 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Item Representation Learning for Cold-start Content Recommendations
Apr 22, 2024



Cold-start item recommendation is a long-standing challenge in recommendation systems. A common remedy is to use a content-based approach, but rich information from raw contents in various forms has not been fully utilized. In this paper, we propose a domain/data-agnostic item representation learning framework for cold-start recommendations, naturally equipped with multimodal alignment among various features by adopting a Transformer-based architecture. Our proposed model is end-to-end trainable completely free from classification labels, not just costly to collect but suboptimal for recommendation-purpose representation learning. From extensive experiments on real-world movie and news recommendation benchmarks, we verify that our approach better preserves fine-grained user taste than state-of-the-art baselines, universally applicable to multiple domains at large scale.
Honeybee: Locality-enhanced Projector for Multimodal LLM
Dec 11, 2023In Multimodal Large Language Models (MLLMs), a visual projector plays a crucial role in bridging pre-trained vision encoders with LLMs, enabling profound visual understanding while harnessing the LLMs' robust capabilities. Despite the importance of the visual projector, it has been relatively less explored. In this study, we first identify two essential projector properties: (i) flexibility in managing the number of visual tokens, crucial for MLLMs' overall efficiency, and (ii) preservation of local context from visual features, vital for spatial understanding. Based on these findings, we propose a novel projector design that is both flexible and locality-enhanced, effectively satisfying the two desirable properties. Additionally, we present comprehensive strategies to effectively utilize multiple and multifaceted instruction datasets. Through extensive experiments, we examine the impact of individual design choices. Finally, our proposed MLLM, Honeybee, remarkably outperforms previous state-of-the-art methods across various benchmarks, including MME, MMBench, SEED-Bench, and LLaVA-Bench, achieving significantly higher efficiency. Code and models are available at https://github.com/kakaobrain/honeybee.
Learning Pseudo-Labeler beyond Noun Concepts for Open-Vocabulary Object Detection
Dec 04, 2023



Open-vocabulary object detection (OVOD) has recently gained significant attention as a crucial step toward achieving human-like visual intelligence. Existing OVOD methods extend target vocabulary from pre-defined categories to open-world by transferring knowledge of arbitrary concepts from vision-language pre-training models to the detectors. While previous methods have shown remarkable successes, they suffer from indirect supervision or limited transferable concepts. In this paper, we propose a simple yet effective method to directly learn region-text alignment for arbitrary concepts. Specifically, the proposed method aims to learn arbitrary image-to-text mapping for pseudo-labeling of arbitrary concepts, named Pseudo-Labeling for Arbitrary Concepts (PLAC). The proposed method shows competitive performance on the standard OVOD benchmark for noun concepts and a large improvement on referring expression comprehension benchmark for arbitrary concepts.
NICE: CVPR 2023 Challenge on Zero-shot Image Captioning
Sep 11, 2023



In this report, we introduce NICE (New frontiers for zero-shot Image Captioning Evaluation) project and share the results and outcomes of 2023 challenge. This project is designed to challenge the computer vision community to develop robust image captioning models that advance the state-of-the-art both in terms of accuracy and fairness. Through the challenge, the image captioning models were tested using a new evaluation dataset that includes a large variety of visual concepts from many domains. There was no specific training data provided for the challenge, and therefore the challenge entries were required to adapt to new types of image descriptions that had not been seen during training. This report includes information on the newly proposed NICE dataset, evaluation methods, challenge results, and technical details of top-ranking entries. We expect that the outcomes of the challenge will contribute to the improvement of AI models on various vision-language tasks.
