 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphs RAG at Scale: Beyond Retrieval-Augmented Generation With Labeled Property Graphs and Resource Description Framework for Complex and Unknown Search Spaces
Mar 21, 2026Recent advances in Retrieval-Augmented Generation (RAG) have revolutionized knowledge-intensive tasks, yet traditional RAG methods struggle when the search space is unknown or when documents are semi-structured or structured. We introduce a novel end-to-end Graph RAG framework that leverages both Labeled Property Graph (LPG) and Resource Description Framework (RDF) architectures to overcome these limitations. Our approach enables dynamic document retrieval without the need to pre-specify the number of documents and eliminates inefficient reranking. We propose an innovative method for converting documents into RDF triplets using JSON key-value pairs, facilitating seamless integration of semi-structured data. Additionally, we present a text to Cypher framework for LPG, achieving over 90% accuracy in real-time translation of text queries to Cypher, enabling fast and reliable query generation suitable for online applications. Our empirical evaluation demonstrates that Graph RAG significantly outperforms traditional embedding-based RAG in accuracy, response quality, and reasoning, especially for complex, semi-structured tasks. These findings establish Graph RAG as a transformative solution for next-generation retrieval-augmented systems.
Designing probabilistic AI monsoon forecasts to inform agricultural decision-making
Mar 10, 2026Hundreds of millions of farmers make high-stakes decisions under uncertainty about future weather. Forecasts can inform these decisions, but available choices and their risks and benefits vary between farmers. We introduce a decision-theory framework for designing useful forecasts in settings where the forecaster cannot prescribe optimal actions because farmers' circumstances are heterogeneous. We apply this framework to the case of seasonal onset of monsoon rains, a key date for planting decisions and agricultural investments in many tropical countries. We develop a system for tailoring forecasts to the requirements of this framework by blending systematically benchmarked artificial intelligence (AI) weather prediction models with a new "evolving farmer expectations" statistical model. This statistical model applies Bayesian inference to historical observations to predict time-varying probabilities of first-occurrence events throughout a season. The blended system yields more skillful Indian monsoon forecasts at longer lead times than its components or any multi-model average. In 2025, this system was deployed operationally in a government-led program that delivered subseasonal monsoon onset forecasts to 38 million Indian farmers, skillfully predicting that year's early-summer anomalous dry period. This decision-theory framework and blending system offer a pathway for developing climate adaptation tools for large vulnerable populations around the world.
Decision-oriented benchmarking to transform AI weather forecast access: Application to the Indian monsoon
Feb 03, 2026Artificial intelligence weather prediction (AIWP) models now often outperform traditional physics-based models on common metrics while requiring orders-of-magnitude less computing resources and time. Open-access AIWP models thus hold promise as transformational tools for helping low- and middle-income populations make decisions in the face of high-impact weather shocks. Yet, current approaches to evaluating AIWP models focus mainly on aggregated meteorological metrics without considering local stakeholders' needs in decision-oriented, operational frameworks. Here, we introduce such a framework that connects meteorology, AI, and social sciences. As an example, we apply it to the 150-year-old problem of Indian monsoon forecasting, focusing on benefits to rain-fed agriculture, which is highly susceptible to climate change. AIWP models skillfully predict an agriculturally relevant onset index at regional scales weeks in advance when evaluated out-of-sample using deterministic and probabilistic metrics. This framework informed a government-led effort in 2025 to send 38 million Indian farmers AI-based monsoon onset forecasts, which captured an unusual weeks-long pause in monsoon progression. This decision-oriented benchmarking framework provides a key component of a blueprint for harnessing the power of AIWP models to help large vulnerable populations adapt to weather shocks in the face of climate variability and change.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Gall Bladder Cancer Detection from US Images with Only Image Level Labels
