 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabeled TrustSet Guided: Batch Active Learning with Reinforcement Learning
Apr 14, 2026Batch active learning (BAL) is a crucial technique for reducing labeling costs and improving data efficiency in training large-scale deep learning models. Traditional BAL methods often rely on metrics like Mahalanobis Distance to balance uncertainty and diversity when selecting data for annotation. However, these methods predominantly focus on the distribution of unlabeled data and fail to leverage feedback from labeled data or the model's performance. To address these limitations, we introduce TrustSet, a novel approach that selects the most informative data from the labeled dataset, ensuring a balanced class distribution to mitigate the long-tail problem. Unlike CoreSet, which focuses on maintaining the overall data distribution, TrustSet optimizes the model's performance by pruning redundant data and using label information to refine the selection process. To extend the benefits of TrustSet to the unlabeled pool, we propose a reinforcement learning (RL)-based sampling policy that approximates the selection of high-quality TrustSet candidates from the unlabeled data. Combining TrustSet and RL, we introduce the Batch Reinforcement Active Learning with TrustSet (BRAL-T) framework. BRAL-T achieves state-of-the-art results across 10 image classification benchmarks and 2 active fine-tuning tasks, demonstrating its effectiveness and efficiency in various domains.
Ctrl&Shift: High-Quality Geometry-Aware Object Manipulation in Visual Generation
Feb 11, 2026Object-level manipulation, relocating or reorienting objects in images or videos while preserving scene realism, is central to film post-production, AR, and creative editing. Yet existing methods struggle to jointly achieve three core goals: background preservation, geometric consistency under viewpoint shifts, and user-controllable transformations. Geometry-based approaches offer precise control but require explicit 3D reconstruction and generalize poorly; diffusion-based methods generalize better but lack fine-grained geometric control. We present Ctrl&Shift, an end-to-end diffusion framework to achieve geometry-consistent object manipulation without explicit 3D representations. Our key insight is to decompose manipulation into two stages, object removal and reference-guided inpainting under explicit camera pose control, and encode both within a unified diffusion process. To enable precise, disentangled control, we design a multi-task, multi-stage training strategy that separates background, identity, and pose signals across tasks. To improve generalization, we introduce a scalable real-world dataset construction pipeline that generates paired image and video samples with estimated relative camera poses. Extensive experiments demonstrate that Ctrl&Shift achieves state-of-the-art results in fidelity, viewpoint consistency, and controllability. To our knowledge, this is the first framework to unify fine-grained geometric control and real-world generalization for object manipulation, without relying on any explicit 3D modeling.
Closing the Confusion Loop: CLIP-Guided Alignment for Source-Free Domain Adaptation
Feb 09, 2026Source-Free Domain Adaptation (SFDA) tackles the problem of adapting a pre-trained source model to an unlabeled target domain without accessing any source data, which is quite suitable for the field of data security. Although recent advances have shown that pseudo-labeling strategies can be effective, they often fail in fine-grained scenarios due to subtle inter-class similarities. A critical but underexplored issue is the presence of asymmetric and dynamic class confusion, where visually similar classes are unequally and inconsistently misclassified by the source model. Existing methods typically ignore such confusion patterns, leading to noisy pseudo-labels and poor target discrimination. To address this, we propose CLIP-Guided Alignment(CGA), a novel framework that explicitly models and mitigates class confusion in SFDA. Generally, our method consists of three parts: (1) MCA: detects first directional confusion pairs by analyzing the predictions of the source model in the target domain; (2) MCC: leverages CLIP to construct confusion-aware textual prompts (e.g. a truck that looks like a bus), enabling more context-sensitive pseudo-labeling; and (3) FAM: builds confusion-guided feature banks for both CLIP and the source model and aligns them using contrastive learning to reduce ambiguity in the representation space. Extensive experiments on various datasets demonstrate that CGA consistently outperforms state-of-the-art SFDA methods, with especially notable gains in confusion-prone and fine-grained scenarios. Our results highlight the importance of explicitly modeling inter-class confusion for effective source-free adaptation. Our code can be find at https://github.com/soloiro/CGA
H$_{2}$OT: Hierarchical Hourglass Tokenizer for Efficient Video Pose Transformers
Sep 08, 2025



