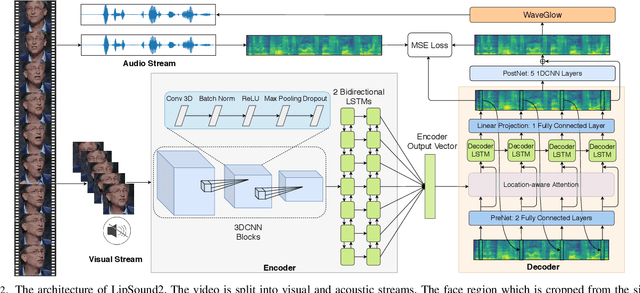
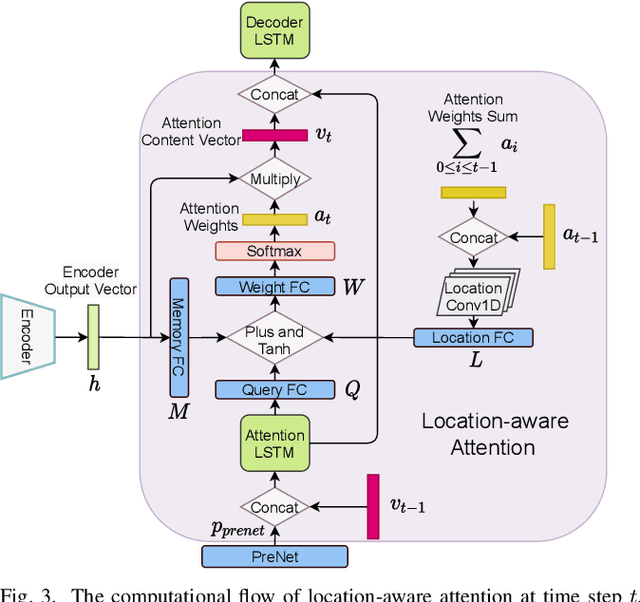

The aim of this work is to investigate the impact of crossmodal self-supervised pre-training for speech reconstruction (video-to-audio) by leveraging the natural co-occurrence of audio and visual streams in videos. We propose LipSound2 which consists of an encoder-decoder architecture and location-aware attention mechanism to map face image sequences to mel-scale spectrograms directly without requiring any human annotations. The proposed LipSound2 model is firstly pre-trained on $\sim$2400h multi-lingual (e.g. English and German) audio-visual data (VoxCeleb2). To verify the generalizability of the proposed method, we then fine-tune the pre-trained model on domain-specific datasets (GRID, TCD-TIMIT) for English speech reconstruction and achieve a significant improvement on speech quality and intelligibility compared to previous approaches in speaker-dependent and -independent settings. In addition to English, we conduct Chinese speech reconstruction on the CMLR dataset to verify the impact on transferability. Lastly, we train the cascaded lip reading (video-to-text) system by fine-tuning the generated audios on a pre-trained speech recognition system and achieve state-of-the-art performance on both English and Chinese benchmark datasets.