Sep 11, 2023



Automated detection of Gallbladder Cancer (GBC) from Ultrasound (US) images is an important problem, which has drawn increased interest from researchers. However, most of these works use difficult-to-acquire information such as bounding box annotations or additional US videos. In this paper, we focus on GBC detection using only image-level labels. Such annotation is usually available based on the diagnostic report of a patient, and do not require additional annotation effort from the physicians. However, our analysis reveals that it is difficult to train a standard image classification model for GBC detection. This is due to the low inter-class variance (a malignant region usually occupies only a small portion of a US image), high intra-class variance (due to the US sensor capturing a 2D slice of a 3D object leading to large viewpoint variations), and low training data availability. We posit that even when we have only the image level label, still formulating the problem as object detection (with bounding box output) helps a deep neural network (DNN) model focus on the relevant region of interest. Since no bounding box annotations is available for training, we pose the problem as weakly supervised object detection (WSOD). Motivated by the recent success of transformer models in object detection, we train one such model, DETR, using multi-instance-learning (MIL) with self-supervised instance selection to suit the WSOD task. Our proposed method demonstrates an improvement of AP and detection sensitivity over the SOTA transformer-based and CNN-based WSOD methods. Project page is at https://gbc-iitd.github.io/wsod-gbc
RadFormer: Transformers with Global-Local Attention for Interpretable and Accurate Gallbladder Cancer Detection
Nov 09, 2022



We propose a novel deep neural network architecture to learn interpretable representation for medical image analysis. Our architecture generates a global attention for region of interest, and then learns bag of words style deep feature embeddings with local attention. The global, and local feature maps are combined using a contemporary transformer architecture for highly accurate Gallbladder Cancer (GBC) detection from Ultrasound (USG) images. Our experiments indicate that the detection accuracy of our model beats even human radiologists, and advocates its use as the second reader for GBC diagnosis. Bag of words embeddings allow our model to be probed for generating interpretable explanations for GBC detection consistent with the ones reported in medical literature. We show that the proposed model not only helps understand decisions of neural network models but also aids in discovery of new visual features relevant to the diagnosis of GBC. Source-code and model will be available at https://github.com/sbasu276/RadFormer
Unsupervised Contrastive Learning of Image Representations from Ultrasound Videos with Hard Negative Mining
Jul 26, 2022
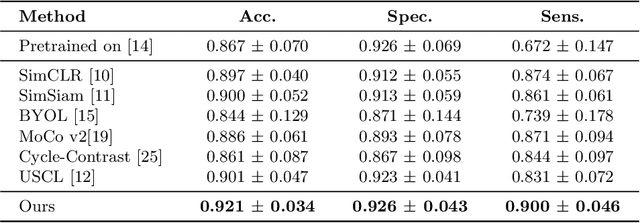
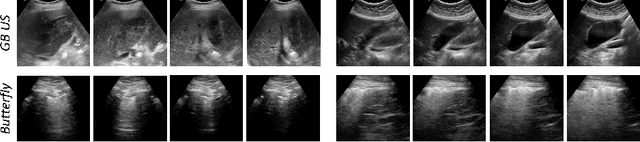
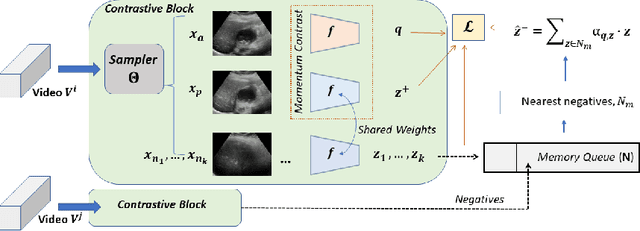
Rich temporal information and variations in viewpoints make video data an attractive choice for learning image representations using unsupervised contrastive learning (UCL) techniques. State-of-the-art (SOTA) contrastive learning techniques consider frames within a video as positives in the embedding space, whereas the frames from other videos are considered negatives. We observe that unlike multiple views of an object in natural scene videos, an Ultrasound (US) video captures different 2D slices of an organ. Hence, there is almost no similarity between the temporally distant frames of even the same US video. In this paper we propose to instead utilize such frames as hard negatives. We advocate mining both intra-video and cross-video negatives in a hardness-sensitive negative mining curriculum in a UCL framework to learn rich image representations. We deploy our framework to learn the representations of Gallbladder (GB) malignancy from US videos. We also construct the first large-scale US video dataset containing 64 videos and 15,800 frames for learning GB representations. We show that the standard ResNet50 backbone trained with our framework improves the accuracy of models pretrained with SOTA UCL techniques as well as supervised pretrained models on ImageNet for the GB malignancy detection task by 2-6%. We further validate the generalizability of our method on a publicly available lung US image dataset of COVID-19 pathologies and show an improvement of 1.5% compared to SOTA. Source code, dataset, and models are available at https://gbc-iitd.github.io/usucl.
