 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinerU2.5-Pro: Pushing the Limits of Data-Centric Document Parsing at Scale
Apr 06, 2026Current document parsing methods compete primarily on model architecture innovation, while systematic engineering of training data remains underexplored. Yet SOTA models of different architectures and parameter scales exhibit highly consistent failure patterns on the same set of hard samples, suggesting that the performance bottleneck stems from shared deficiencies in training data rather than architecture itself. Building on this finding, we present \minerupro, which advances the state of the art solely through data engineering and training strategy optimization while keeping the 1.2B-parameter architecture of \mineru completely fixed. At its core is a Data Engine co-designed around coverage, informativeness, and annotation accuracy: Diversity-and-Difficulty-Aware Sampling expands training data from under 10M to 65.5M samples while correcting distribution shift; Cross-Model Consistency Verification leverages output agreement among heterogeneous models to assess sample difficulty and generate reliable annotations; the Judge-and-Refine pipeline improves annotation quality for hard samples through render-then-verify iterative correction. A three-stage progressive training strategy -- large-scale pre-training, hard sample fine-tuning, and GRPO alignment -- sequentially exploits these data at different quality tiers. On the evaluation front, we fix element-matching biases in OmniDocBench~v1.5 and introduce a Hard subset, establishing the more discriminative OmniDocBench~v1.6 protocol. Without any architectural modification, \minerupro achieves 95.69 on OmniDocBench~v1.6, improving over the same-architecture baseline by 2.71 points and surpassing all existing methods including models with over 200$\times$ more parameters.
AgenticOCR: Parsing Only What You Need for Efficient Retrieval-Augmented Generation
Feb 27, 2026The expansion of retrieval-augmented generation (RAG) into multimodal domains has intensified the challenge for processing complex visual documents, such as financial reports. While page-level chunking and retrieval is a natural starting point, it creates a critical bottleneck: delivering entire pages to the generator introduces excessive extraneous context. This not only overloads the generator's attention mechanism but also dilutes the most salient evidence. Moreover, compressing these information-rich pages into a limited visual token budget further increases the risk of hallucinations. To address this, we introduce AgenticOCR, a dynamic parsing paradigm that transforms optical character recognition (OCR) from a static, full-text process into a query-driven, on-demand extraction system. By autonomously analyzing document layout in a "thinking with images" manner, AgenticOCR identifies and selectively recognizes regions of interest. This approach performs on-demand decompression of visual tokens precisely where needed, effectively decoupling retrieval granularity from rigid page-level chunking. AgenticOCR has the potential to serve as the "third building block" of the visual document RAG stack, operating alongside and enhancing standard Embedding and Reranking modules. Experimental results demonstrate that AgenticOCR improves both the efficiency and accuracy of visual RAG systems, achieving expert-level performance in long document understanding. Code and models are available at https://github.com/OpenDataLab/AgenticOCR.
