 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding a Taiwanese Mandarin Spoken Language Model: A First Attempt
Nov 11, 2024



This technical report presents our initial attempt to build a spoken large language model (LLM) for Taiwanese Mandarin, specifically tailored to enable real-time, speech-to-speech interaction in multi-turn conversations. Our end-to-end model incorporates a decoder-only transformer architecture and aims to achieve seamless interaction while preserving the conversational flow, including full-duplex capabilities allowing simultaneous speaking and listening. The paper also details the training process, including data preparation with synthesized dialogues and adjustments for real-time interaction. We also developed a platform to evaluate conversational fluency and response coherence in multi-turn dialogues. We hope the release of the report can contribute to the future development of spoken LLMs in Taiwanese Mandarin.
Low-Resource Self-Supervised Learning with SSL-Enhanced TTS
Sep 29, 2023



Self-supervised learning (SSL) techniques have achieved remarkable results in various speech processing tasks. Nonetheless, a significant challenge remains in reducing the reliance on vast amounts of speech data for pre-training. This paper proposes to address this challenge by leveraging synthetic speech to augment a low-resource pre-training corpus. We construct a high-quality text-to-speech (TTS) system with limited resources using SSL features and generate a large synthetic corpus for pre-training. Experimental results demonstrate that our proposed approach effectively reduces the demand for speech data by 90\% with only slight performance degradation. To the best of our knowledge, this is the first work aiming to enhance low-resource self-supervised learning in speech processing.
