 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
How to Evaluate Semantic Communications for Images with ViTScore Metric?
Sep 09, 2023



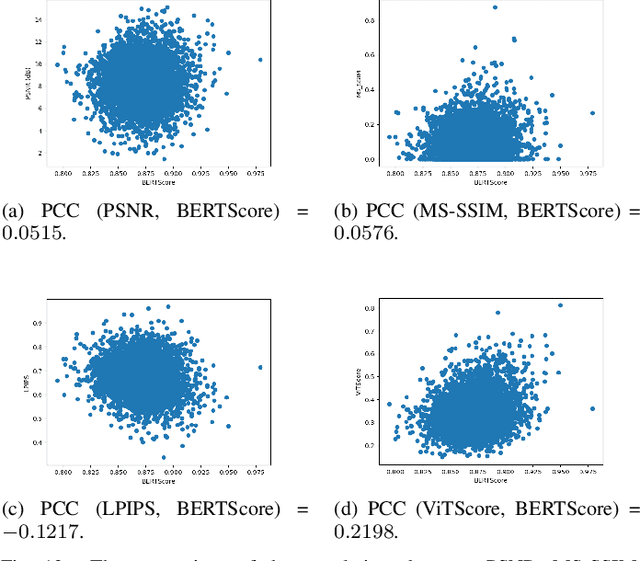
Semantic communications (SC) have been expected to be a new paradigm shifting to catalyze the next generation communication, whose main concerns shift from accurate bit transmission to effective semantic information exchange in communications. However, the previous and widely-used metrics for images are not applicable to evaluate the image semantic similarity in SC. Classical metrics to measure the similarity between two images usually rely on the pixel level or the structural level, such as the PSNR and the MS-SSIM. Straightforwardly using some tailored metrics based on deep-learning methods in CV community, such as the LPIPS, is infeasible for SC. To tackle this, inspired by BERTScore in NLP community, we propose a novel metric for evaluating image semantic similarity, named Vision Transformer Score (ViTScore). We prove theoretically that ViTScore has 3 important properties, including symmetry, boundedness, and normalization, which make ViTScore convenient and intuitive for image measurement. To evaluate the performance of ViTScore, we compare ViTScore with 3 typical metrics (PSNR, MS-SSIM, and LPIPS) through 5 classes of experiments. Experimental results demonstrate that ViTScore can better evaluate the image semantic similarity than the other 3 typical metrics, which indicates that ViTScore is an effective performance metric when deployed in SC scenarios.
EgoBlur: Responsible Innovation in Aria
Sep 06, 2023

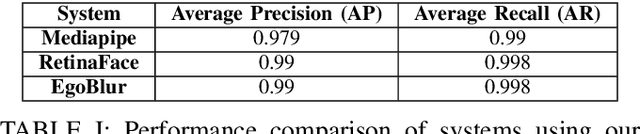
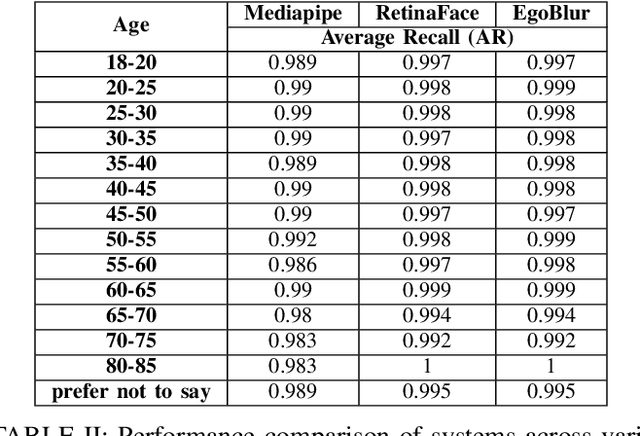
Project Aria pushes the frontiers of Egocentric AI with large-scale real-world data collection using purposely designed glasses with privacy first approach. To protect the privacy of bystanders being recorded by the glasses, our research protocols are designed to ensure recorded video is processed by an AI anonymization model that removes bystander faces and vehicle license plates. Detected face and license plate regions are processed with a Gaussian blur such that these personal identification information (PII) regions are obscured. This process helps to ensure that anonymized versions of the video is retained for research purposes. In Project Aria, we have developed a state-of-the-art anonymization system EgoBlur. In this paper, we present extensive analysis of EgoBlur on challenging datasets comparing its performance with other state-of-the-art systems from industry and academia including extensive Responsible AI analysis on recently released Casual Conversations V2 dataset.