Noise-aware Learning from Web-crawled Image-Text Data for Image Captioning
Dec 27, 2022



Image captioning is one of the straightforward tasks that can take advantage of large-scale web-crawled data which provides rich knowledge about the visual world for a captioning model. However, since web-crawled data contains image-text pairs that are aligned at different levels, the inherent noises (e.g., misaligned pairs) make it difficult to learn a precise captioning model. While the filtering strategy can effectively remove noisy data, however, it leads to a decrease in learnable knowledge and sometimes brings about a new problem of data deficiency. To take the best of both worlds, we propose a noise-aware learning framework, which learns rich knowledge from the whole web-crawled data while being less affected by the noises. This is achieved by the proposed quality controllable model, which is learned using alignment levels of the image-text pairs as an additional control signal during training. The alignment-conditioned training allows the model to generate high-quality captions of well-aligned by simply setting the control signal to desired alignment level at inference time. Through in-depth analysis, we show that our controllable captioning model is effective in handling noise. In addition, with two tasks of zero-shot captioning and text-to-image retrieval using generated captions (i.e., self-retrieval), we also demonstrate our model can produce high-quality captions in terms of descriptiveness and distinctiveness. Code is available at \url{https://github.com/kakaobrain/noc}.
Learning to Generate Text-grounded Mask for Open-world Semantic Segmentation from Only Image-Text Pairs
Dec 01, 2022We tackle open-world semantic segmentation, which aims at learning to segment arbitrary visual concepts in images, by using only image-text pairs without dense annotations. Existing open-world segmentation methods have shown impressive advances by employing contrastive learning (CL) to learn diverse visual concepts and adapting the learned image-level understanding to the segmentation task. However, these methods based on CL have a discrepancy since it only considers image-text level alignment in training time, while the segmentation task requires region-text level alignment at test time. In this paper, we propose a novel Text-grounded Contrastive Learning (TCL) framework to directly