 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashSign: Pose-Free Guidance for Efficient Sign Language Video Generation
Mar 30, 2026Sign language plays a crucial role in bridging communication gaps between the deaf and hard-of-hearing communities. However, existing sign language video generation models often rely on complex intermediate representations, which limits their flexibility and efficiency. In this work, we propose a novel pose-free framework for real-time sign language video generation. Our method eliminates the need for intermediate pose representations by directly mapping natural language text to sign language videos using a diffusion-based approach. We introduce two key innovations: (1) a pose-free generative model based on the a state-of-the-art diffusion backbone, which learns implicit text-to-gesture alignments without pose estimation, and (2) a Trainable Sliding Tile Attention (T-STA) mechanism that accelerates inference by exploiting spatio-temporal locality patterns. Unlike previous training-free sparsity approaches, T-STA integrates trainable sparsity into both training and inference, ensuring consistency and eliminating the train-test gap. This approach significantly reduces computational overhead while maintaining high generation quality, making real-time deployment feasible. Our method increases video generation speed by 3.07x without compromising video quality. Our contributions open new avenues for real-time, high-quality, pose-free sign language synthesis, with potential applications in inclusive communication tools for diverse communities. Code: https://github.com/AIGeeksGroup/FlashSign.
Generalized Category Discovery in Event-Centric Contexts: Latent Pattern Mining with LLMs
May 29, 2025Generalized Category Discovery (GCD) aims to classify both known and novel categories using partially labeled data that contains only known classes. Despite achieving strong performance on existing benchmarks, current textual GCD methods lack sufficient validation in realistic settings. We introduce Event-Centric GCD (EC-GCD), characterized by long, complex narratives and highly imbalanced class distributions, posing two main challenges: (1) divergent clustering versus classification groupings caused by subjective criteria, and (2) Unfair alignment for minority classes. To tackle these, we propose PaMA, a framework leveraging LLMs to extract and refine event patterns for improved cluster-class alignment. Additionally, a ranking-filtering-mining pipeline ensures balanced representation of prototypes across imbalanced categories. Evaluations on two EC-GCD benchmarks, including a newly constructed Scam Report dataset, demonstrate that PaMA outperforms prior methods with up to 12.58% H-score gains, while maintaining strong generalization on base GCD datasets.
Generalized Category Discovery via Token Manifold Capacity Learning
May 20, 2025Generalized category discovery (GCD) is essential for improving deep learning models' robustness in open-world scenarios by clustering unlabeled data containing both known and novel categories. Traditional GCD methods focus on minimizing intra-cluster variations, often sacrificing manifold capacity, which limits the richness of intra-class representations. In this paper, we propose a novel approach, Maximum Token Manifold Capacity (MTMC), that prioritizes maximizing the manifold capacity of class tokens to preserve the diversity and complexity of data. MTMC leverages the nuclear norm of singular values as a measure of manifold capacity, ensuring that the representation of samples remains informative and well-structured. This method enhances the discriminability of clusters, allowing the model to capture detailed semantic features and avoid the loss of critical information during clustering. Through theoretical analysis and extensive experiments on coarse- and fine-grained datasets, we demonstrate that MTMC outperforms existing GCD methods, improving both clustering accuracy and the estimation of category numbers. The integration of MTMC leads to more complete representations, better inter-class separability, and a reduction in dimensional collapse, establishing MTMC as a vital component for robust open-world learning. Code is in github.com/lytang63/MTMC.
OCRT: Boosting Foundation Models in the Open World with Object-Concept-Relation Triad
Mar 24, 2025Although foundation models (FMs) claim to be powerful, their generalization ability significantly decreases when faced with distribution shifts, weak supervision, or malicious attacks in the open world. On the other hand, most domain generalization or adversarial fine-tuning methods are task-related or model-specific, ignoring the universality in practical applications and the transferability between FMs. This paper delves into the problem of generalizing FMs to the out-of-domain data. We propose a novel framework, the Object-Concept-Relation Triad (OCRT), that enables FMs to extract sparse, high-level concepts and intricate relational structures from raw visual inputs. The key idea is to bind objects in visual scenes and a set of object-centric representations through unsupervised decoupling and iterative refinement. To be specific, we project the object-centric representations onto a semantic concept space that the model can readily interpret and estimate their importance to filter out irrelevant elements. Then, a concept-based graph, which has a flexible degree, is constructed to incorporate the set of concepts and their corresponding importance, enabling the extraction of high-order factors from informative concepts and facilitating relational reasoning among these concepts. Extensive experiments demonstrate that OCRT can substantially boost the generalizability and robustness of SAM and CLIP across multiple downstream tasks.