NICE 2023 Zero-shot Image Captioning Challenge
Sep 06, 2023
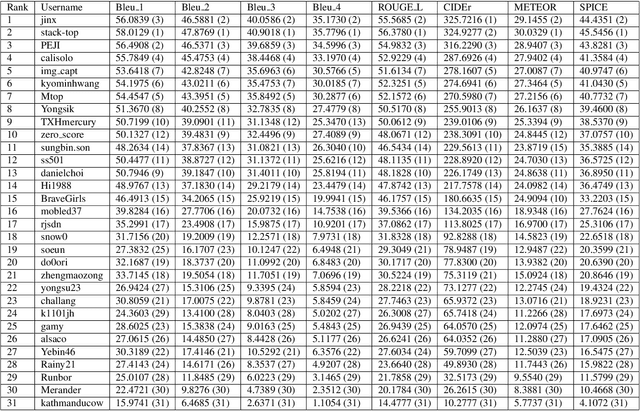
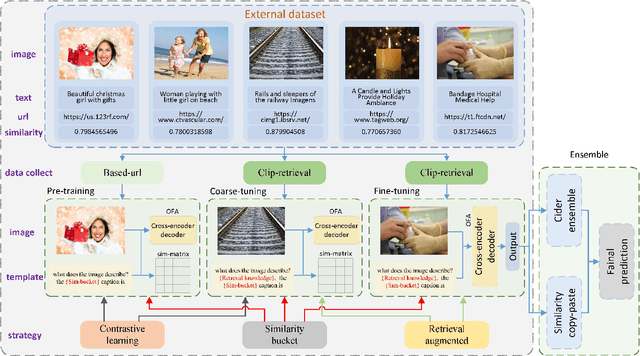
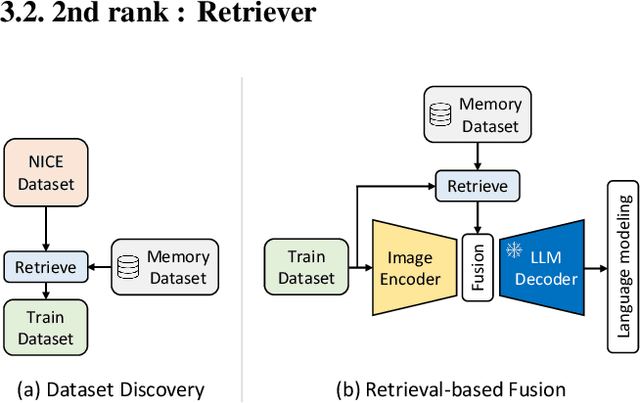
In this report, we introduce NICE project\footnote{\url{https://nice.lgresearch.ai/}} and share the results and outcomes of NICE challenge 2023. This project is designed to challenge the computer vision community to develop robust image captioning models that advance the state-of-the-art both in terms of accuracy and fairness. Through the challenge, the image captioning models were tested using a new evaluation dataset that includes a large variety of visual concepts from many domains. There was no specific training data provided for the challenge, and therefore the challenge entries were required to adapt to new types of image descriptions that had not been seen during training. This report includes information on the newly proposed NICE dataset, evaluation methods, challenge results, and technical details of top-ranking entries. We expect that the outcomes of the challenge will contribute to the improvement of AI models on various vision-language tasks.
3D Trajectory Reconstruction of Drones using a Single Camera
Sep 06, 2023Drones have been widely utilized in various fields, but the number of drones being used illegally and for hazardous purposes has increased recently. To prevent those illegal drones, in this work, we propose a novel framework for reconstructing 3D trajectories of drones using a single camera. By leveraging calibrated cameras, we exploit the relationship between 2D and 3D spaces. We automatically track the drones in 2D images using the drone tracker and estimate their 2D rotations. By combining the estimated 2D drone positions with their actual length information and camera parameters, we geometrically infer the 3D trajectories of the drones. To address the lack of public drone datasets, we also create synthetic 2D and 3D drone datasets. The experimental results show that the proposed methods accurately reconstruct drone trajectories in 3D space, and demonstrate the potential of our framework for single camera-based surveillance systems.