Transformers have been successfully applied in the field of video-based 3D human pose estimation. However, the high computational costs of these video pose transformers (VPTs) make them impractical on resource-constrained devices. In this paper, we present a hierarchical plug-and-play pruning-and-recovering framework, called Hierarchical Hourglass Tokenizer (H$_{2}$OT), for efficient transformer-based 3D human pose estimation from videos. H$_{2}$OT begins with progressively pruning pose tokens of redundant frames and ends with recovering full-length sequences, resulting in a few pose tokens in the intermediate transformer blocks and thus improving the model efficiency. It works with two key modules, namely, a Token Pruning Module (TPM) and a Token Recovering Module (TRM). TPM dynamically selects a few representative tokens to eliminate the redundancy of video frames, while TRM restores the detailed spatio-temporal information based on the selected tokens, thereby expanding the network output to the original full-length temporal resolution for fast inference. Our method is general-purpose: it can be easily incorporated into common VPT models on both seq2seq and seq2frame pipelines while effectively accommodating different token pruning and recovery strategies. In addition, our H$_{2}$OT reveals that maintaining the full pose sequence is unnecessary, and a few pose tokens of representative frames can achieve both high efficiency and estimation accuracy. Extensive experiments on multiple benchmark datasets demonstrate both the effectiveness and efficiency of the proposed method. Code and models are available at https://github.com/NationalGAILab/HoT.
Training-Free Text-Guided Image Editing with Visual Autoregressive Model
Mar 31, 2025Text-guided image editing is an essential task that enables users to modify images through natural language descriptions. Recent advances in diffusion models and rectified flows have significantly improved editing quality, primarily relying on inversion techniques to extract structured noise from input images. However, inaccuracies in inversion can propagate errors, leading to unintended modifications and compromising fidelity. Moreover, even with perfect inversion, the entanglement between textual prompts and image features often results in global changes when only local edits are intended. To address these challenges, we propose a novel text-guided image editing framework based on VAR (Visual AutoRegressive modeling), which eliminates the need for explicit inversion while ensuring precise and controlled modifications. Our method introduces a caching mechanism that stores token indices and probability distributions from the original image, capturing the relationship between the source prompt and the image. Using this cache, we design an adaptive fine-grained masking strategy that dynamically identifies and constrains modifications to relevant regions, preventing unintended changes. A token reassembling approach further refines the editing process, enhancing diversity, fidelity, and control. Our framework operates in a training-free manner and achieves high-fidelity editing with faster inference speeds, processing a 1K resolution image in as fast as 1.2 seconds. Extensive experiments demonstrate that our method achieves performance comparable to, or even surpassing, existing diffusion- and rectified flow-based approaches in both quantitative metrics and visual quality. The code will be released.
CRPO: Confidence-Reward Driven Preference Optimization for Machine Translation
Jan 23, 2025



Large language models (LLMs) have shown great potential in natural language processing tasks, but their application to machine translation (MT) remains challenging due to pretraining on English-centric data and the complexity of reinforcement learning from human feedback (RLHF). Direct Preference Optimization (DPO) has emerged as a simpler and more efficient alternative, but its performance depends heavily on the quality of preference data. To address this, we propose Confidence-Reward driven Preference Optimization (CRPO), a novel method that combines reward scores with model confidence to improve data selection for fine-tuning. CRPO selects challenging sentence pairs where the model is uncertain or underperforms, leading to more effective learning. While primarily designed for LLMs, CRPO also generalizes to encoder-decoder models like NLLB, demonstrating its versatility. Empirical results show that CRPO outperforms existing methods such as RS-DPO, RSO and MBR score in both translation accuracy and data efficiency.
Beyond Speaker Identity: Text Guided Target Speech Extraction
Jan 15, 2025Target Speech Extraction (TSE) traditionally relies on explicit clues about the speaker's identity like enrollment audio, face images, or videos, which may not always be available. In this paper, we propose a text-guided TSE model StyleTSE that uses natural language descriptions of speaking style in addition to the audio clue to extract the desired speech from a given mixture. Our model integrates a speech separation network adapted from SepFormer with a bi-modality clue network that flexibly processes both audio and text clues. To train and evaluate our model, we introduce a new dataset TextrolMix with speech mixtures and natural language descriptions. Experimental results demonstrate that our method effectively separates speech based not only on who is speaking, but also on how they are speaking, enhancing TSE in scenarios where traditional audio clues are absent. Demos are at: https://mingyue66.github.io/TextrolMix/demo/
FlexDiT: Dynamic Token Density Control for Diffusion Transformer
Dec 08, 2024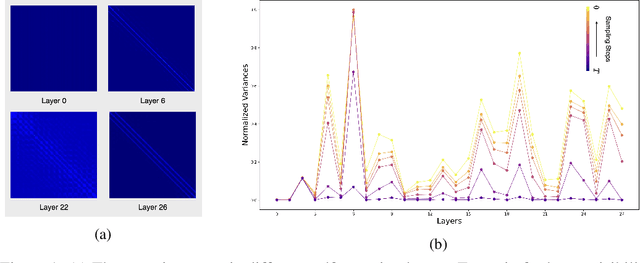
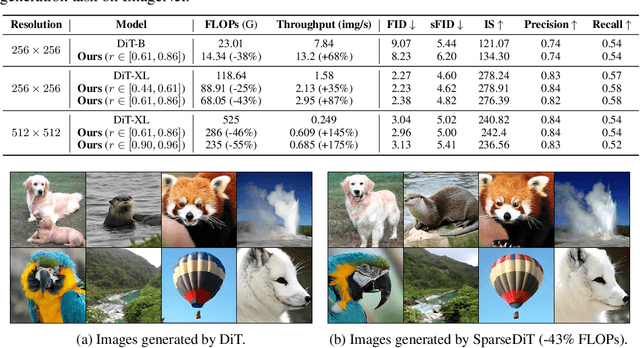
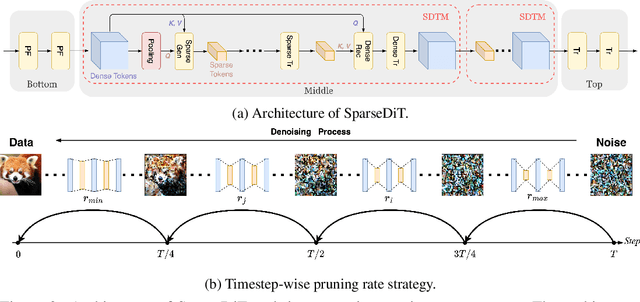