Bootstrap Segmentation Foundation Model under Distribution Shift via Object-Centric Learning
Aug 29, 2024



Foundation models have made incredible strides in achieving zero-shot or few-shot generalization, leveraging prompt engineering to mimic the problem-solving approach of human intelligence. However, when it comes to some foundation models like Segment Anything, there is still a challenge in performing well on out-of-distribution data, including camouflaged and medical images. Inconsistent prompting strategies during fine-tuning and testing further compound the issue, leading to decreased performance. Drawing inspiration from how human cognition processes new environments, we introduce SlotSAM, a method that reconstructs features from the encoder in a self-supervised manner to create object-centric representations. These representations are then integrated into the foundation model, bolstering its object-level perceptual capabilities while reducing the impact of distribution-related variables. The beauty of SlotSAM lies in its simplicity and adaptability to various tasks, making it a versatile solution that significantly enhances the generalization abilities of foundation models. Through limited parameter fine-tuning in a bootstrap manner, our approach paves the way for improved generalization in novel environments. The code is available at github.com/lytang63/SlotSAM.
Mixstyle-Entropy: Domain Generalization with Causal Intervention and Perturbation
Aug 22, 2024



Despite the considerable advancements achieved by deep neural networks, their performance tends to degenerate when the test environment diverges from the training ones. Domain generalization (DG) solves this issue by learning representations independent of domain-related information, thus facilitating extrapolation to unseen environments. Existing approaches typically focus on formulating tailored training objectives to extract shared features from the source data. However, the disjointed training and testing procedures may compromise robustness, particularly in the face of unforeseen variations during deployment. In this paper, we propose a novel and holistic framework based on causality, named InPer, designed to enhance model generalization by incorporating causal intervention during training and causal perturbation during testing. Specifically, during the training phase, we employ entropy-based causal intervention (EnIn) to refine the selection of causal variables. To identify samples with anti-interference causal variables from the target domain, we propose a novel metric, homeostatic score, through causal perturbation (HoPer) to construct a prototype classifier in test time. Experimental results across multiple cross-domain tasks confirm the efficacy of InPer.
InPer: Whole-Process Domain Generalization via Causal Intervention and Perturbation
Aug 07, 2024Despite the considerable advancements achieved by deep neural networks, their performance tends to degenerate when the test environment diverges from the training ones. Domain generalization (DG) solves this issue by learning representations independent of domain-related information, thus facilitating extrapolation to unseen environments. Existing approaches typically focus on formulating tailored training objectives to extract shared features from the source data. However, the disjointed training and testing procedures may compromise robustness, particularly in the face of unforeseen variations during deployment. In this paper, we propose a novel and holistic framework based on causality, named InPer, designed to enhance model generalization by incorporating causal intervention during training and causal perturbation during testing. Specifically, during the training phase, we employ entropy-based causal intervention (EnIn) to refine the selection of causal variables. To identify samples with anti-interference causal variables from the target domain, we propose a novel metric, homeostatic score, through causal perturbation (HoPer) to construct a prototype classifier in test time. Experimental results across multiple cross-domain tasks confirm the efficacy of InPer.
Activate and Reject: Towards Safe Domain Generalization under Category Shift
Oct 07, 2023



Albeit the notable performance on in-domain test points, it is non-trivial for deep neural networks to attain satisfactory accuracy when deploying in the open world, where novel domains and object classes often occur. In this paper, we study a practical problem of Domain Generalization under Category Shift (DGCS), which aims to simultaneously detect unknown-class samples and classify known-class samples in the target domains. Compared to prior DG works, we face two new challenges: 1) how to learn the concept of ``unknown'' during training with only source known-class samples, and 2) how to adapt the source-trained model to unseen environments for safe model deployment. To this end, we propose a novel Activate and Reject (ART) framework to reshape the model's decision boundary to accommodate unknown classes and conduct post hoc modification to further discriminate known and unknown classes using unlabeled test data. Specifically, during training, we promote the response to the unknown by optimizing the unknown probability and then smoothing the overall output to mitigate the overconfidence issue. At test time, we introduce a step-wise online adaptation method that predicts the label by virtue of the cross-domain nearest neighbor and class prototype information without updating the network's parameters or using threshold-based mechanisms. Experiments reveal that ART consistently improves the generalization capability of deep networks on different vision tasks. For image classification, ART improves the H-score by 6.1% on average compared to the previous best method. For object detection and semantic segmentation, we establish new benchmarks and achieve competitive performance.
