 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Activate and Reject: Towards Safe Domain Generalization under Category Shift
Oct 07, 2023
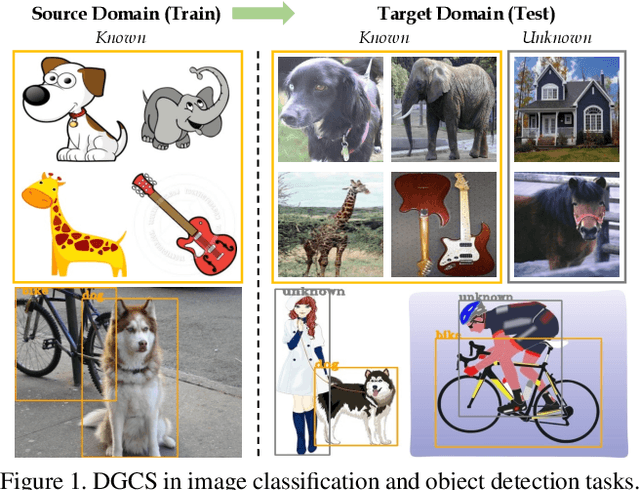

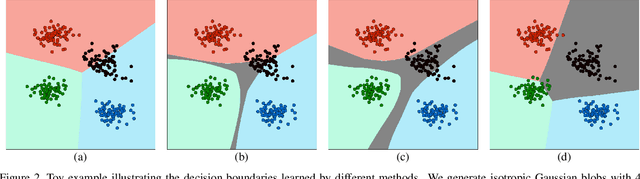
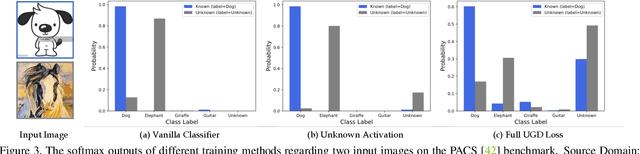
Albeit the notable performance on in-domain test points, it is non-trivial for deep neural networks to attain satisfactory accuracy when deploying in the open world, where novel domains and object classes often occur. In this paper, we study a practical problem of Domain Generalization under Category Shift (DGCS), which aims to simultaneously detect unknown-class samples and classify known-class samples in the target domains. Compared to prior DG works, we face two new challenges: 1) how to learn the concept of ``unknown'' during training with only source known-class samples, and 2) how to adapt the source-trained model to unseen environments for safe model deployment. To this end, we propose a novel Activate and Reject (ART) framework to reshape the model's decision boundary to accommodate unknown classes and conduct post hoc modification to further discriminate known and unknown classes using unlabeled test data. Specifically, during training, we promote the response to the unknown by optimizing the unknown probability and then smoothing the overall output to mitigate the overconfidence issue. At test time, we introduce a step-wise online adaptation method that predicts the label by virtue of the cross-domain nearest neighbor and class prototype information without updating the network's parameters or using threshold-based mechanisms. Experiments reveal that ART consistently improves the generalization capability of deep networks on different vision tasks. For image classification, ART improves the H-score by 6.1% on average compared to the previous best method. For object detection and semantic segmentation, we establish new benchmarks and achieve competitive performance.
A Content-Driven Micro-Video Recommendation Dataset at Scale
Sep 27, 2023



Micro-videos have recently gained immense popularity, sparking critical research in micro-video recommendation with significant implications for the entertainment, advertising, and e-commerce industries. However, the lack of large-scale public micro-video datasets poses a major challenge for developing effective recommender systems. To address this challenge, we introduce a very large micro-video recommendation dataset, named "MicroLens", consisting of one billion user-item interaction behaviors, 34 million users, and one million micro-videos. This dataset also contains various raw modality information about videos, including titles, cover images, audio, and full-length videos. MicroLens serves as a benchmark for content-driven micro-video recommendation, enabling researchers to utilize various modalities of video information for recommendation, rather than relying solely on item IDs or off-the-shelf video features extracted from a pre-trained network. Our benchmarking of multiple recommender models and video encoders on MicroLens has yielded valuable insights into the performance of micro-video recommendation. We believe that this dataset will not only benefit the recommender system community but also promote the development of the video understanding field. Our datasets and code are available at https://github.com/westlake-repl/MicroLens.
