 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpowering Feed-Forward Reconstruction Models with Metric Scale via Satellite Images
Jun 06, 2026Feed-forward 3D reconstruction models have recently shown strong generalization across diverse scenes, yet most of them recover geometry only up to an unknown global scale. This scale ambiguity limits their use in applications that require metric understanding of the environment. Existing metric reconstruction methods commonly rely on large-scale metric annotations or accurate camera calibration, both of which are costly or unreliable in many real-world settings. We propose a satellite-guided framework for resolving scale ambiguity in feed-forward 3D reconstruction. The key idea is to use readily available satellite imagery as a global metric reference. Given a coarse camera pose, our method retrieves a local satellite patch and integrates it with a feed-forward reconstruction backbone through bidirectional cross-view interaction. By enforcing consistency between the reconstructed scene and the satellite reference, the model infers absolute scale, refines scene geometry, and estimates camera pose in a metric coordinate frame. Experiments on KITTI, nuScenes, and Oxford RobotCar show consistent improvements in metric depth estimation, multi-view point-cloud reconstruction, and cross-view camera localization, while preserving strong generalization across datasets and geographic regions.
State-space models through the lens of ensemble control
Mar 13, 2026State-space models (SSMs) are effective architectures for sequential modeling, but a rigorous theoretical understanding of their training dynamics is still lacking. In this work, we formulate the training of SSMs as an ensemble optimal control problem, where a shared control law governs a population of input-dependent dynamical systems. We derive Pontryagin's maximum principle (PMP) for this ensemble control formulation, providing necessary conditions for optimality. Motivated by these conditions, we introduce an algorithm based on the method of successive approximations. We prove convergence of this iterative scheme along a subsequence and establish sufficient conditions for global optimality. The resulting framework provides a control-theoretic perspective on SSM training.
Multimodal Classification via Total Correlation Maximization
Feb 13, 2026Multimodal learning integrates data from diverse sensors to effectively harness information from different modalities. However, recent studies reveal that joint learning often overfits certain modalities while neglecting others, leading to performance inferior to that of unimodal learning. Although previous efforts have sought to balance modal contributions or combine joint and unimodal learning, thereby mitigating the degradation of weaker modalities with promising outcomes, few have examined the relationship between joint and unimodal learning from an information-theoretic perspective. In this paper, we theoretically analyze modality competition and propose a method for multimodal classification by maximizing the total correlation between multimodal features and labels. By maximizing this objective, our approach alleviates modality competition while capturing inter-modal interactions via feature alignment. Building on Mutual Information Neural Estimation (MINE), we introduce Total Correlation Neural Estimation (TCNE) to derive a lower bound for total correlation. Subsequently, we present TCMax, a hyperparameter-free loss function that maximizes total correlation through variational bound optimization. Extensive experiments demonstrate that TCMax outperforms state-of-the-art joint and unimodal learning approaches. Our code is available at https://github.com/hubaak/TCMax.
Adaptive Debiasing Tsallis Entropy for Test-Time Adaptation
Feb 12, 2026Mainstream Test-Time Adaptation (TTA) methods for adapting vision-language models, e.g., CLIP, typically rely on Shannon Entropy (SE) at test time to measure prediction uncertainty and inconsistency. However, since CLIP has a built-in bias from pretraining on highly imbalanced web-crawled data, SE inevitably results in producing biased estimates of uncertainty entropy. To address this issue, we notably find and demonstrate that Tsallis Entropy (TE), a generalized form of SE, is naturally suited for characterizing biased distributions by introducing a non-extensive parameter q, with the performance of SE serving as a lower bound for TE. Building upon this, we generalize TE into Adaptive Debiasing Tsallis Entropy (ADTE) for TTA, customizing a class-specific parameter q^l derived by normalizing the estimated label bias from continuously incoming test instances, for each category. This adaptive approach allows ADTE to accurately select high-confidence views and seamlessly integrate with a label adjustment strategy to enhance adaptation, without introducing distribution-specific hyperparameter tuning. Besides, our investigation reveals that both TE and ADTE can serve as direct, advanced alternatives to SE in TTA, without any other modifications. Experimental results show that ADTE outperforms state-of-the-art methods on ImageNet and its five variants, and achieves the highest average performance on 10 cross-domain benchmarks, regardless of the model architecture or text prompts used. Our code is available at https://github.com/Jinx630/ADTE.