align a text and a region described by the text to address the train-test discrepancy. Our method generates a segmentation mask associated with a given text, extracts grounded image embedding from the masked region, and aligns it with text embedding via TCL. The framework addresses the discrepancy by letting the model learn region-text level alignment instead of image-text level alignment and encourages the model to directly improve the quality of generated segmentation masks. In addition, for a rigorous and fair comparison, we present a unified evaluation protocol with widely used 8 semantic segmentation datasets. TCL achieves state-of-the-art zero-shot segmentation performance with large margins in all datasets. Code is available at https://github.com/kakaobrain/tcl.
MSTR: Multi-Scale Transformer for End-to-End Human-Object Interaction Detection
Mar 28, 2022
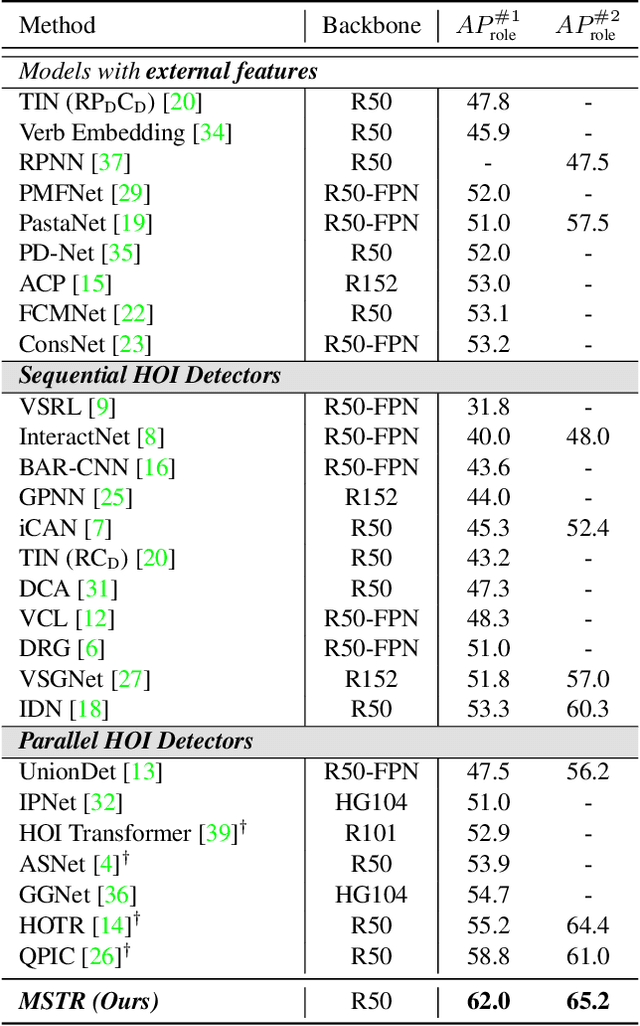
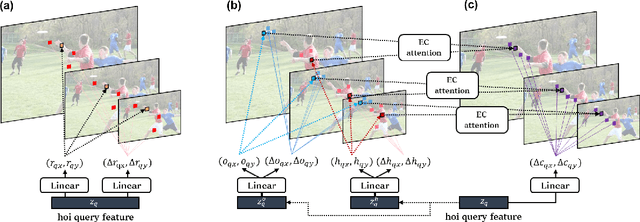
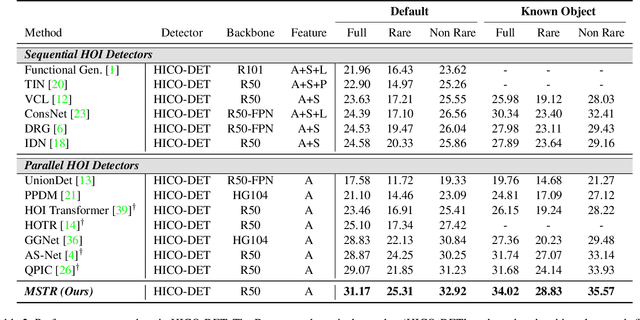
Human-Object Interaction (HOI) detection is the task of identifying a set of <human, object, interaction> triplets from an image. Recent work proposed transformer encoder-decoder architectures that successfully eliminated the need for many hand-designed components in HOI detection through end-to-end training. However, they are limited to single-scale feature resolution, providing suboptimal performance in scenes containing humans, objects and their interactions with vastly different scales and distances. To tackle this problem, we propose a Multi-Scale TRansformer (MSTR) for HOI detection powered by two novel HOI-aware deformable attention modules called Dual-Entity attention and Entity-conditioned Context attention. While existing deformable attention comes at a huge cost in HOI detection performance, our proposed attention modules of MSTR learn to effectively attend to sampling points that are essential to identify interactions. In experiments, we achieve the new state-of-the-art performance on two HOI detection benchmarks.
Boundary-aware Self-supervised Learning for Video Scene Segmentation
Jan 14, 2022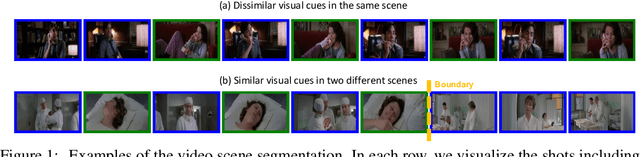
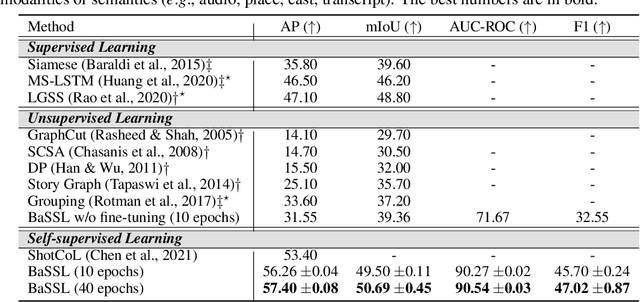
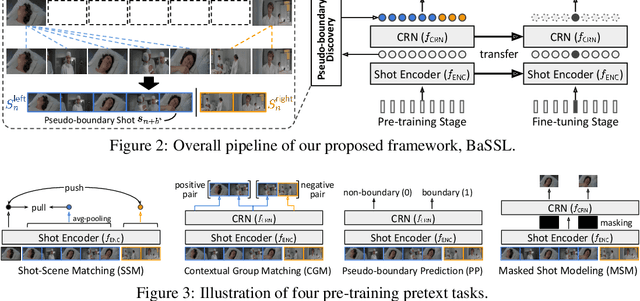
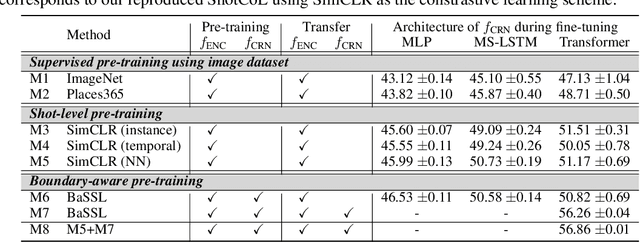