In-Hand Re-grasp Manipulation with Passive Dynamic Actions via Imitation Learning
Sep 27, 2023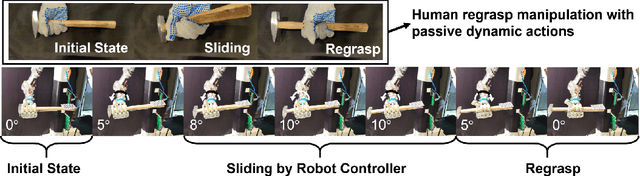
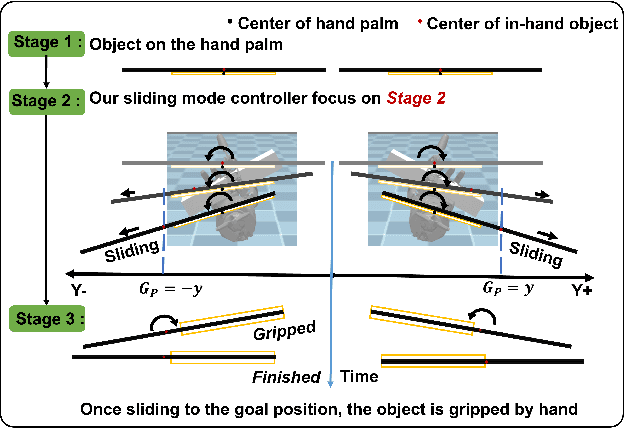
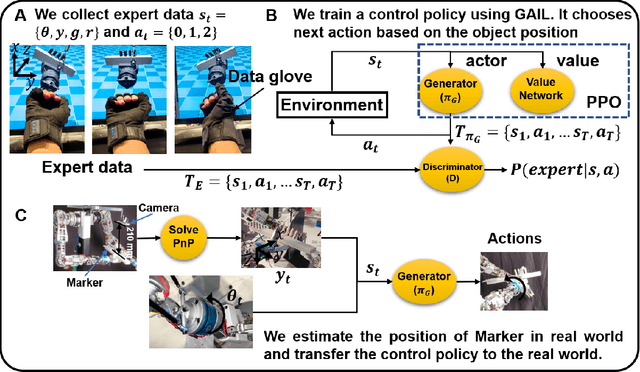
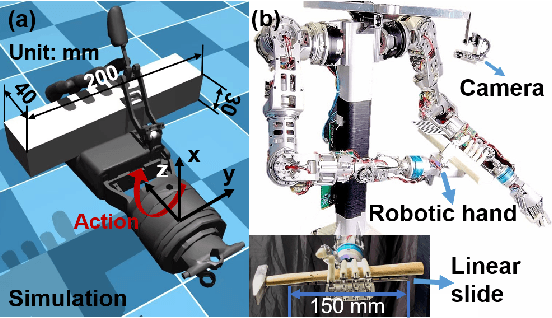
Re-grasp manipulation leverages on ergonomic tools to assist humans in accomplishing diverse tasks. In certain scenarios, humans often employ external forces to effortlessly and precisely re-grasp tools like a hammer. Previous development on controllers for in-grasp sliding motion using passive dynamic actions (e.g.,gravity) relies on apprehension of finger-object contact information, and requires customized design for individual objects with varied geometry and weight distribution. It limits their adaptability to diverse objects. In this paper, we propose an end-to-end sliding motion controller based on imitation learning (IL) that necessitates minimal prior knowledge of object mechanics, relying solely on object position information. To expedite training convergence, we utilize a data glove to collect expert data trajectories and train the policy through Generative Adversarial Imitation Learning (GAIL). Simulation results demonstrate the controller's versatility in performing in-hand sliding tasks with objects of varying friction coefficients, geometric shapes, and masses. By migrating to a physical system using visual position estimation, the controller demonstrated an average success rate of 86%, surpassing the baseline algorithm's success rate of 35% of Behavior Cloning(BC) and 20% of Proximal Policy Optimization (PPO).