Learning Phone Recognition from Unpaired Audio and Phone Sequences Based on Generative Adversarial Network
Jul 29, 2022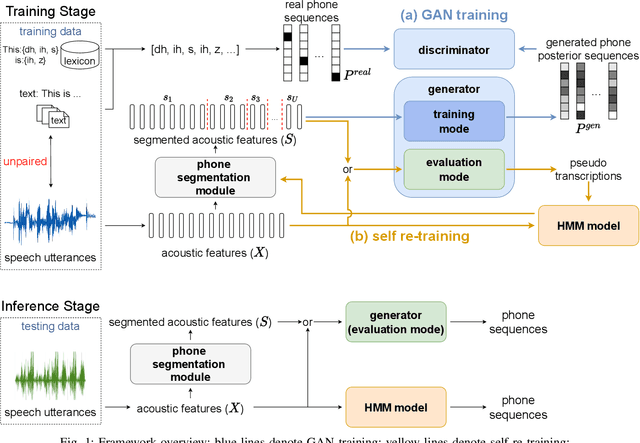
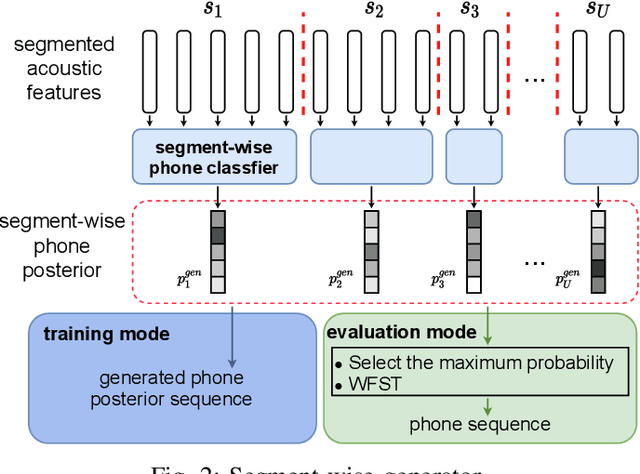
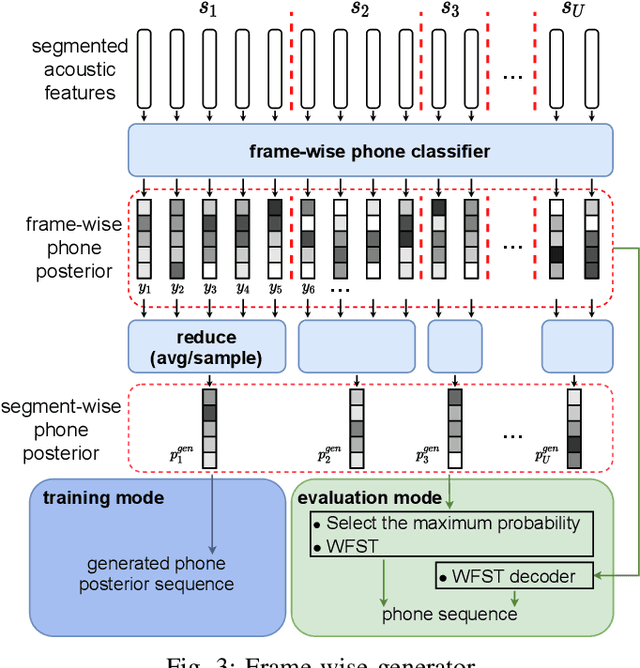
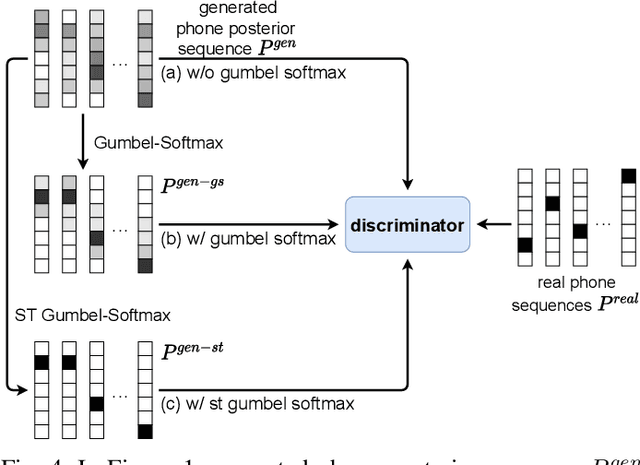
ASR has been shown to achieve great performance recently. However, most of them rely on massive paired data, which is not feasible for low-resource languages worldwide. This paper investigates how to learn directly from unpaired phone sequences and speech utterances. We design a two-stage iterative framework. GAN training is adopted in the first stage to find the mapping relationship between unpaired speech and phone sequence. In the second stage, another HMM model is introduced to train from the generator's output, which boosts the performance and provides a better segmentation for the next iteration. In the experiment, we first investigate different choices of model designs. Then we compare the framework to different types of baselines: (i) supervised methods (ii) acoustic unit discovery based methods (iii) methods learning from unpaired data. Our framework performs consistently better than all acoustic unit discovery methods and previous methods learning from unpaired data based on the TIMIT dataset.
Silence is Sweeter Than Speech: Self-Supervised Model Using Silence to Store Speaker Information
May 08, 2022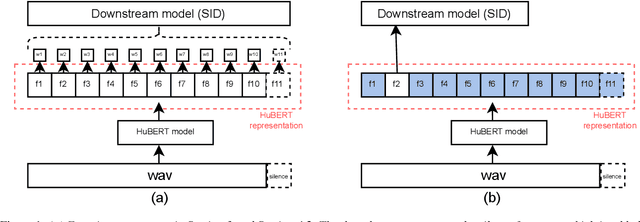
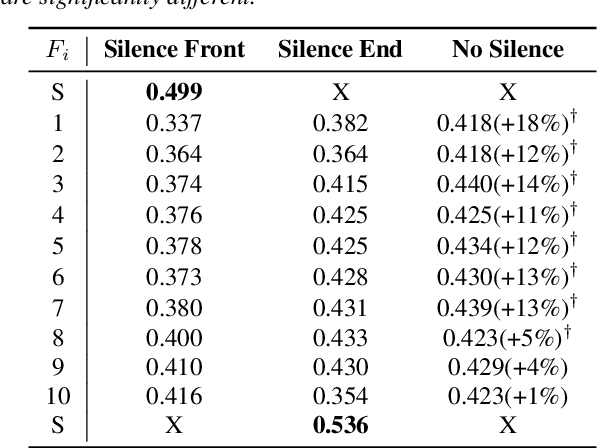
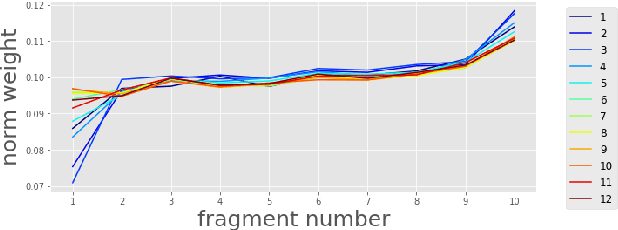