Surpassing the Human Accuracy: Detecting Gallbladder Cancer from USG Images with Curriculum Learning
Apr 25, 2022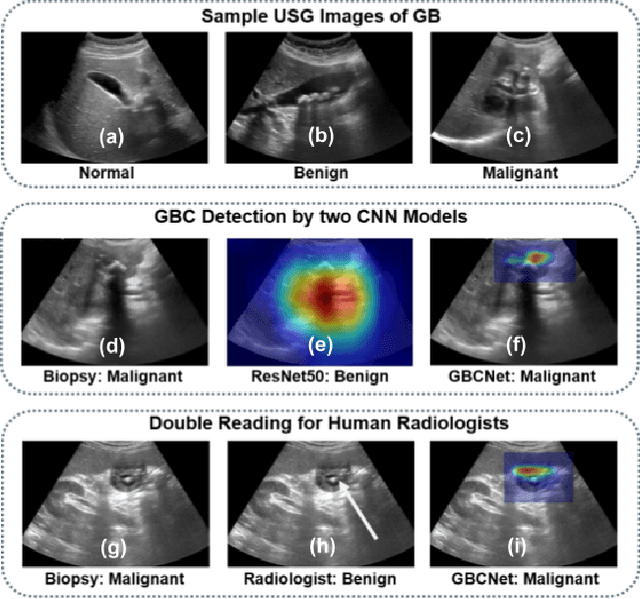
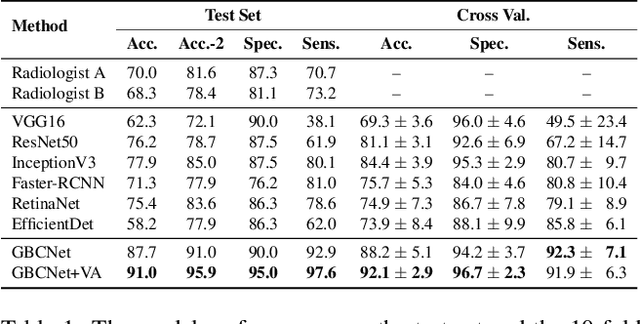
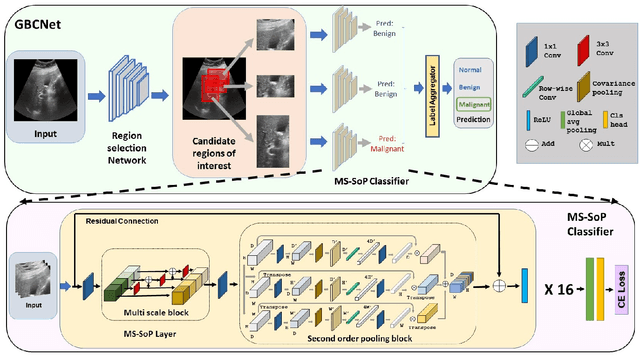
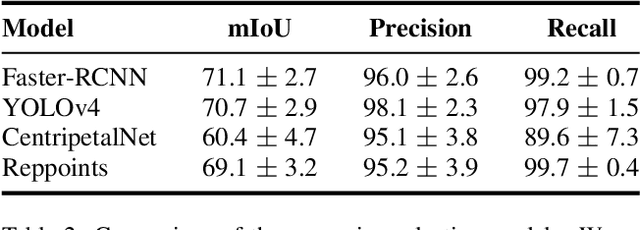
We explore the potential of CNN-based models for gallbladder cancer (GBC) detection from ultrasound (USG) images as no prior study is known. USG is the most common diagnostic modality for GB diseases due to its low cost and accessibility. However, USG images are challenging to analyze due to low image quality, noise, and varying viewpoints due to the handheld nature of the sensor. Our exhaustive study of state-of-the-art (SOTA) image classification techniques for the problem reveals that they often fail to learn the salient GB region due to the presence of shadows in the USG images. SOTA object detection techniques also achieve low accuracy because of spurious textures due to noise or adjacent organs. We propose GBCNet to tackle the challenges in our problem. GBCNet first extracts the regions of interest (ROIs) by detecting the GB (and not the cancer), and then uses a new multi-scale, second-order pooling architecture specializing in classifying GBC. To effectively handle spurious textures, we propose a curriculum inspired by human visual acuity, which reduces the texture biases in GBCNet. Experimental results demonstrate that GBCNet significantly outperforms SOTA CNN models, as well as the expert radiologists. Our technical innovations are generic to other USG image analysis tasks as well. Hence, as a validation, we also show the efficacy of GBCNet in detecting breast cancer from USG images. Project page with source code, trained models, and data is available at https://gbc-iitd.github.io/gbcnet
A Supervised Learning Approach for Robust Health Monitoring using Face Videos
Jan 30, 2021
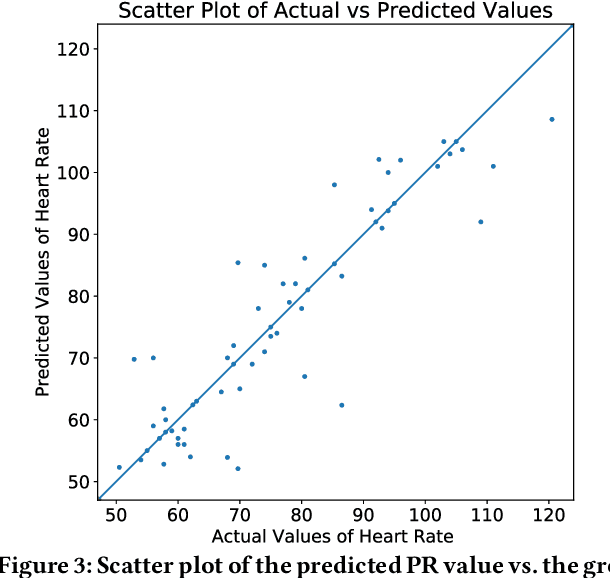