Not All Documents Are What You Need for Extracting Instruction Tuning Data
May 18, 2025Instruction tuning improves the performance of large language models (LLMs), but it heavily relies on high-quality training data. Recently, LLMs have been used to synthesize instruction data using seed question-answer (QA) pairs. However, these synthesized instructions often lack diversity and tend to be similar to the input seeds, limiting their applicability in real-world scenarios. To address this, we propose extracting instruction tuning data from web corpora that contain rich and diverse knowledge. A naive solution is to retrieve domain-specific documents and extract all QA pairs from them, but this faces two key challenges: (1) extracting all QA pairs using LLMs is prohibitively expensive, and (2) many extracted QA pairs may be irrelevant to the downstream tasks, potentially degrading model performance. To tackle these issues, we introduce EQUAL, an effective and scalable data extraction framework that iteratively alternates between document selection and high-quality QA pair extraction to enhance instruction tuning. EQUAL first clusters the document corpus based on embeddings derived from contrastive learning, then uses a multi-armed bandit strategy to efficiently identify clusters that are likely to contain valuable QA pairs. This iterative approach significantly reduces computational cost while boosting model performance. Experiments on AutoMathText and StackOverflow across four downstream tasks show that EQUAL reduces computational costs by 5-10x and improves accuracy by 2.5 percent on LLaMA-3.1-8B and Mistral-7B
Harnessing Diversity for Important Data Selection in Pretraining Large Language Models
Sep 25, 2024


Data selection is of great significance in pre-training large language models, given the variation in quality within the large-scale available training corpora. To achieve this, researchers are currently investigating the use of data influence to measure the importance of data instances, $i.e.,$ a high influence score indicates that incorporating this instance to the training set is likely to enhance the model performance. Consequently, they select the top-$k$ instances with the highest scores. However, this approach has several limitations. (1) Computing the influence of all available data is time-consuming. (2) The selected data instances are not diverse enough, which may hinder the pre-trained model's ability to generalize effectively to various downstream tasks. In this paper, we introduce \texttt{Quad}, a data selection approach that considers both quality and diversity by using data influence to achieve state-of-the-art pre-training results. In particular, noting that attention layers capture extensive semantic details, we have adapted the accelerated $iHVP$ computation methods for attention layers, enhancing our ability to evaluate the influence of data, $i.e.,$ its quality. For the diversity, \texttt{Quad} clusters the dataset into similar data instances within each cluster and diverse instances across different clusters. For each cluster, if we opt to select data from it, we take some samples to evaluate the influence to prevent processing all instances. To determine which clusters to select, we utilize the classic Multi-Armed Bandit method, treating each cluster as an arm. This approach favors clusters with highly influential instances (ensuring high quality) or clusters that have been selected less frequently (ensuring diversity), thereby well balancing between quality and diversity.
CrossViewDiff: A Cross-View Diffusion Model for Satellite-to-Street View Synthesis
Aug 27, 2024



Satellite-to-street view synthesis aims at generating a realistic street-view image from its corresponding satellite-view image. Although stable diffusion models have exhibit remarkable performance in a variety of image generation applications, their reliance on similar-view inputs to control the generated structure or texture restricts their application to the challenging cross-view synthesis task. In this work, we propose CrossViewDiff, a cross-view diffusion model for satellite-to-street view synthesis. To address the challenges posed by the large discrepancy across views, we design the satellite scene structure estimation and cross-view texture mapping modules to construct the structural and textural controls for street-view image synthesis. We further design a cross-view control guided denoising process that incorporates the above controls via an enhanced cross-view attention module. To achieve a more comprehensive evaluation of the synthesis results, we additionally design a GPT-based scoring method as a supplement to standard evaluation metrics. We also explore the effect of different data sources (e.g., text, maps, building heights, and multi-temporal satellite imagery) on this task. Results on three public cross-view datasets show that CrossViewDiff outperforms current state-of-the-art on both standard and GPT-based evaluation metrics, generating high-quality street-view panoramas with more realistic structures and textures across rural, suburban, and urban scenes. The code and models of this work will be released at https://opendatalab.github.io/CrossViewDiff/.
Cross-view image geo-localization with Panorama-BEV Co-Retrieval Network
Aug 10, 2024Cross-view geolocalization identifies the geographic location of street view images by matching them with a georeferenced satellite database. Significant challenges arise due to the drastic appearance and geometry differences between views. In this paper, we propose a new approach for cross-view image geo-localization, i.e., the Panorama-BEV Co-Retrieval Network. Specifically, by utilizing the ground plane assumption and geometric relations, we convert street view panorama images into the BEV view, reducing the gap between street panoramas and satellite imagery. In the existing retrieval of street view panorama images and satellite images, we introduce BEV and satellite image retrieval branches for collaborative retrieval. By retaining the original street view retrieval branch, we overcome the limited perception range issue of BEV representation. Our network enables comprehensive perception of both the global layout and local details around the street view capture locations. Additionally, we introduce CVGlobal, a global cross-view dataset that is closer to real-world scenarios. This dataset adopts a more realistic setup, with street view directions not aligned with satellite images. CVGlobal also includes cross-regional, cross-temporal, and street view to map retrieval tests, enabling a comprehensive evaluation of algorithm performance. Our method excels in multiple tests on common cross-view datasets such as CVUSA, CVACT, VIGOR, and our newly introduced CVGlobal, surpassing the current state-of-the-art approaches. The code and datasets can be found at \url{https://github.com/yejy53/EP-BEV}.