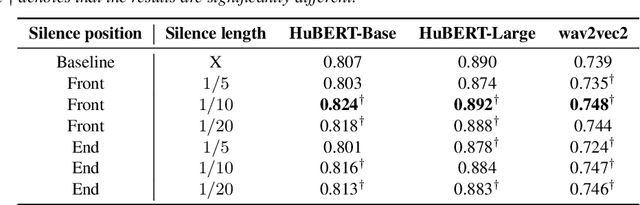
Self-Supervised Learning (SSL) has made great strides recently. SSL speech models achieve decent performance on a wide range of downstream tasks, suggesting that they extract different aspects of information from speech. However, how SSL models store various information in hidden representations without interfering is still poorly understood. Taking the recently successful SSL model, HuBERT, as an example, we explore how the SSL model processes and stores speaker information in the representation. We found that HuBERT stores speaker information in representations whose positions correspond to silences in a waveform. There are several pieces of evidence. (1) We find that the utterances with more silent parts in the waveforms have better Speaker Identification (SID) accuracy. (2) If we use the whole utterances for SID, the silence part always contributes more to the SID task. (3) If we only use the representation of a part of the utterance for SID, the silenced part has higher accuracy than the other parts. Our findings not only contribute to a better understanding of SSL models but also improve performance. By simply adding silence to the original waveform, HuBERT improved its accuracy on SID by nearly 2%.
Parallel Synthesis for Autoregressive Speech Generation
Apr 25, 2022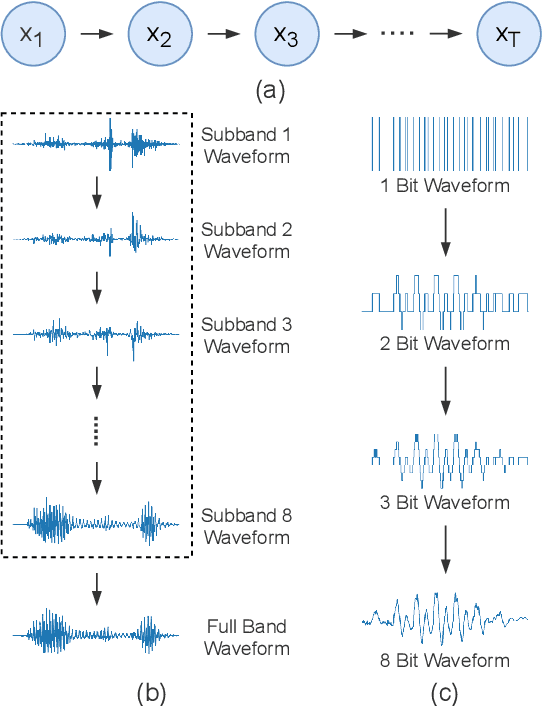
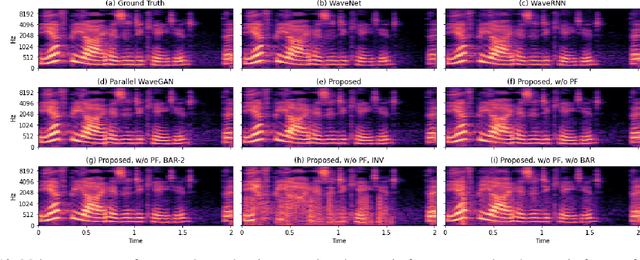
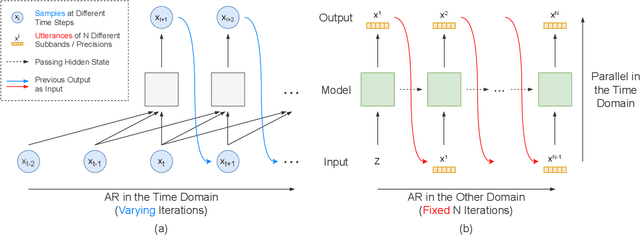
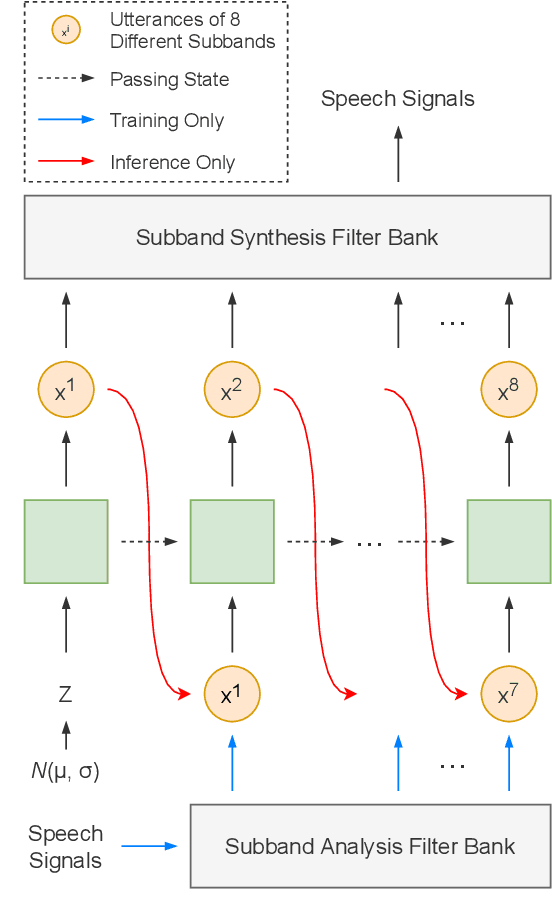