Error Analysis of Generalized Langevin Equations with Approximated Memory Kernels
Dec 11, 2025


We analyze prediction error in stochastic dynamical systems with memory, focusing on generalized Langevin equations (GLEs) formulated as stochastic Volterra equations. We establish that, under a strongly convex potential, trajectory discrepancies decay at a rate determined by the decay of the memory kernel and are quantitatively bounded by the estimation error of the kernel in a weighted norm. Our analysis integrates synchronized noise coupling with a Volterra comparison theorem, encompassing both subexponential and exponential kernel classes. For first-order models, we derive moment and perturbation bounds using resolvent estimates in weighted spaces. For second-order models with confining potentials, we prove contraction and stability under kernel perturbations using a hypocoercive Lyapunov-type distance. This framework accommodates non-translation-invariant kernels and white-noise forcing, explicitly linking improved kernel estimation to enhanced trajectory prediction. Numerical examples validate these theoretical findings.
APD-Agents: A Large Language Model-Driven Multi-Agents Collaborative Framework for Automated Page Design
Nov 18, 2025



Layout design is a crucial step in developing mobile app pages. However, crafting satisfactory designs is time-intensive for designers: they need to consider which controls and content to present on the page, and then repeatedly adjust their size, position, and style for better aesthetics and structure. Although many design software can now help to perform these repetitive tasks, extensive training is needed to use them effectively. Moreover, collaborative design across app pages demands extra time to align standards and ensure consistent styling. In this work, we propose APD-agents, a large language model (LLM) driven multi-agent framework for automated page design in mobile applications. Our framework contains OrchestratorAgent, SemanticParserAgent, PrimaryLayoutAgent, TemplateRetrievalAgent, and RecursiveComponentAgent. Upon receiving the user's description of the page, the OrchestratorAgent can dynamically can direct other agents to accomplish users' design task. To be specific, the SemanticParserAgent is responsible for converting users' descriptions of page content into structured data. The PrimaryLayoutAgent can generate an initial coarse-grained layout of this page. The TemplateRetrievalAgent can fetch semantically relevant few-shot examples and enhance the quality of layout generation. Besides, a RecursiveComponentAgent can be used to decide how to recursively generate all the fine-grained sub-elements it contains for each element in the layout. Our work fully leverages the automatic collaboration capabilities of large-model-driven multi-agent systems. Experimental results on the RICO dataset show that our APD-agents achieve state-of-the-art performance.
FedCure: Mitigating Participation Bias in Semi-Asynchronous Federated Learning with Non-IID Data
Nov 13, 2025



While semi-asynchronous federated learning (SAFL) combines the efficiency of synchronous training with the flexibility of asynchronous updates, it inherently suffers from participation bias, which is further exacerbated by non-IID data distributions. More importantly, hierarchical architecture shifts participation from individual clients to client groups, thereby further intensifying this issue. Despite notable advancements in SAFL research, most existing works still focus on conventional cloud-end architectures while largely overlooking the critical impact of non-IID data on scheduling across the cloud-edge-client hierarchy. To tackle these challenges, we propose FedCure, an innovative semi-asynchronous Federated learning framework that leverages coalition construction and participation-aware scheduling to mitigate participation bias with non-IID data. Specifically, FedCure operates through three key rules: (1) a preference rule that optimizes coalition formation by maximizing collective benefits and establishing theoretically stable partitions to reduce non-IID-induced performance degradation; (2) a scheduling rule that integrates the virtual queue technique with Bayesian-estimated coalition dynamics, mitigating efficiency loss while ensuring mean rate stability; and (3) a resource allocation rule that enhances computational efficiency by optimizing client CPU frequencies based on estimated coalition dynamics while satisfying delay requirements. Comprehensive experiments on four real-world datasets demonstrate that FedCure improves accuracy by up to 5.1x compared with four state-of-the-art baselines, while significantly enhancing efficiency with the lowest coefficient of variation 0.0223 for per-round latency and maintaining long-term balance across diverse scenarios.