SG-BEV: Satellite-Guided BEV Fusion for Cross-View Semantic Segmentation
Apr 03, 2024



This paper aims at achieving fine-grained building attribute segmentation in a cross-view scenario, i.e., using satellite and street-view image pairs. The main challenge lies in overcoming the significant perspective differences between street views and satellite views. In this work, we introduce SG-BEV, a novel approach for satellite-guided BEV fusion for cross-view semantic segmentation. To overcome the limitations of existing cross-view projection methods in capturing the complete building facade features, we innovatively incorporate Bird's Eye View (BEV) method to establish a spatially explicit mapping of street-view features. Moreover, we fully leverage the advantages of multiple perspectives by introducing a novel satellite-guided reprojection module, optimizing the uneven feature distribution issues associated with traditional BEV methods. Our method demonstrates significant improvements on four cross-view datasets collected from multiple cities, including New York, San Francisco, and Boston. On average across these datasets, our method achieves an increase in mIOU by 10.13% and 5.21% compared with the state-of-the-art satellite-based and cross-view methods. The code and datasets of this work will be released at https://github.com/yejy53/SG-BEV.
VIGC: Visual Instruction Generation and Correction
Sep 11, 2023



The integration of visual encoders and large language models (LLMs) has driven recent progress in multimodal large language models (MLLMs). However, the scarcity of high-quality instruction-tuning data for vision-language tasks remains a challenge. The current leading paradigm, such as LLaVA, relies on language-only GPT-4 to generate data, which requires pre-annotated image captions and detection bounding boxes, suffering from understanding image details. A practical solution to this problem would be to utilize the available multimodal large language models (MLLMs) to generate instruction data for vision-language tasks. However, it's worth noting that the currently accessible MLLMs are not as powerful as their LLM counterparts, as they tend to produce inadequate responses and generate false information. As a solution for addressing the current issue, this paper proposes the Visual Instruction Generation and Correction (VIGC) framework that enables multimodal large language models to generate instruction-tuning data and progressively enhance its quality on-the-fly. Specifically, Visual Instruction Generation (VIG) guides the vision-language model to generate diverse instruction-tuning data. To ensure generation quality, Visual Instruction Correction (VIC) adopts an iterative update mechanism to correct any inaccuracies in data produced by VIG, effectively reducing the risk of hallucination. Leveraging the diverse, high-quality data generated by VIGC, we finetune mainstream models and validate data quality based on various evaluations. Experimental results demonstrate that VIGC not only compensates for the shortcomings of language-only data generation methods, but also effectively enhances the benchmark performance. The models, datasets, and code are available at https://opendatalab.github.io/VIGC.
SEPT: Towards Scalable and Efficient Visual Pre-Training
Dec 11, 2022



Recently, the self-supervised pre-training paradigm has shown great potential in leveraging large-scale unlabeled data to improve downstream task performance. However, increasing the scale of unlabeled pre-training data in real-world scenarios requires prohibitive computational costs and faces the challenge of uncurated samples. To address these issues, we build a task-specific self-supervised pre-training framework from a data selection perspective based on a simple hypothesis that pre-training on the unlabeled samples with similar distribution to the target task can bring substantial performance gains. Buttressed by the hypothesis, we propose the first yet novel framework for Scalable and Efficient visual Pre-Training (SEPT) by introducing a retrieval pipeline for data selection. SEPT first leverage a self-supervised pre-trained model to extract the features of the entire unlabeled dataset for retrieval pipeline initialization. Then, for a specific target task, SEPT retrievals the most similar samples from the unlabeled dataset based on feature similarity for each target instance for pre-training. Finally, SEPT pre-trains the target model with the selected unlabeled samples in a self-supervised manner for target data finetuning. By decoupling the scale of pre-training and available upstream data for a target task, SEPT achieves high scalability of the upstream dataset and high efficiency of pre-training, resulting in high model architecture flexibility. Results on various downstream tasks demonstrate that SEPT can achieve competitive or even better performance compared with ImageNet pre-training while reducing the size of training samples by one magnitude without resorting to any extra annotations.