Self-supervised learning has drawn attention through its effectiveness in learning in-domain representations with no ground-truth annotations; in particular, it is shown that properly designed pretext tasks (e.g., contrastive prediction task) bring significant performance gains for downstream tasks (e.g., classification task). Inspired from this, we tackle video scene segmentation, which is a task of temporally localizing scene boundaries in a video, with a self-supervised learning framework where we mainly focus on designing effective pretext tasks. In our framework, we discover a pseudo-boundary from a sequence of shots by splitting it into two continuous, non-overlapping sub-sequences and leverage the pseudo-boundary to facilitate the pre-training. Based on this, we introduce three novel boundary-aware pretext tasks: 1) Shot-Scene Matching (SSM), 2) Contextual Group Matching (CGM) and 3) Pseudo-boundary Prediction (PP); SSM and CGM guide the model to maximize intra-scene similarity and inter-scene discrimination while PP encourages the model to identify transitional moments. Through comprehensive analysis, we empirically show that pre-training and transferring contextual representation are both critical to improving the video scene segmentation performance. Lastly, we achieve the new state-of-the-art on the MovieNet-SSeg benchmark. The code is available at https://github.com/kakaobrain/bassl.
Winning the ICCV'2021 VALUE Challenge: Task-aware Ensemble and Transfer Learning with Visual Concepts
Oct 13, 2021

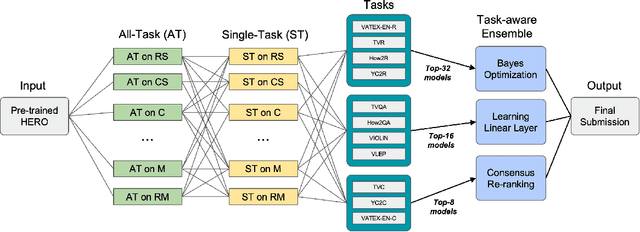
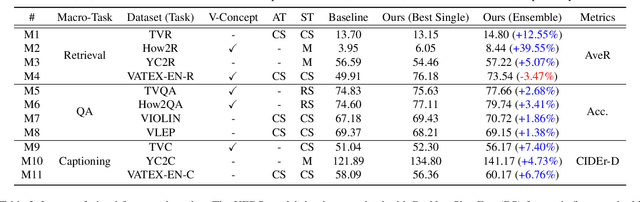
The VALUE (Video-And-Language Understanding Evaluation) benchmark is newly introduced to evaluate and analyze multi-modal representation learning algorithms on three video-and-language tasks: Retrieval, QA, and Captioning. The main objective of the VALUE challenge is to train a task-agnostic model that is simultaneously applicable for various tasks with different characteristics. This technical report describes our winning strategies for the VALUE challenge: 1) single model optimization, 2) transfer learning with visual concepts, and 3) task-aware ensemble. The first and third strategies are designed to address heterogeneous characteristics of each task, and the second one is to leverage rich and fine-grained visual information. We provide a detailed and comprehensive analysis with extensive experimental results. Based on our approach, we ranked first place on the VALUE and QA phases for the competition.