Autoregressive models have achieved outstanding performance in neural speech synthesis tasks. Though they can generate highly natural human speech, the iterative generation inevitably makes the synthesis time proportional to the utterance's length, leading to low efficiency. Many works were dedicated to generating the whole speech time sequence in parallel and then proposed GAN-based, flow-based, and score-based models. This paper proposed a new thought for the autoregressive generation. Instead of iteratively predicting samples in a time sequence, the proposed model performs frequency-wise autoregressive generation (FAR) and bit-wise autoregressive generation (BAR) to synthesize speech. In FAR, a speech utterance is first split into different frequency subbands. The proposed model generates a subband conditioned on the previously generated one. A full band speech can then be reconstructed by using these generated subbands and a synthesis filter bank. Similarly, in BAR, an 8-bit quantized signal is generated iteratively from the first bit. By redesigning the autoregressive method to compute in domains other than the time domain, the number of iterations in the proposed model is no longer proportional to the utterance's length but the number of subbands/bits. The inference efficiency is hence significantly increased. Besides, a post-filter is employed to sample audio signals from output posteriors, and its training objective is designed based on the characteristics of the proposed autoregressive methods. The experimental results show that the proposed model is able to synthesize speech faster than real-time without GPU acceleration. Compared with the baseline autoregressive and non-autoregressive models, the proposed model achieves better MOS and shows its good generalization ability while synthesizing 44 kHz speech or utterances from unseen speakers.