Influence Selection for Active Learning
Aug 20, 2021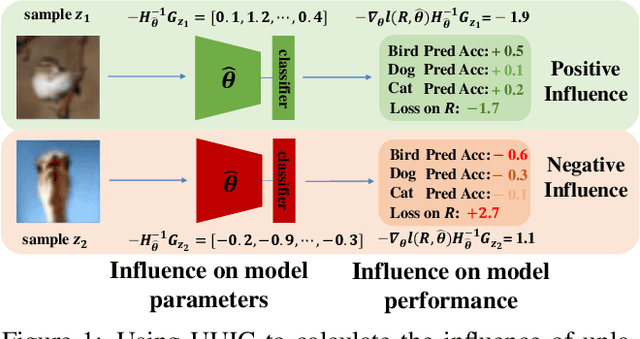
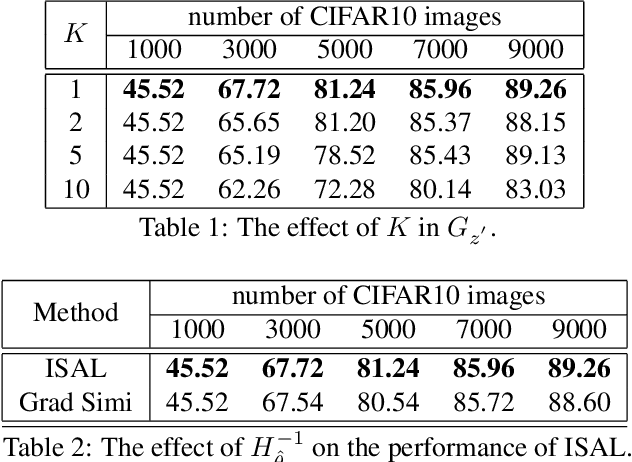
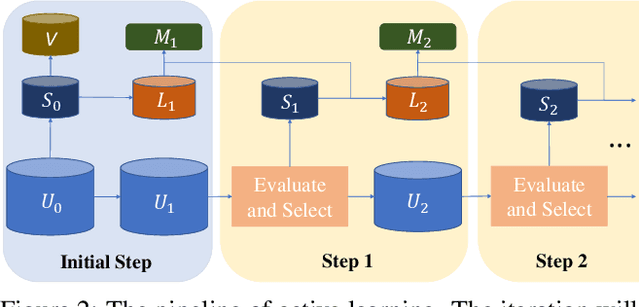
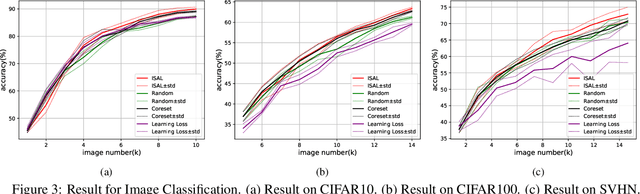
The existing active learning methods select the samples by evaluating the sample's uncertainty or its effect on the diversity of labeled datasets based on different task-specific or model-specific criteria. In this paper, we propose the Influence Selection for Active Learning(ISAL) which selects the unlabeled samples that can provide the most positive Influence on model performance. To obtain the Influence of the unlabeled sample in the active learning scenario, we design the Untrained Unlabeled sample Influence Calculation(UUIC) to estimate the unlabeled sample's expected gradient with which we calculate its Influence. To prove the effectiveness of UUIC, we provide both theoretical and experimental analyses. Since the UUIC just depends on the model gradients, which can be obtained easily from any neural network, our active learning algorithm is task-agnostic and model-agnostic. ISAL achieves state-of-the-art performance in different active learning settings for different tasks with different datasets. Compared with previous methods, our method decreases the annotation cost at least by 12%, 13% and 16% on CIFAR10, VOC2012 and COCO, respectively.