Monitoring of cardiovascular activity is highly desired and can enable novel applications in diagnosing potential cardiovascular diseases and maintaining an individual's well-being. Currently, such vital signs are measured using intrusive contact devices such as an electrocardiogram (ECG), chest straps, and pulse oximeters that require the patient or the health provider to manually implement. Non-contact, device-free human sensing methods can eliminate the need for specialized heart and blood pressure monitoring equipment. Non-contact methods can have additional advantages since they are scalable with any environment where video can be captured, can be used for continuous measurements, and can be used on patients with varying levels of dexterity and independence, from people with physical impairments to infants (e.g., baby camera). In this paper, we used a non-contact method that only requires face videos recorded using commercially-available webcams. These videos were exploited to predict the health attributes like pulse rate and variance in pulse rate. The proposed approach used facial recognition to detect the face in each frame of the video using facial landmarks, followed by supervised learning using deep neural networks to train the machine learning model. The videos captured subjects performing different physical activities that result in varying cardiovascular responses. The proposed method did not require training data from every individual and thus the prediction can be obtained for the new individuals for which there is no prior data; critical in approach generalization. The approach was also evaluated on a dataset of people with different ethnicity. The proposed approach had less than a 4.6\% error in predicting the pulse rate.
* The main part of the paper appeared in DFHS'20: Proceedings of the 2nd ACM Workshop on Device-Free Human Sensing; while the Supplementary did not appear in the proceedings