Universal Adaptor: Converting Mel-Spectrograms Between Different Configurations for Speech Synthesis
Apr 01, 2022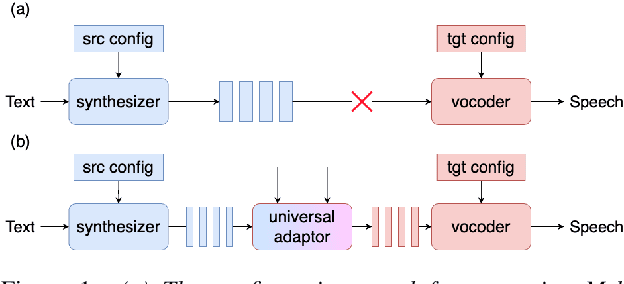

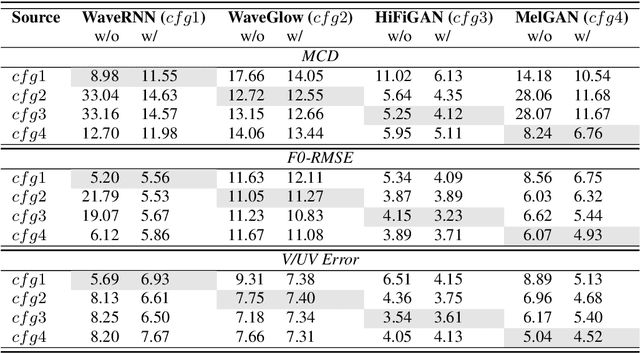
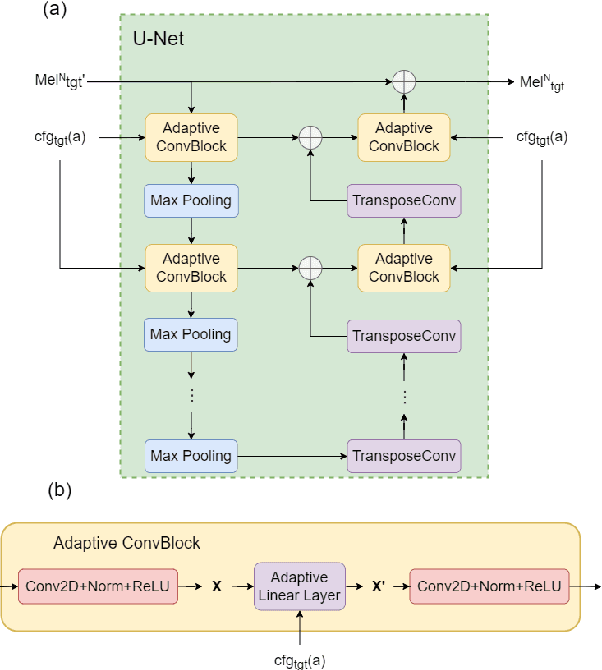
Most recent TTS systems are composed of a synthesizer and a vocoder. However, the existing synthesizers and vocoders can only be matched to acoustic features extracted with a specific configuration. Hence, we can't combine arbitrary synthesizers and vocoders together to form a complete TTS system, not to mention applying to a newly developed model. In this paper, we proposed a universal adaptor, which takes a Mel-spectogram parametrized by the source configuration and converts it into a Mel-spectrogram parametrized by the target configuration, as long as we feed in the source and the target configurations. Experiments show that the quality of speeches synthesized from our output of the universal adaptor is comparable to those synthesized from ground truth Mel-spectrogram. Moreover, our universal adaptor can be applied in the recent TTS systems and in multi-speaker speech synthesis without dropping quality.