Audio-visual child-adult speaker classification in dyadic interactions
Oct 03, 2023Interactions involving children span a wide range of important domains from learning to clinical diagnostic and therapeutic contexts. Automated analyses of such interactions are motivated by the need to seek accurate insights and offer scale and robustness across diverse and wide-ranging conditions. Identifying the speech segments belonging to the child is a critical step in such modeling. Conventional child-adult speaker classification typically relies on audio modeling approaches, overlooking visual signals that convey speech articulation information, such as lip motion. Building on the foundation of an audio-only child-adult speaker classification pipeline, we propose incorporating visual cues through active speaker detection and visual processing models. Our framework involves video pre-processing, utterance-level child-adult speaker detection, and late fusion of modality-specific predictions. We demonstrate from extensive experiments that a visually aided classification pipeline enhances the accuracy and robustness of the classification. We show relative improvements of 2.38% and 3.97% in F1 macro score when one face and two faces are visible, respectively
Large Language Models Can Be Good Privacy Protection Learners
Oct 03, 2023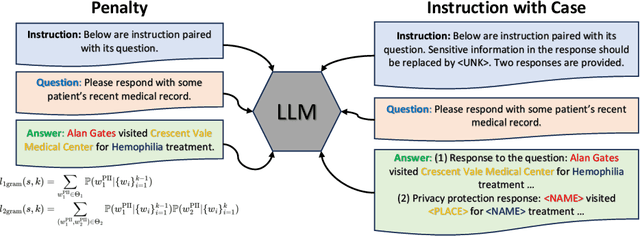
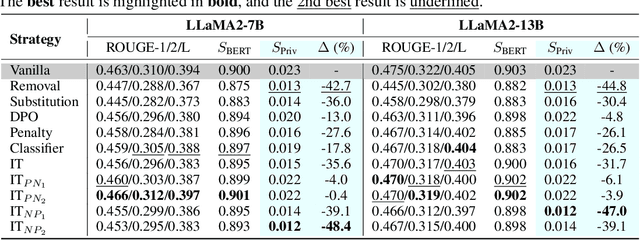
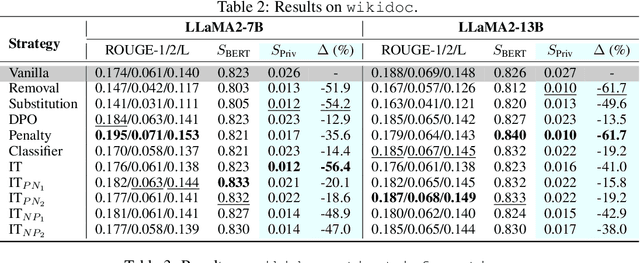
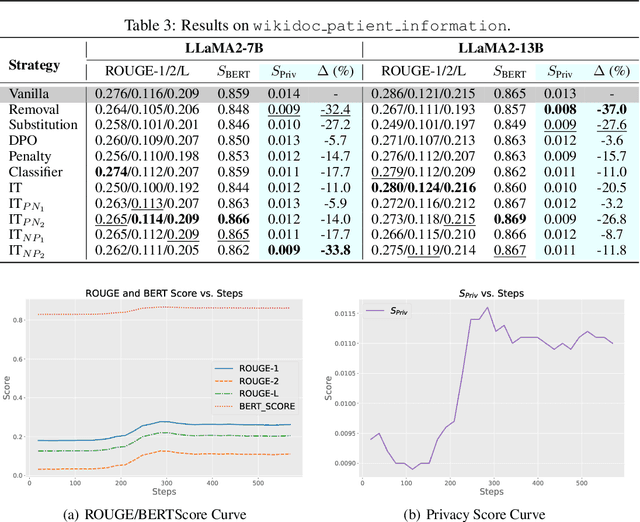
The proliferation of Large Language Models (LLMs) has driven considerable interest in fine-tuning them with domain-specific data to create specialized language models. Nevertheless, such domain-specific fine-tuning data often contains sensitive personally identifiable information (PII). Direct fine-tuning LLMs on this data without privacy protection poses a risk of leakage. To address this challenge, we introduce Privacy Protection Language Models (PPLM), a novel paradigm for fine-tuning LLMs that effectively injects domain-specific knowledge while safeguarding data privacy. Our work offers a theoretical analysis for model design and delves into various techniques such as corpus curation, penalty-based unlikelihood in training loss, and instruction-based tuning, etc. Extensive experiments across diverse datasets and scenarios demonstrate the effectiveness of our approaches. In particular, instruction tuning with both positive and negative examples, stands out as a promising method, effectively protecting private data while enhancing the model's knowledge. Our work underscores the potential for Large Language Models as robust privacy protection learners.
