 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReading Recognition in the Wild
May 30, 2025To enable egocentric contextual AI in always-on smart glasses, it is crucial to be able to keep a record of the user's interactions with the world, including during reading. In this paper, we introduce a new task of reading recognition to determine when the user is reading. We first introduce the first-of-its-kind large-scale multimodal Reading in the Wild dataset, containing 100 hours of reading and non-reading videos in diverse and realistic scenarios. We then identify three modalities (egocentric RGB, eye gaze, head pose) that can be used to solve the task, and present a flexible transformer model that performs the task using these modalities, either individually or combined. We show that these modalities are relevant and complementary to the task, and investigate how to efficiently and effectively encode each modality. Additionally, we show the usefulness of this dataset towards classifying types of reading, extending current reading understanding studies conducted in constrained settings to larger scale, diversity and realism. Code, model, and data will be public.
Monocular Online Reconstruction with Enhanced Detail Preservation
May 14, 2025We propose an online 3D Gaussian-based dense mapping framework for photorealistic details reconstruction from a monocular image stream. Our approach addresses two key challenges in monocular online reconstruction: distributing Gaussians without relying on depth maps and ensuring both local and global consistency in the reconstructed maps. To achieve this, we introduce two key modules: the Hierarchical Gaussian Management Module for effective Gaussian distribution and the Global Consistency Optimization Module for maintaining alignment and coherence at all scales. In addition, we present the Multi-level Occupancy Hash Voxels (MOHV), a structure that regularizes Gaussians for capturing details across multiple levels of granularity. MOHV ensures accurate reconstruction of both fine and coarse geometries and textures, preserving intricate details while maintaining overall structural integrity. Compared to state-of-the-art RGB-only and even RGB-D methods, our framework achieves superior reconstruction quality with high computational efficiency. Moreover, it integrates seamlessly with various tracking systems, ensuring generality and scalability.
Aria Everyday Activities Dataset
Feb 22, 2024



We present Aria Everyday Activities (AEA) Dataset, an egocentric multimodal open dataset recorded using Project Aria glasses. AEA contains 143 daily activity sequences recorded by multiple wearers in five geographically diverse indoor locations. Each of the recording contains multimodal sensor data recorded through the Project Aria glasses. In addition, AEA provides machine perception data including high frequency globally aligned 3D trajectories, scene point cloud, per-frame 3D eye gaze vector and time aligned speech transcription. In this paper, we demonstrate a few exemplar research applications enabled by this dataset, including neural scene reconstruction and prompted segmentation. AEA is an open source dataset that can be downloaded from https://www.projectaria.com/datasets/aea/. We are also providing open-source implementations and examples of how to use the dataset in Project Aria Tools https://github.com/facebookresearch/projectaria_tools.
EgoBlur: Responsible Innovation in Aria
Sep 06, 2023



Project Aria pushes the frontiers of Egocentric AI with large-scale real-world data collection using purposely designed glasses with privacy first approach. To protect the privacy of bystanders being recorded by the glasses, our research protocols are designed to ensure recorded video is processed by an AI anonymization model that removes bystander faces and vehicle license plates. Detected face and license plate regions are processed with a Gaussian blur such that these personal identification information (PII) regions are obscured. This process helps to ensure that anonymized versions of the video is retained for research purposes. In Project Aria, we have developed a state-of-the-art anonymization system EgoBlur. In this paper, we present extensive analysis of EgoBlur on challenging datasets comparing its performance with other state-of-the-art systems from industry and academia including extensive Responsible AI analysis on recently released Casual Conversations V2 dataset.
Robust, High-Precision GNSS Carrier-Phase Positioning with Visual-Inertial Fusion
Mar 02, 2023



Robust, high-precision global localization is fundamental to a wide range of outdoor robotics applications. Conventional fusion methods use low-accuracy pseudorange based GNSS measurements ($>>5m$ errors) and can only yield a coarse registration to the global earth-centered-earth-fixed (ECEF) frame. In this paper, we leverage high-precision GNSS carrier-phase positioning and aid it with local visual-inertial odometry (VIO) tracking using an extended Kalman filter (EKF) framework that better resolves the integer ambiguity concerned with GNSS carrier-phase. %to achieve centimeter-level accuracy in the ECEF frame. We also propose an algorithm for accurate GNSS-antenna-to-IMU extrinsics calibration to accurately align VIO to the ECEF frame. Together, our system achieves robust global positioning demonstrated by real-world hardware experiments in severely occluded urban canyons, and outperforms the state-of-the-art RTKLIB by a significant margin in terms of integer ambiguity solution fix rate and positioning RMSE accuracy.
The Replica Dataset: A Digital Replica of Indoor Spaces
Jun 13, 2019


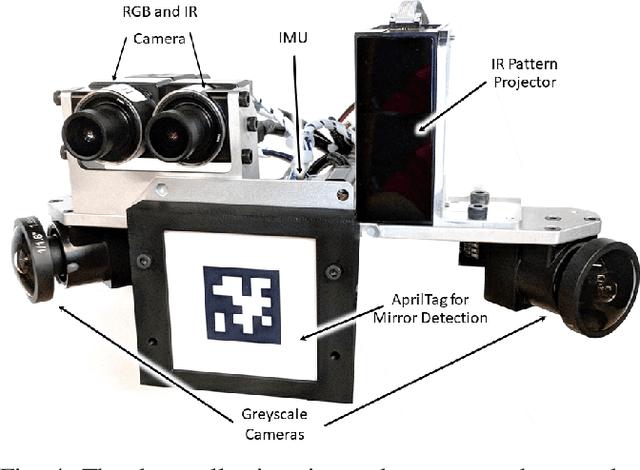
We introduce Replica, a dataset of 18 highly photo-realistic 3D indoor scene reconstructions at room and building scale. Each scene consists of a dense mesh, high-resolution high-dynamic-range (HDR) textures, per-primitive semantic class and instance information, and planar mirror and glass reflectors. The goal of Replica is to enable machine learning (ML) research that relies on visually, geometrically, and semantically realistic generative models of the world - for instance, egocentric computer vision, semantic segmentation in 2D and 3D, geometric inference, and the development of embodied agents (virtual robots) performing navigation, instruction following, and question answering. Due to the high level of realism of the renderings from Replica, there is hope that ML systems trained on Replica may transfer directly to real world image and video data. Together with the data, we are releasing a minimal C++ SDK as a starting point for working with the Replica dataset. In addition, Replica is `Habitat-compatible', i.e. can be natively used with AI Habitat for training and testing embodied agents.