 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIFT: LLM-Guided State-Reward Interface for Financial Reinforcement Learning
Jun 07, 2026Financial portfolio trading is naturally formulated as a reinforcement learning problem, where an agent sequentially rebalances assets under changing market conditions to balance return, risk, and transaction costs. Yet in non-stationary markets, raw OHLCV states and short-horizon return rewards often provide an under-specified learning interface, motivating large language models as a way to inject financial knowledge into state and reward design while constraining open-ended generation. To this end, we propose GIFT, an LLM-guided framework for state-reward interface design in PPO-based financial reinforcement learning. Rather than using the LLM to make trading decisions, GIFT uses Factor-guided State Enhancement to generate state features from financial-factor primitives, Risk-rule-guided Reward Shaping to generate auxiliary rewards from portfolio-risk rules, and Diagnostic-guided Refinement to revise candidate interfaces using PPO rollout diagnostics. After refinement, GIFT fixes the selected state-reward interface before evaluation, with no further LLM queries or interface updates at test time. Comprehensive rolling-window experiments across diverse market regimes and portfolio scenarios demonstrate that GIFT improves learning-signal quality and out-of-sample risk-adjusted portfolio performance over baselines. Code and data are available at: https://github.com/KAG778/GIFT .
On the Role of Language Representations in Auto-Bidding: Findings and Implications
May 07, 2026Auto-bidding is a crucial task in real-time advertising markets, where policies must optimize long-horizon value under delivery constraints (e.g., budget and CPA). Existing methods for auto-bidding rely on compact numerical state representations: while they can implicitly capture delivery dynamics, they offer limited support for explicitly representing and controlling high-level intent, evolving feedback, and operator-style strategic guidance in real campaigns. Meanwhile, Large Language Models (LLMs) offer a powerful method for encoding semantic information, it remains unclear when LLMs help and how to integrate them without sacrificing numerical precision. Through systematic preliminary studies, we find that (1) LLM embeddings contain bidding-relevant cues yet cannot replace numerical features, and (2) gains emerge only with careful semantic--numeric integration rather than naive concatenation. Motivated by these findings, we propose \textit{SemBid}, a novel auto-bidding framework that injects LLM-encoded semantics into offline bidding trajectories at the token level. SemBid introduces three semantic inputs: \textit{Task}, \textit{History}, and \textit{Strategy}. It injects these semantics as tokens alongside numerical trajectory tokens and uses self-attention to integrate them, improving controllability and generalization across objectives. Across diverse scenarios and budget regimes, SemBid outperforms competitive baselines from offline RL and generative sequence modeling, with more consistent gains in overall performance, constraint satisfaction, and robustness. Our code is available at: \href{https://github.com/AlanYu04/SemBid-KDD2026}{\textcolor{blue}{here}}.
Chain of Mindset: Reasoning with Adaptive Cognitive Modes
Feb 10, 2026Human problem-solving is never the repetition of a single mindset, by which we mean a distinct mode of cognitive processing. When tackling a specific task, we do not rely on a single mindset; instead, we integrate multiple mindsets within the single solution process. However, existing LLM reasoning methods fall into a common trap: they apply the same fixed mindset across all steps, overlooking that different stages of solving the same problem require fundamentally different mindsets. This single-minded assumption prevents models from reaching the next level of intelligence. To address this limitation, we propose Chain of Mindset (CoM), a training-free agentic framework that enables step-level adaptive mindset orchestration. CoM decomposes reasoning into four functionally heterogeneous mindsets: Spatial, Convergent, Divergent, and Algorithmic. A Meta-Agent dynamically selects the optimal mindset based on the evolving reasoning state, while a bidirectional Context Gate filters cross-module information flow to maintain effectiveness and efficiency. Experiments across six challenging benchmarks spanning mathematics, code generation, scientific QA, and spatial reasoning demonstrate that CoM achieves state-of-the-art performance, outperforming the strongest baseline by 4.96\% and 4.72\% in overall accuracy on Qwen3-VL-32B-Instruct and Gemini-2.0-Flash, while balancing reasoning efficiency. Our code is publicly available at \href{https://github.com/QuantaAlpha/chain-of-mindset}{https://github.com/QuantaAlpha/chain-of-mindset}.
Benchmarking Multimodal Large Language Models for Missing Modality Completion in Product Catalogues
Jan 28, 2026Missing-modality information on e-commerce platforms, such as absent product images or textual descriptions, often arises from annotation errors or incomplete metadata, impairing both product presentation and downstream applications such as recommendation systems. Motivated by the multimodal generative capabilities of recent Multimodal Large Language Models (MLLMs), this work investigates a fundamental yet underexplored question: can MLLMs generate missing modalities for products in e-commerce scenarios? We propose the Missing Modality Product Completion Benchmark (MMPCBench), which consists of two sub-benchmarks: a Content Quality Completion Benchmark and a Recommendation Benchmark. We further evaluate six state-of-the-art MLLMs from the Qwen2.5-VL and Gemma-3 model families across nine real-world e-commerce categories, focusing on image-to-text and text-to-image completion tasks. Experimental results show that while MLLMs can capture high-level semantics, they struggle with fine-grained word-level and pixel- or patch-level alignment. In addition, performance varies substantially across product categories and model scales, and we observe no trivial correlation between model size and performance, in contrast to trends commonly reported in mainstream benchmarks. We also explore Group Relative Policy Optimization (GRPO) to better align MLLMs with this task. GRPO improves image-to-text completion but does not yield gains for text-to-image completion. Overall, these findings expose the limitations of current MLLMs in real-world cross-modal generation and represent an early step toward more effective missing-modality product completion.