ALT-Pilot: Autonomous navigation with Language augmented Topometric maps
Oct 03, 2023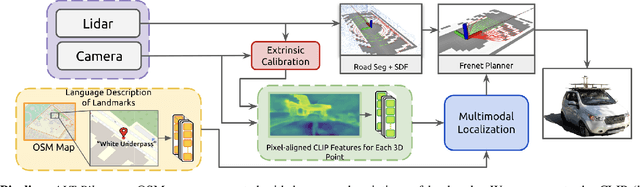
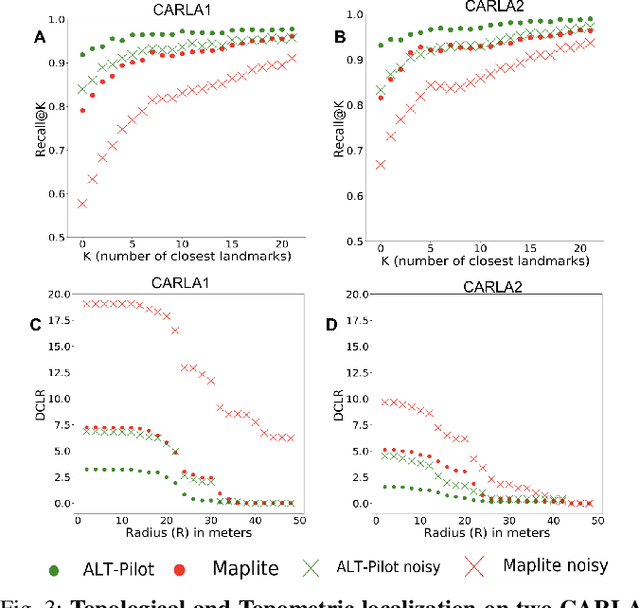
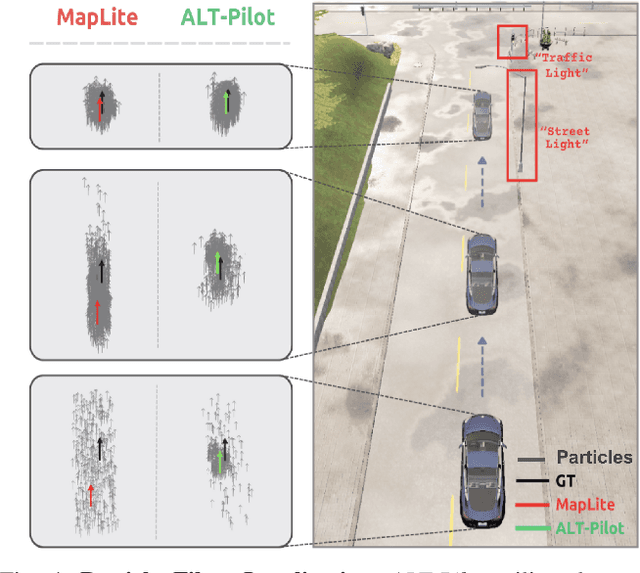
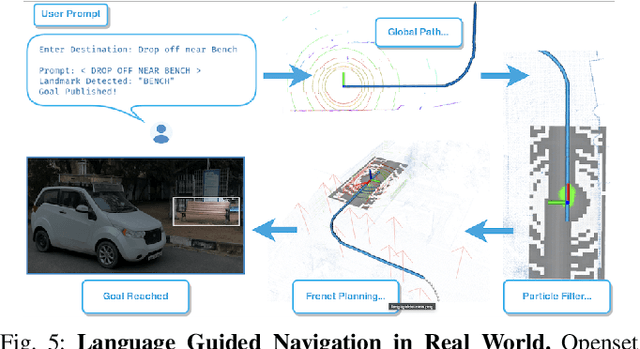
We present an autonomous navigation system that operates without assuming HD LiDAR maps of the environment. Our system, ALT-Pilot, relies only on publicly available road network information and a sparse (and noisy) set of crowdsourced language landmarks. With the help of onboard sensors and a language-augmented topometric map, ALT-Pilot autonomously pilots the vehicle to any destination on the road network. We achieve this by leveraging vision-language models pre-trained on web-scale data to identify potential landmarks in a scene, incorporating vision-language features into the recursive Bayesian state estimation stack to generate global (route) plans, and a reactive trajectory planner and controller operating in the vehicle frame. We implement and evaluate ALT-Pilot in simulation and on a real, full-scale autonomous vehicle and report improvements over state-of-the-art topometric navigation systems by a factor of 3x on localization accuracy and 5x on goal reachability
HoloNets: Spectral Convolutions do extend to Directed Graphs
Oct 03, 2023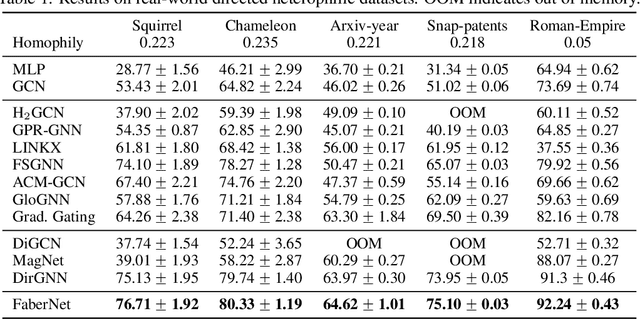


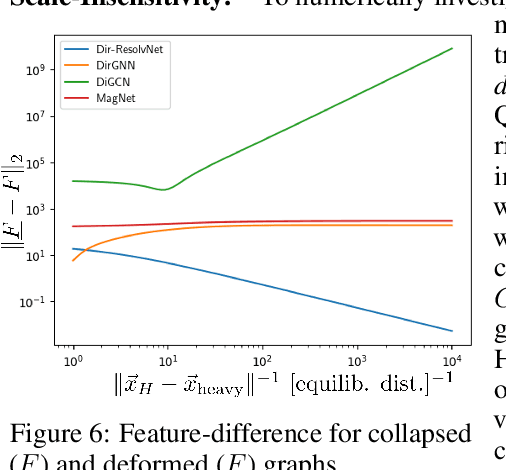
Within the graph learning community, conventional wisdom dictates that spectral convolutional networks may only be deployed on undirected graphs: Only there could the existence of a well-defined graph Fourier transform be guaranteed, so that information may be translated between spatial- and spectral domains. Here we show this traditional reliance on the graph Fourier transform to be superfluous and -- making use of certain advanced tools from complex analysis and spectral