Sensing With Random Signals
Sep 06, 2023Radar systems typically employ well-designed deterministic signals for target sensing. In contrast to that, integrated sensing and communications (ISAC) systems have to use random signals to convey useful information, potentially causing sensing performance degradation. This paper analyzes the sensing performance via random ISAC signals over a multi-antenna system. Towards this end, we define a new sensing performance metric, namely, ergodic linear minimum mean square error (ELMMSE), which characterizes the estimation error averaged over the randomness of ISAC signals. Then, we investigate a data-dependent precoding scheme to minimize the ELMMSE, which attains the {optimized} sensing performance at the price of high computational complexity. To reduce the complexity, we present an alternative data-independent precoding scheme and propose a stochastic gradient projection (SGP) algorithm for ELMMSE minimization, which can be trained offline by locally generated signal samples. Finally, we demonstrate the superiority of the proposed methods by simulations.
Gall Bladder Cancer Detection from US Images with Only Image Level Labels
Sep 11, 2023
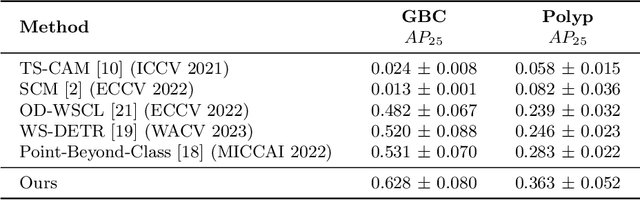
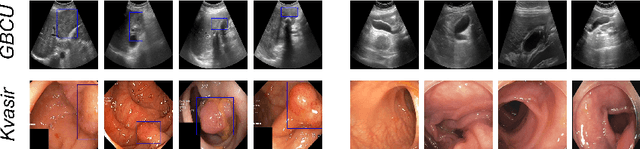

Automated detection of Gallbladder Cancer (GBC) from Ultrasound (US) images is an important problem, which has drawn increased interest from researchers. However, most of these works use difficult-to-acquire information such as bounding box annotations or additional US videos. In this paper, we focus on GBC detection using only image-level labels. Such annotation is usually available based on the diagnostic report of a patient, and do not require additional annotation effort from the physicians. However, our analysis reveals that it is difficult to train a standard image classification model for GBC detection. This is due to the low inter-class variance (a malignant region usually occupies only a small portion of a US image), high intra-class variance (due to the US sensor capturing a 2D slice of a 3D object leading to large viewpoint variations), and low training data availability. We posit that even when we have only the image level label, still formulating the problem as object detection (with bounding box output) helps a deep neural network (DNN) model focus on the relevant region of interest. Since no bounding box annotations is available for training, we pose the problem as weakly supervised object detection (WSOD). Motivated by the recent success of transformer models in object detection, we train one such model, DETR, using multi-instance-learning (MIL) with self-supervised instance selection to suit the WSOD task. Our proposed method demonstrates an improvement of AP and detection sensitivity over the SOTA transformer-based and CNN-based WSOD methods. Project page is at https://gbc-iitd.github.io/wsod-gbc
UniKG: A Benchmark and Universal Embedding for Large-Scale Knowledge Graphs