Spotting adversarial samples for speaker verification by neural vocoders
Jul 02, 2021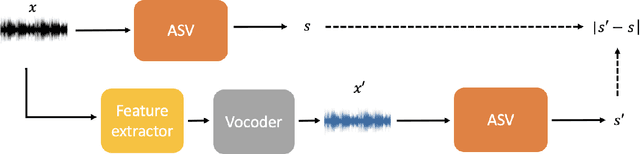
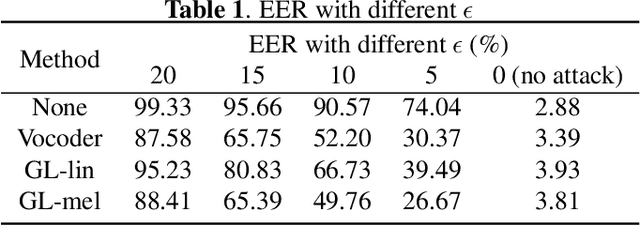
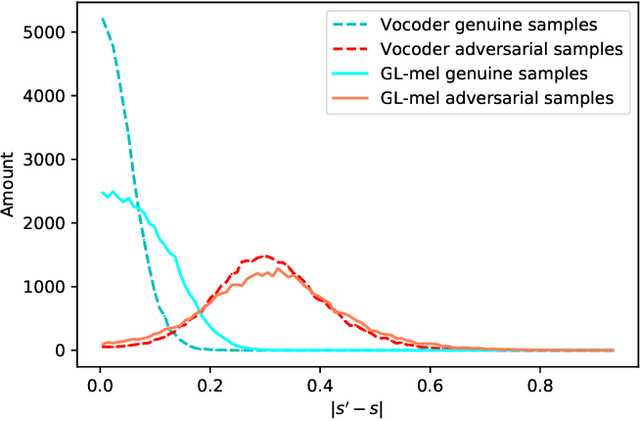
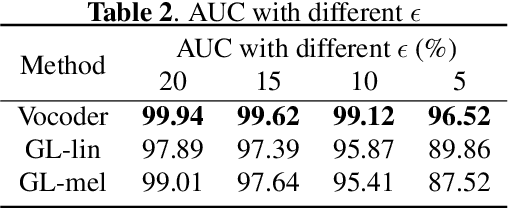
Automatic speaker verification (ASV), one of the most important technology for biometric identification, has been widely adopted in security-critical applications, including transaction authentication and access control. However, previous work has shown that ASV is seriously vulnerable to recently emerged adversarial attacks, yet effective countermeasures against them are limited. In this paper, we adopt neural vocoders to spot adversarial samples for ASV. We use the neural vocoder to re-synthesize audio and find that the difference between the ASV scores for the original and re-synthesized audio is a good indicator for discrimination between genuine and adversarial samples. This effort is, to the best of our knowledge, among the first to pursue such a technical direction for detecting adversarial samples for ASV, and hence there is a lack of established baselines for comparison. Consequently, we implement the Griffin-Lim algorithm as the detection baseline. The proposed approach achieves effective detection performance that outperforms all the baselines in all the settings. We also show that the neural vocoder adopted in the detection framework is dataset-independent. Our codes will be made open-source for future works to do comparison.
Investigating on Incorporating Pretrained and Learnable Speaker Representations for Multi-Speaker Multi-Style Text-to-Speech
Mar 20, 2021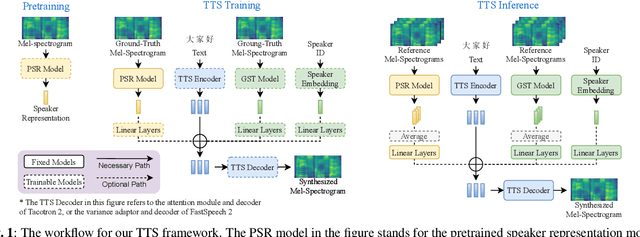
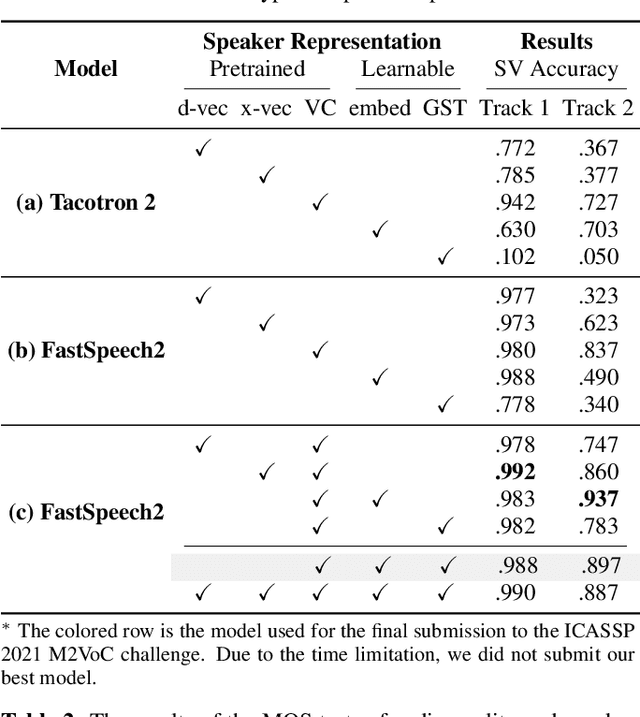
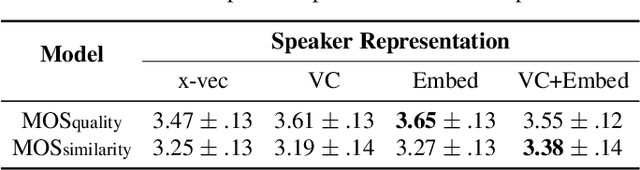