Diffusion Transformers (DiT) deliver impressive generative performance but face prohibitive computational demands due to both the quadratic complexity of token-based self-attention and the need for extensive sampling steps. While recent research has focused on accelerating sampling, the structural inefficiencies of DiT remain underexplored. We propose FlexDiT, a framework that dynamically adapts token density across both spatial and temporal dimensions to achieve computational efficiency without compromising generation quality. Spatially, FlexDiT employs a three-segment architecture that allocates token density based on feature requirements at each layer: Poolingformer in the bottom layers for efficient global feature extraction, Sparse-Dense Token Modules (SDTM) in the middle layers to balance global context with local detail, and dense tokens in the top layers to refine high-frequency details. Temporally, FlexDiT dynamically modulates token density across denoising stages, progressively increasing token count as finer details emerge in later timesteps. This synergy between FlexDiT's spatially adaptive architecture and its temporal pruning strategy enables a unified framework that balances efficiency and fidelity throughout the generation process. Our experiments demonstrate FlexDiT's effectiveness, achieving a 55% reduction in FLOPs and a 175% improvement in inference speed on DiT-XL with only a 0.09 increase in FID score on 512$\times$512 ImageNet images, a 56% reduction in FLOPs across video generation datasets including FaceForensics, SkyTimelapse, UCF101, and Taichi-HD, and a 69% improvement in inference speed on PixArt-$\alpha$ on text-to-image generation task with a 0.24 FID score decrease. FlexDiT provides a scalable solution for high-quality diffusion-based generation compatible with further sampling optimization techniques.
Factorized Visual Tokenization and Generation
Nov 25, 2024



Visual tokenizers are fundamental to image generation. They convert visual data into discrete tokens, enabling transformer-based models to excel at image generation. Despite their success, VQ-based tokenizers like VQGAN face significant limitations due to constrained vocabulary sizes. Simply expanding the codebook often leads to training instability and diminishing performance gains, making scalability a critical challenge. In this work, we introduce Factorized Quantization (FQ), a novel approach that revitalizes VQ-based tokenizers by decomposing a large codebook into multiple independent sub-codebooks. This factorization reduces the lookup complexity of large codebooks, enabling more efficient and scalable visual tokenization. To ensure each sub-codebook captures distinct and complementary information, we propose a disentanglement regularization that explicitly reduces redundancy, promoting diversity across the sub-codebooks. Furthermore, we integrate representation learning into the training process, leveraging pretrained vision models like CLIP and DINO to infuse semantic richness into the learned representations. This design ensures our tokenizer captures diverse semantic levels, leading to more expressive and disentangled representations. Experiments show that the proposed FQGAN model substantially improves the reconstruction quality of visual tokenizers, achieving state-of-the-art performance. We further demonstrate that this tokenizer can be effectively adapted into auto-regressive image generation. https://showlab.github.io/FQGAN
Enhancing Motion in Text-to-Video Generation with Decomposed Encoding and Conditioning
Oct 31, 2024



Despite advancements in Text-to-Video (T2V) generation, producing videos with realistic motion remains challenging. Current models often yield static or minimally dynamic outputs, failing to capture complex motions described by text. This issue stems from the internal biases in text encoding, which overlooks motions, and inadequate conditioning mechanisms in T2V generation models. To address this, we propose a novel framework called DEcomposed MOtion (DEMO), which enhances motion synthesis in T2V generation by decomposing both text encoding and conditioning into content and motion components. Our method includes a content encoder for static elements and a motion encoder for temporal dynamics, alongside separate content and motion conditioning mechanisms. Crucially, we introduce text-motion and video-motion supervision to improve the model's understanding and generation of motion. Evaluations on benchmarks such as MSR-VTT, UCF-101, WebVid-10M, EvalCrafter, and VBench demonstrate DEMO's superior ability to produce videos with enhanced motion dynamics while maintaining high visual quality. Our approach significantly advances T2V generation by integrating comprehensive motion understanding directly from textual descriptions. Project page: https://PR-Ryan.github.io/DEMO-project/