theory -- extend spectral convolutions to directed graphs. We provide a frequency-response interpretation of newly developed filters, investigate the influence of the basis used to express filters and discuss the interplay with characteristic operators on which networks are based. In order to thoroughly test the developed theory, we conduct experiments in real world settings, showcasing that directed spectral convolutional networks provide new state of the art results for heterophilic node classification on many datasets and -- as opposed to baselines -- may be rendered stable to resolution-scale varying topological perturbations.
Graph Isomorphic Networks for Assessing Reliability of the Medium-Voltage Grid
Oct 03, 2023Ensuring electricity grid reliability becomes increasingly challenging with the shift towards renewable energy and declining conventional capacities. Distribution System Operators (DSOs) aim to achieve grid reliability by verifying the n-1 principle, ensuring continuous operation in case of component failure. Electricity networks' complex graph-based data holds crucial information for n-1 assessment: graph structure and data about stations/cables. Unlike traditional machine learning methods, Graph Neural Networks (GNNs) directly handle graph-structured data. This paper proposes using Graph Isomorphic Networks (GINs) for n-1 assessments in medium voltage grids. The GIN framework is designed to generalise to unseen grids and utilise graph structure and data about stations/cables. The proposed GIN approach demonstrates faster and more reliable grid assessments than a traditional mathematical optimisation approach, reducing prediction times by approximately a factor of 1000. The findings offer a promising approach to address computational challenges and enhance the reliability and efficiency of energy grid assessments.