Sep 11, 2023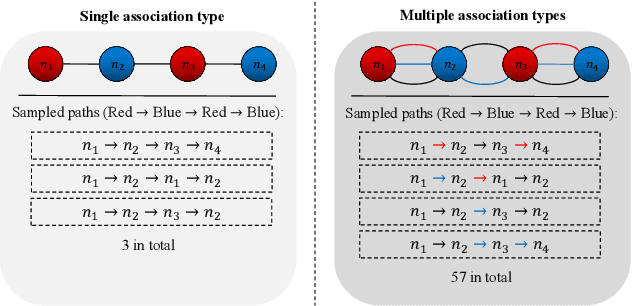
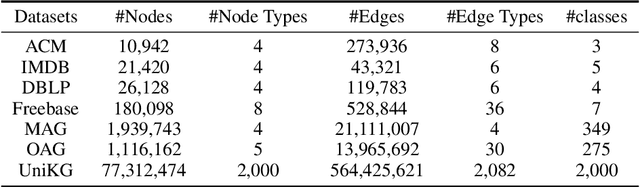
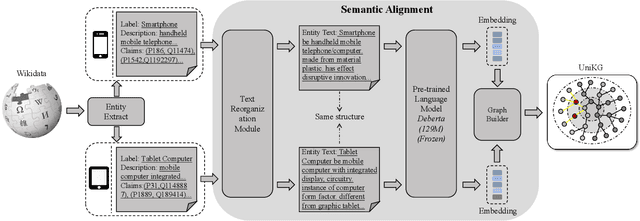
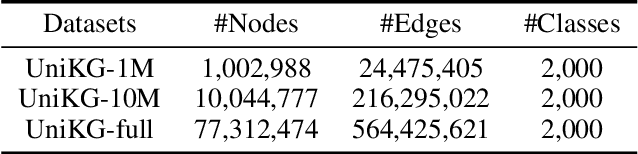
Irregular data in real-world are usually organized as heterogeneous graphs (HGs) consisting of multiple types of nodes and edges. To explore useful knowledge from real-world data, both the large-scale encyclopedic HG datasets and corresponding effective learning methods are crucial, but haven't been well investigated. In this paper, we construct a large-scale HG benchmark dataset named UniKG from Wikidata to facilitate knowledge mining and heterogeneous graph representation learning. Overall, UniKG contains more than 77 million multi-attribute entities and 2000 diverse association types, which significantly surpasses the scale of existing HG datasets. To perform effective learning on the large-scale UniKG, two key measures are taken, including (i) the semantic alignment strategy for multi-attribute entities, which projects the feature description of multi-attribute nodes into a common embedding space to facilitate node aggregation in a large receptive field; (ii) proposing a novel plug-and-play anisotropy propagation module (APM) to learn effective multi-hop anisotropy propagation kernels, which extends methods of large-scale homogeneous graphs to heterogeneous graphs. These two strategies enable efficient information propagation among a tremendous number of multi-attribute entities and meantimes adaptively mine multi-attribute association through the multi-hop aggregation in large-scale HGs. We set up a node classification task on our UniKG dataset, and evaluate multiple baseline methods which are constructed by embedding our APM into large-scale homogenous graph learning methods. Our UniKG dataset and the baseline codes have been released at https://github.com/Yide-Qiu/UniKG.
Multi-stage Factorized Spatio-Temporal Representation for RGB-D Action and Gesture Recognition
Sep 11, 2023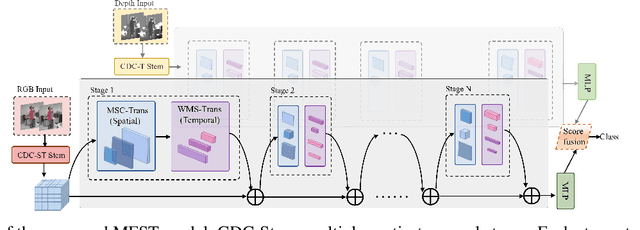
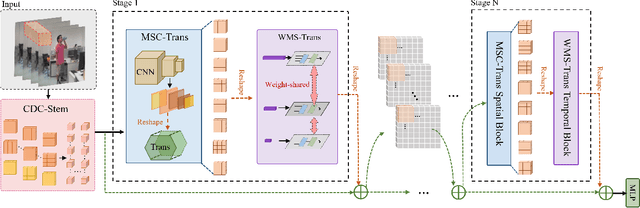
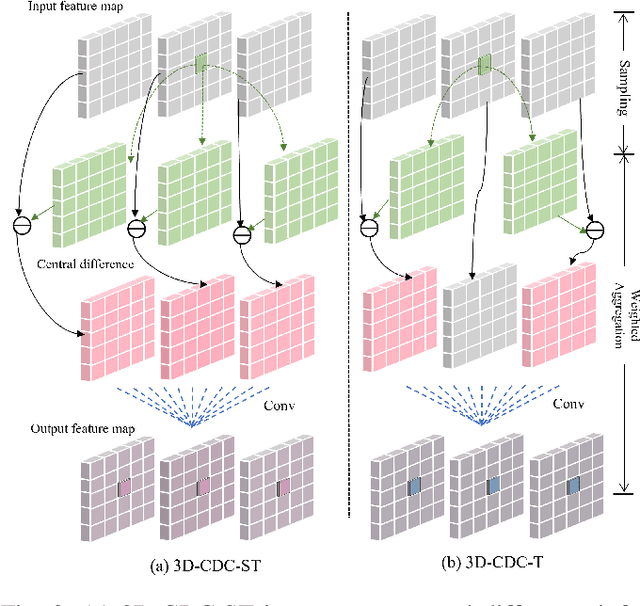
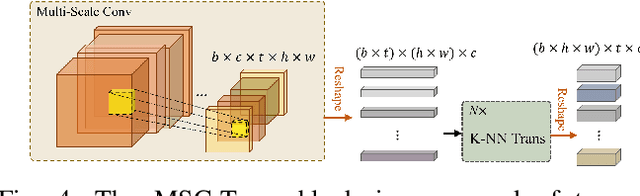
RGB-D action and gesture recognition remain an interesting topic in human-centered scene understanding, primarily due to the multiple granularities and large variation in human motion. Although many RGB-D based action and gesture recognition approaches have demonstrated remarkable results by utilizing highly integrated spatio-temporal representations across multiple modalities (i.e., RGB and depth data), they still encounter several challenges. Firstly, vanilla 3D convolution makes it hard to capture fine-grained motion differences between local clips under different modalities. Secondly, the intricate nature of highly integrated spatio-temporal modeling can lead to optimization difficulties. Thirdly, duplicate and unnecessary information can add complexity and complicate entangled spatio-temporal modeling. To address the above issues, we propose an