Local-Global Video-Text Interactions for Temporal Grounding
Apr 16, 2020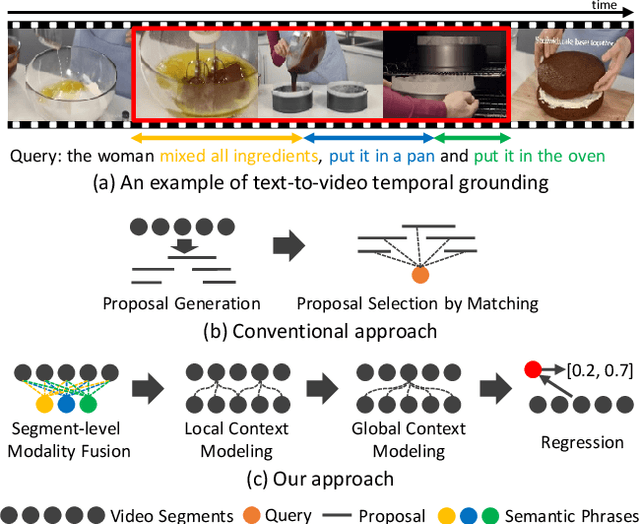
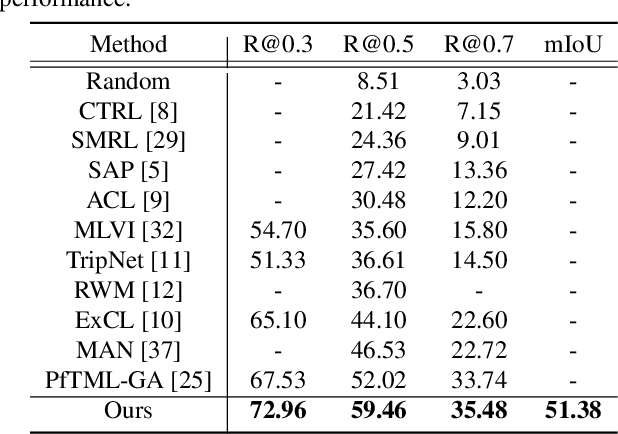
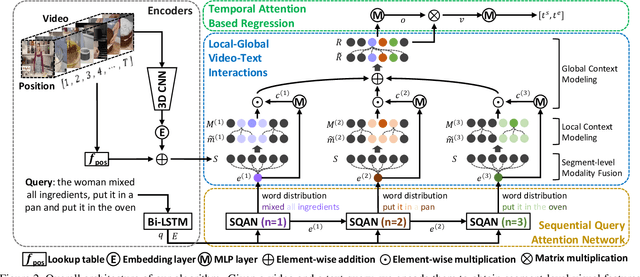
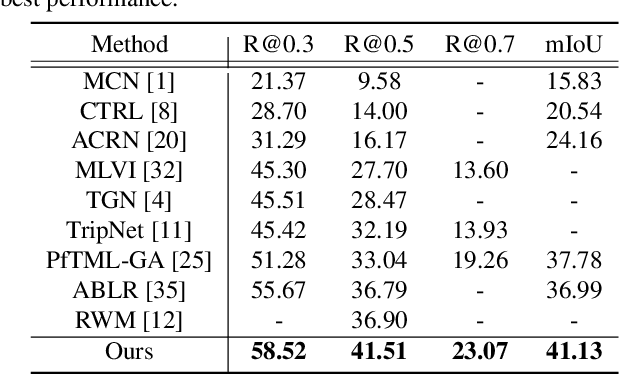
This paper addresses the problem of text-to-video temporal grounding, which aims to identify the time interval in a video semantically relevant to a text query. We tackle this problem using a novel regression-based model that learns to extract a collection of mid-level features for semantic phrases in a text query, which corresponds to important semantic entities described in the query (e.g., actors, objects, and actions), and reflect bi-modal interactions between the linguistic features of the query and the visual features of the video in multiple levels. The proposed method effectively predicts the target time interval by exploiting contextual information from local to global during bi-modal interactions. Through in-depth ablation studies, we find out that incorporating both local and global context in video and text interactions is crucial to the accurate grounding. Our experiment shows that the proposed method outperforms the state of the arts on Charades-STA and ActivityNet Captions datasets by large margins, 7.44\% and 4.61\% points at Recall@tIoU=0.5 metric, respectively. Code is available in https://github.com/JonghwanMun/LGI4temporalgrounding.