An Evaluation of ChatGPT-4's Qualitative Spatial Reasoning Capabilities in RCC-8
Sep 27, 2023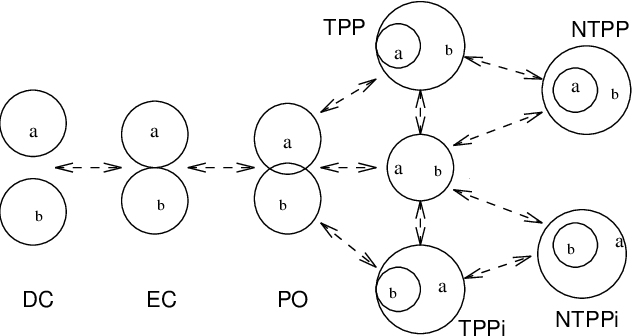
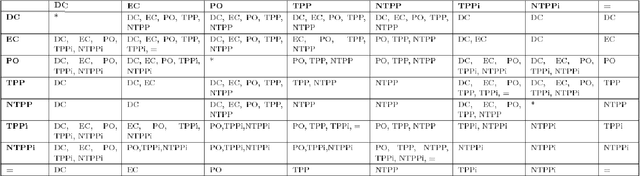
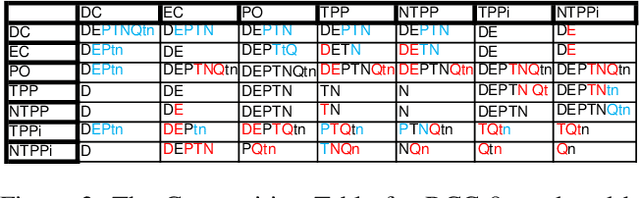
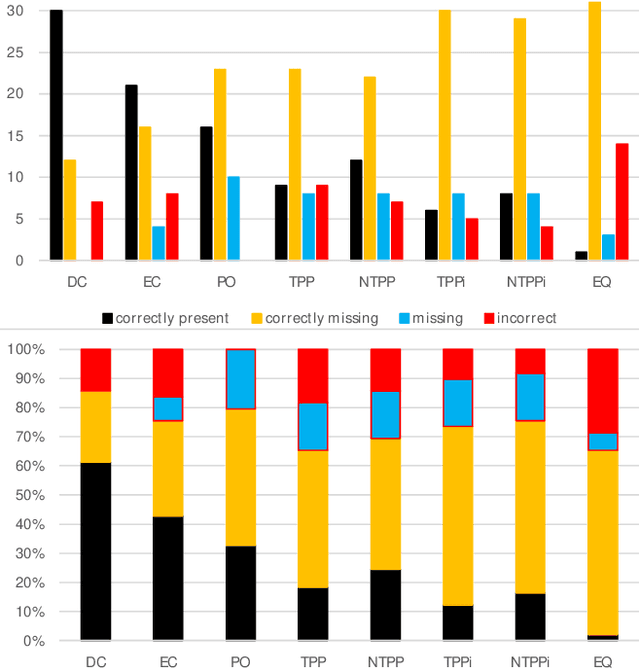
Qualitative Spatial Reasoning (QSR) is well explored area of Commonsense Reasoning and has multiple applications ranging from Geographical Information Systems to Robotics and Computer Vision. Recently many claims have been made for the capabilities of Large Language Models (LLMs). In this paper we investigate the extent to which one particular LLM can perform classical qualitative spatial reasoning tasks on the mereotopological calculus, RCC-8.