innovative heuristic architecture called Multi-stage Factorized Spatio-Temporal (MFST) for RGB-D action and gesture recognition. The proposed MFST model comprises a 3D Central Difference Convolution Stem (CDC-Stem) module and multiple factorized spatio-temporal stages. The CDC-Stem enriches fine-grained temporal perception, and the multiple hierarchical spatio-temporal stages construct dimension-independent higher-order semantic primitives. Specifically, the CDC-Stem module captures bottom-level spatio-temporal features and passes them successively to the following spatio-temporal factored stages to capture the hierarchical spatial and temporal features through the Multi- Scale Convolution and Transformer (MSC-Trans) hybrid block and Weight-shared Multi-Scale Transformer (WMS-Trans) block. The seamless integration of these innovative designs results in a robust spatio-temporal representation that outperforms state-of-the-art approaches on RGB-D action and gesture recognition datasets.
VIGC: Visual Instruction Generation and Correction
Sep 11, 2023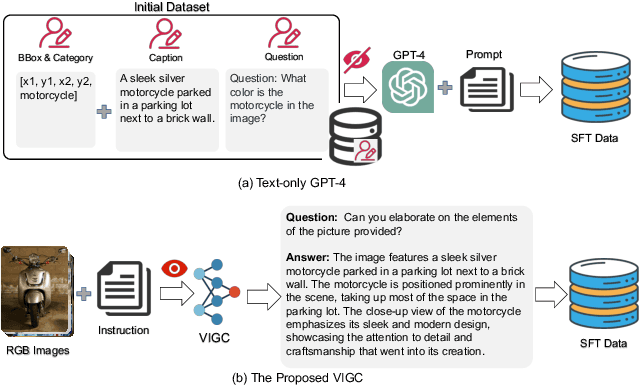
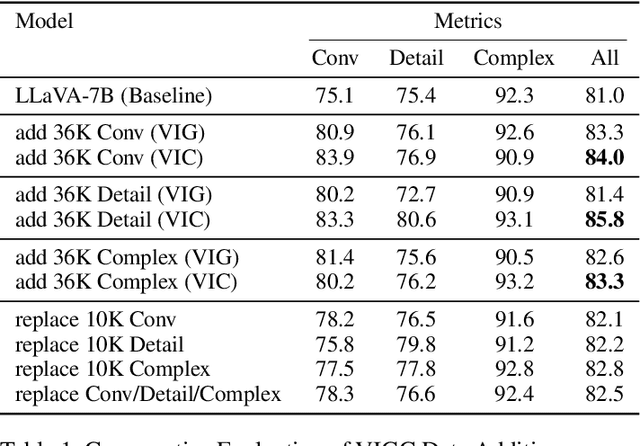
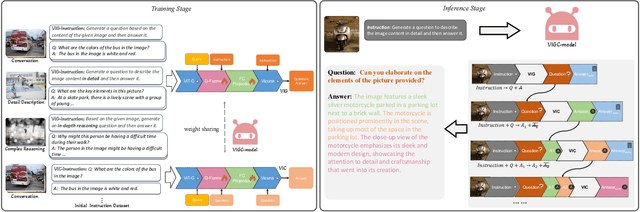

The integration of visual encoders and large language models (LLMs) has driven recent progress in multimodal large language models (MLLMs). However, the scarcity of high-quality instruction-tuning data for vision-language tasks remains a challenge. The current leading paradigm, such as LLaVA, relies on language-only GPT-4 to generate data, which requires pre-annotated image captions and detection bounding boxes, suffering from understanding image details. A practical solution to this problem would be to utilize the available multimodal large language models (MLLMs) to generate instruction data for vision-language tasks. However, it's worth noting that the currently accessible MLLMs are not as powerful as their LLM counterparts, as they tend to produce inadequate responses and generate false information. As a solution for addressing the current issue, this paper proposes the Visual Instruction Generation and Correction (VIGC) framework that enables multimodal large language models to generate instruction-tuning data and progressively enhance its quality on-the-fly. Specifically, Visual Instruction Generation (VIG) guides the vision-language model to generate diverse instruction-tuning data. To ensure generation quality, Visual Instruction Correction (VIC) adopts an iterative update mechanism to correct any inaccuracies in data produced by VIG, effectively reducing the risk of hallucination. Leveraging the diverse, high-quality data generated by VIGC, we finetune mainstream models and validate data quality based on various evaluations. Experimental results demonstrate that VIGC not only compensates for the shortcomings of language-only data generation methods, but also effectively enhances the benchmark performance. The models, datasets, and code are available at https://opendatalab.github.io/VIGC.