SRCD: Semantic Reasoning with Compound Domains for Single-Domain Generalized Object Detection
Jul 09, 2023This paper provides a novel framework for single-domain generalized object detection (i.e., Single-DGOD), where we are interested in learning and maintaining the semantic structures of self-augmented compound cross-domain samples to enhance the model's generalization ability. Different from DGOD trained on multiple source domains, Single-DGOD is far more challenging to generalize well to multiple target domains with only one single source domain. Existing methods mostly adopt a similar treatment from DGOD to learn domain-invariant features by decoupling or compressing the semantic space. However, there may have two potential limitations: 1) pseudo attribute-label correlation, due to extremely scarce single-domain data; and 2) the semantic structural information is usually ignored, i.e., we found the affinities of instance-level semantic relations in samples are crucial to model generalization. In this paper, we introduce Semantic Reasoning with Compound Domains (SRCD) for Single-DGOD. Specifically, our SRCD contains two main components, namely, the texture-based self-augmentation (TBSA) module, and the local-global semantic reasoning (LGSR) module. TBSA aims to eliminate the effects of irrelevant attributes associated with labels, such as light, shadow, color, etc., at the image level by a light-yet-efficient self-augmentation. Moreover, LGSR is used to further model the semantic relationships on instance features to uncover and maintain the intrinsic semantic structures. Extensive experiments on multiple benchmarks demonstrate the effectiveness of the proposed SRCD.
Mix and Reason: Reasoning over Semantic Topology with Data Mixing for Domain Generalization
Oct 14, 2022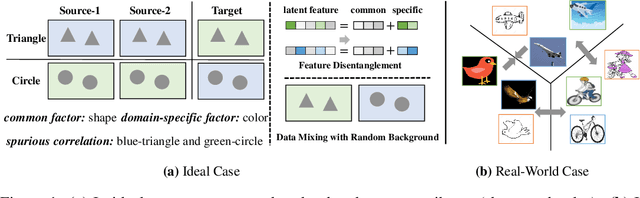
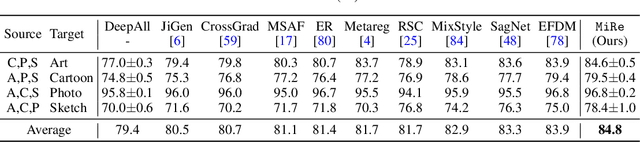
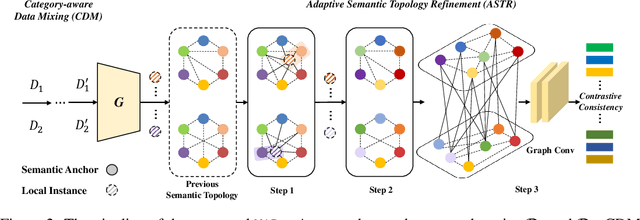
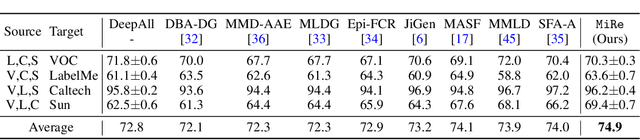
Domain generalization (DG) enables generalizing a learning machine from multiple seen source domains to an unseen target one. The general objective of DG methods is to learn semantic representations that are independent of domain labels, which is theoretically sound but empirically challenged due to the complex mixture of common and domain-specific factors. Although disentangling the representations into two disjoint parts has been gaining momentum in DG, the strong presumption over the data limits its efficacy in many real-world scenarios. In this paper, we propose Mix and Reason (\mire), a new DG framework that learns semantic representations via enforcing the structural invariance of semantic topology. \mire\ consists of two key components, namely, Category-aware Data Mixing (CDM) and Adaptive Semantic Topology Refinement (ASTR). CDM mixes two images from different domains in virtue of activation maps generated by two complementary classification losses, making the classifier focus on the representations of semantic objects. ASTR introduces relation graphs to represent semantic topology, which is progressively refined via the interactions between local feature aggregation and global cross-domain relational reasoning. Experiments on multiple DG benchmarks validate the effectiveness and robustness of the proposed \mire.