Multi-level feature fusion network combining attention mechanisms for polyp segmentation
Sep 24, 2023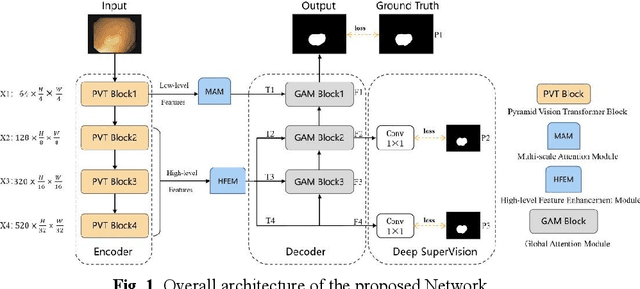
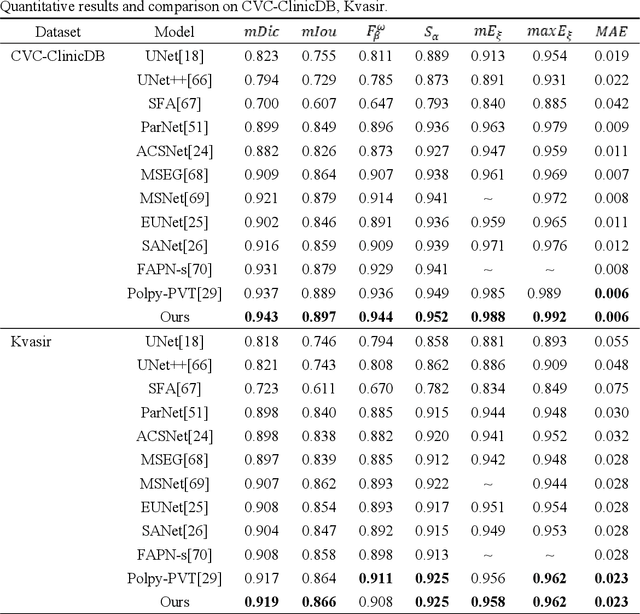
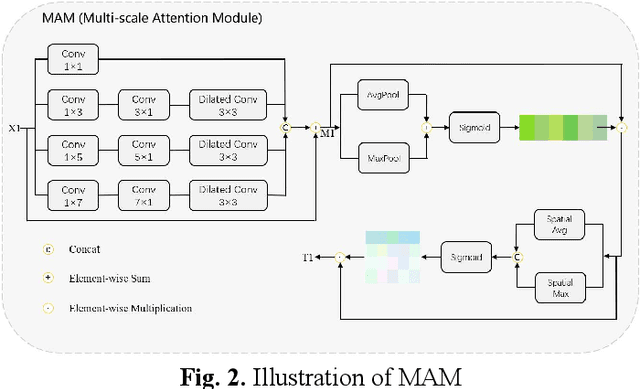
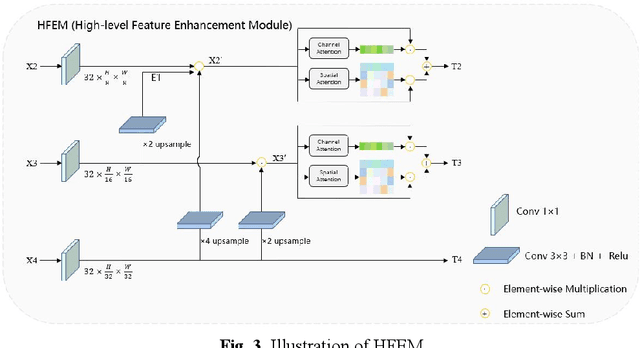
Clinically, automated polyp segmentation techniques have the potential to significantly improve the efficiency and accuracy of medical diagnosis, thereby reducing the risk of colorectal cancer in patients. Unfortunately, existing methods suffer from two significant weaknesses that can impact the accuracy of segmentation. Firstly, features extracted by encoders are not adequately filtered and utilized. Secondly, semantic conflicts and information redundancy caused by feature fusion are not attended to. To overcome these limitations, we propose a novel approach for polyp segmentation, named MLFF-Net, which leverages multi-level feature fusion and attention mechanisms. Specifically, MLFF-Net comprises three modules: Multi-scale Attention Module (MAM), High-level Feature Enhancement Module (HFEM), and Global Attention Module (GAM). Among these, MAM is used to extract multi-scale information and polyp details from the shallow output of the encoder. In HFEM, the deep features of the encoders complement each other by aggregation. Meanwhile, the attention mechanism redistributes the weight of the aggregated features, weakening the conflicting redundant parts and highlighting the information useful to the task. GAM combines features from the encoder and decoder features, as well as computes global dependencies to prevent receptive field locality. Experimental results on five public datasets show that the proposed method not only can segment multiple types of polyps but also has advantages over current state-of-the-art methods in both accuracy and generalization ability.