The few-shot multi-speaker multi-style voice cloning task is to synthesize utterances with voice and speaking style similar to a reference speaker given only a few reference samples. In this work, we investigate different speaker representations and proposed to integrate pretrained and learnable speaker representations. Among different types of embeddings, the embedding pretrained by voice conversion achieves the best performance. The FastSpeech 2 model combined with both pretrained and learnable speaker representations shows great generalization ability on few-shot speakers and achieved 2nd place in the one-shot track of the ICASSP 2021 M2VoC challenge.
Towards Robust Neural Vocoding for Speech Generation: A Survey
Dec 05, 2019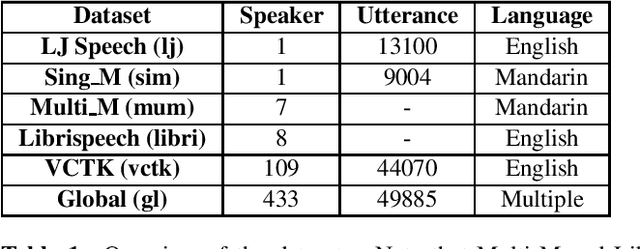

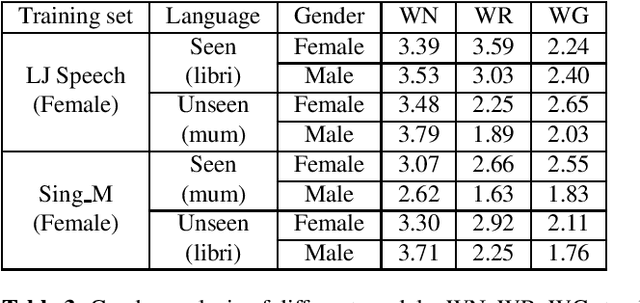
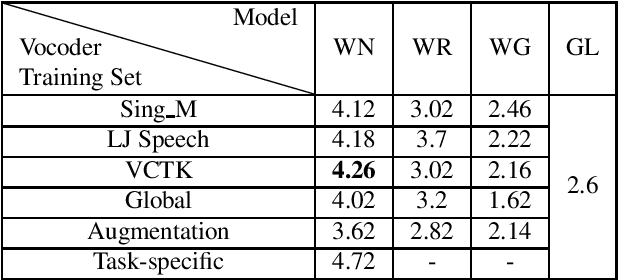
Recently, neural vocoders have been widely used in speech synthesis tasks, including text-to-speech and voice conversion. However, in the encounter of data distribution mismatch between training and inference, neural vocoders trained on real data often degrade in voice quality for unseen scenarios. In this paper, we train three commonly used neural vocoders, including WaveNet, WaveRNN, and WaveGlow, alternately on five different datasets. To study the robustness of neural vocoders, we evaluate the models using acoustic features from seen/unseen speakers, seen/unseen languages, a text-to-speech model, and a voice conversion model. In this work, we found that WaveNet is more robust than WaveRNN, especially in the face of inconsistency between training and testing data. Through our experiments, we show that WaveNet is more suitable for text-to-speech models, and WaveRNN more suitable for voice conversion applications. Furthermore, we present results with considerable reference value of subjective human evaluation for future studies.