Text as Any-Modality for Zero-Shot Classification by Consistent Prompt Tuning
Aug 08, 2025The integration of prompt tuning with multimodal learning has shown significant generalization abilities for various downstream tasks. Despite advancements, existing methods heavily depend on massive modality-specific labeled data (e.g., video, audio, and image), or are customized for a single modality. In this study, we present Text as Any-Modality by Consistent Prompt Tuning (TaAM-CPT), a scalable approach for constructing a general representation model toward unlimited modalities using solely text data. TaAM-CPT comprises modality prompt pools, text construction, and modality-aligned text encoders from pre-trained models, which allows for extending new modalities by simply adding prompt pools and modality-aligned text encoders. To harmonize the learning across different modalities, TaAM-CPT designs intra- and inter-modal learning objectives, which can capture category details within modalities while maintaining semantic consistency across different modalities. Benefiting from its scalable architecture and pre-trained models, TaAM-CPT can be seamlessly extended to accommodate unlimited modalities. Remarkably, without any modality-specific labeled data, TaAM-CPT achieves leading results on diverse datasets spanning various modalities, including video classification, image classification, and audio classification. The code is available at https://github.com/Jinx630/TaAM-CPT.
DaringFed: A Dynamic Bayesian Persuasion Pricing for Online Federated Learning under Two-sided Incomplete Information
May 09, 2025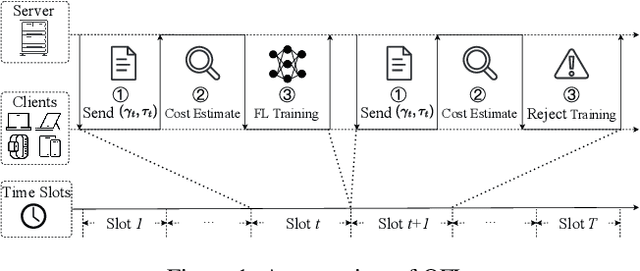


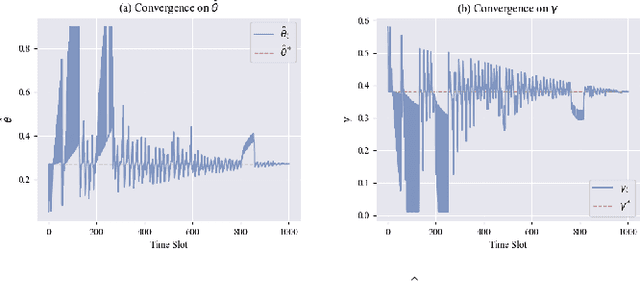
Online Federated Learning (OFL) is a real-time learning paradigm that sequentially executes parameter aggregation immediately for each random arriving client. To motivate clients to participate in OFL, it is crucial to offer appropriate incentives to offset the training resource consumption. However, the design of incentive mechanisms in OFL is constrained by the dynamic variability of Two-sided Incomplete Information (TII) concerning resources, where the server is unaware of the clients' dynamically changing computational resources, while clients lack knowledge of the real-time communication resources allocated by the server. To incentivize clients to participate in training by offering dynamic rewards to each arriving client, we design a novel Dynamic Bayesian persuasion pricing for online Federated learning (DaringFed) under TII. Specifically, we begin by formulating the interaction between the server and clients as a dynamic signaling and pricing allocation problem within a Bayesian persuasion game, and then demonstrate the existence of a unique Bayesian persuasion Nash equilibrium. By deriving the optimal design of DaringFed under one-sided incomplete information, we further analyze the approximate optimal design of DaringFed with a specific bound under TII. Finally, extensive evaluation conducted on real datasets demonstrate that DaringFed optimizes accuracy and converges speed by 16.99%, while experiments with synthetic datasets validate the convergence of estimate unknown values and the effectiveness of DaringFed in improving the server's utility by up to 12.6%.
Bi-Lipschitz Ansatz for Anti-Symmetric Functions
Mar 06, 2025Motivated by applications for simulating quantum many body functions, we propose a new universal ansatz for approximating anti-symmetric functions. The main advantage of this ansatz over previous alternatives is that it is bi-Lipschitz with respect to a naturally defined metric. As a result, we are able to obtain quantitative approximation results for approximation of Lipschitz continuous antisymmetric functions. Moreover, we provide preliminary experimental evidence to the improved performance of this ansatz for learning antisymmetric functions.