Using Unsupervised and Supervised Learning and Digital Twin for Deep Convective Ice Storm Classification
Sep 12, 2023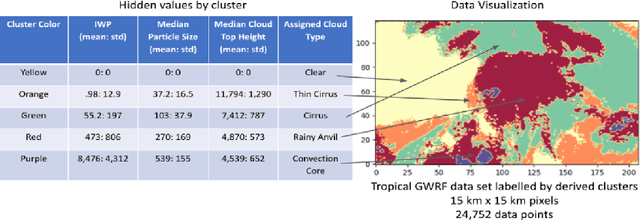
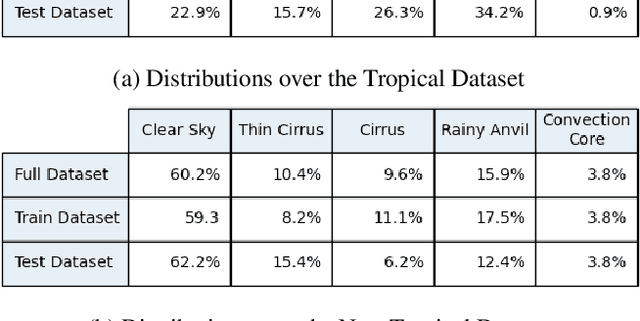
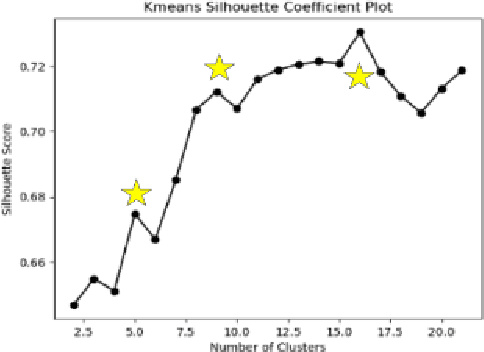
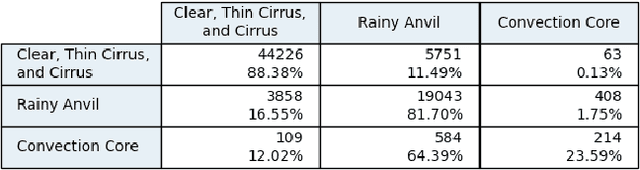
Smart Ice Cloud Sensing (SMICES) is a small-sat concept in which a primary radar intelligently targets ice storms based on information collected by a lookahead radiometer. Critical to the intelligent targeting is accurate identification of storm/cloud types from eight bands of radiance collected by the radiometer. The cloud types of interest are: clear sky, thin cirrus, cirrus, rainy anvil, and convection core. We describe multi-step use of Machine Learning and Digital Twin of the Earth's atmosphere to derive such a classifier. First, a digital twin of Earth's atmosphere called a Weather Research Forecast (WRF) is used generate simulated lookahead radiometer data as well as deeper "science" hidden variables. The datasets simulate a tropical region over the Caribbean and a non-tropical region over the Atlantic coast of the United States. A K-means clustering over the scientific hidden variables was utilized by human experts to generate an automatic labelling of the data - mapping each physical data point to cloud types by scientists informed by mean/centroids of hidden variables of the clusters. Next, classifiers were trained with the inputs of the simulated radiometer data and its corresponding label. The classifiers of a random decision forest (RDF), support vector machine (SVM), Gaussian na\"ive bayes, feed forward artificial neural network (ANN), and a convolutional neural network (CNN) were trained. Over the tropical dataset, the best performing classifier was able to identify non-storm and storm clouds with over 80% accuracy in each class for a held-out test set. Over the non-tropical dataset, the best performing classifier was able to classify non-storm clouds with over 90% accuracy and storm clouds with over 40% accuracy. Additionally both sets of classifiers were shown to be resilient to instrument noise.