Mockingjay: Unsupervised Speech Representation Learning with Deep Bidirectional Transformer Encoders
Oct 25, 2019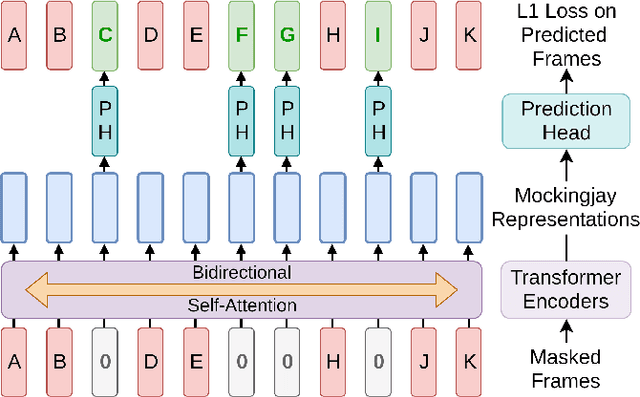
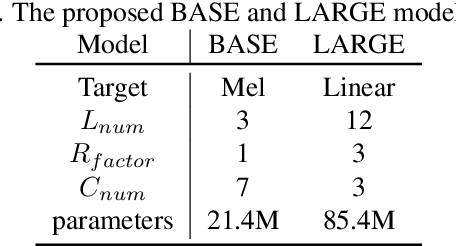
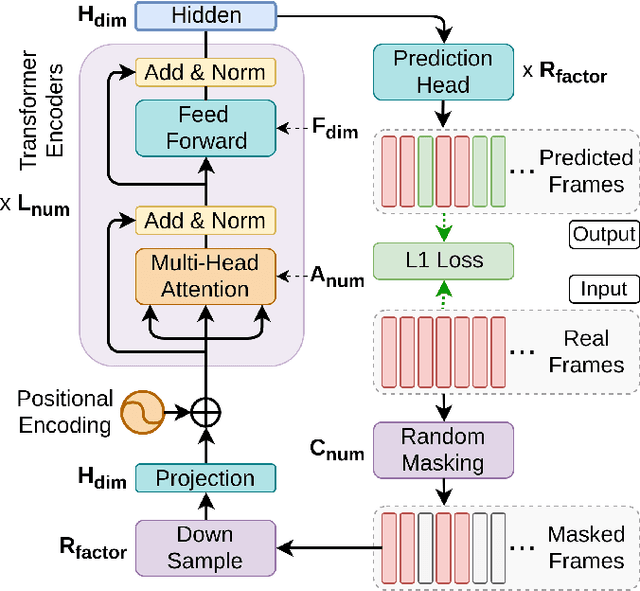
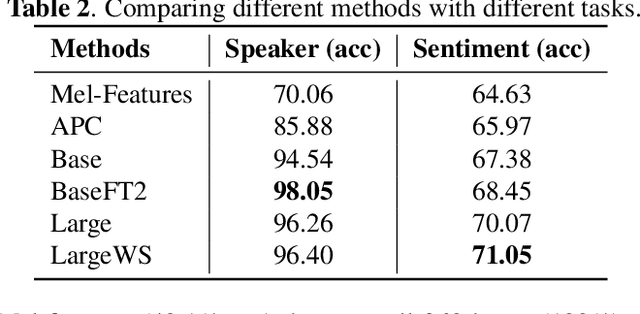
We present Mockingjay as a new speech representation learning approach, where bidirectional Transformer encoders are pre-trained on a large amount of unlabeled speech. Previous speech representation methods learn through conditioning on past frames and predicting information about future frames. Whereas Mockingjay is designed to predict the current frame through jointly conditioning on both past and future contexts. The Mockingjay representation improves performance for a wide range of downstream tasks, including phoneme classification, speaker recognition, and sentiment classification on spoken content, while outperforming other approaches. Mockingjay is empirically powerful and can be fine-tuned with downstream models, with only 2 epochs we further improve performance dramatically. In a low resource setting with only 0.1% of labeled data, we outperform the result of Mel-features that uses all 100% labeled data.