PhysicsMind: Sim and Real Mechanics Benchmarking for Physical Reasoning and Prediction in Foundational VLMs and World Models
Jan 22, 2026Modern foundational Multimodal Large Language Models (MLLMs) and video world models have advanced significantly in mathematical, common-sense, and visual reasoning, but their grasp of the underlying physics remains underexplored. Existing benchmarks attempting to measure this matter rely on synthetic, Visual Question Answer templates or focus on perceptual video quality that is tangential to measuring how well the video abides by physical laws. To address this fragmentation, we introduce PhysicsMind, a unified benchmark with both real and simulation environments that evaluates law-consistent reasoning and generation over three canonical principles: Center of Mass, Lever Equilibrium, and Newton's First Law. PhysicsMind comprises two main tasks: i) VQA tasks, testing whether models can reason and determine physical quantities and values from images or short videos, and ii) Video Generation(VG) tasks, evaluating if predicted motion trajectories obey the same center-of-mass, torque, and inertial constraints as the ground truth. A broad range of recent models and video generation models is evaluated on PhysicsMind and found to rely on appearance heuristics while often violating basic mechanics. These gaps indicate that current scaling and training are still insufficient for robust physical understanding, underscoring PhysicsMind as a focused testbed for physics-aware multimodal models. Our data will be released upon acceptance.
Teach Me How to Denoise: A Universal Framework for Denoising Multi-modal Recommender Systems via Guided Calibration
Apr 19, 2025The surge in multimedia content has led to the development of Multi-Modal Recommender Systems (MMRecs), which use diverse modalities such as text, images, videos, and audio for more personalized recommendations. However, MMRecs struggle with noisy data caused by misalignment among modal content and the gap between modal semantics and recommendation semantics. Traditional denoising methods are inadequate due to the complexity of multi-modal data. To address this, we propose a universal guided in-sync distillation denoising framework for multi-modal recommendation (GUIDER), designed to improve MMRecs by denoising user feedback. Specifically, GUIDER uses a re-calibration strategy to identify clean and noisy interactions from modal content. It incorporates a Denoising Bayesian Personalized Ranking (DBPR) loss function to handle implicit user feedback. Finally, it applies a denoising knowledge distillation objective based on Optimal Transport distance to guide the alignment from modality representations to recommendation semantics. GUIDER can be seamlessly integrated into existing MMRecs methods as a plug-and-play solution. Experimental results on four public datasets demonstrate its effectiveness and generalizability. Our source code is available at https://github.com/Neon-Jing/Guider
CROSSAN: Towards Efficient and Effective Adaptation of Multiple Multimodal Foundation Models for Sequential Recommendation
Apr 14, 2025Multimodal Foundation Models (MFMs) excel at representing diverse raw modalities (e.g., text, images, audio, videos, etc.). As recommender systems increasingly incorporate these modalities, leveraging MFMs to generate better representations has great potential. However, their application in sequential recommendation remains largely unexplored. This is primarily because mainstream adaptation methods, such as Fine-Tuning and even Parameter-Efficient Fine-Tuning (PEFT) techniques (e.g., Adapter and LoRA), incur high computational costs, especially when integrating multiple modality encoders, thus hindering research progress. As a result, it remains unclear whether we can efficiently and effectively adapt multiple (>2) MFMs for the sequential recommendation task. To address this, we propose a plug-and-play Cross-modal Side Adapter Network (CROSSAN). Leveraging the fully decoupled side adapter-based paradigm, CROSSAN achieves high efficiency while enabling cross-modal learning across diverse modalities. To optimize the final stage of multimodal fusion across diverse modalities, we adopt the Mixture of Modality Expert Fusion (MOMEF) mechanism. CROSSAN achieves superior performance on the public datasets for adapting four foundation models with raw modalities. Performance consistently improves as more MFMs are adapted. We will release our code and datasets to facilitate future research.
ContrastiveGaussian: High-Fidelity 3D Generation with Contrastive Learning and Gaussian Splatting
Apr 10, 2025Creating 3D content from single-view images is a challenging problem that has attracted considerable attention in recent years. Current approaches typically utilize score distillation sampling (SDS) from pre-trained 2D diffusion models to generate multi-view 3D representations. Although some methods have made notable progress by balancing generation speed and model quality, their performance is often limited by the visual inconsistencies of the diffusion model outputs. In this work, we propose ContrastiveGaussian, which integrates contrastive learning into the generative process. By using a perceptual loss, we effectively differentiate between positive and negative samples, leveraging the visual inconsistencies to improve 3D generation quality. To further enhance sample differentiation and improve contrastive learning, we incorporate a super-resolution model and introduce another Quantity-Aware Triplet Loss to address varying sample distributions during training. Our experiments demonstrate that our approach achieves superior texture fidelity and improved geometric consistency.
Video-Bench: Human-Aligned Video Generation Benchmark
Apr 07, 2025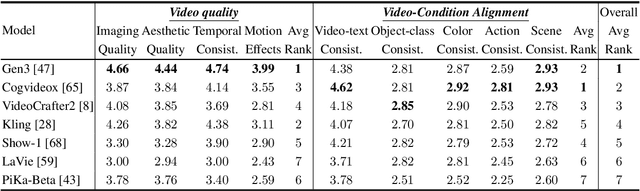
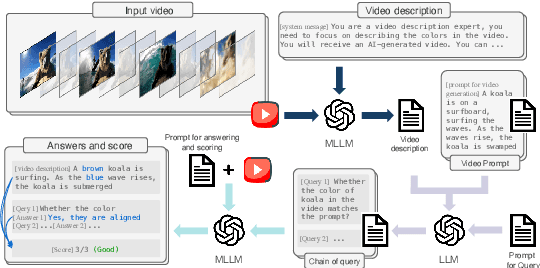
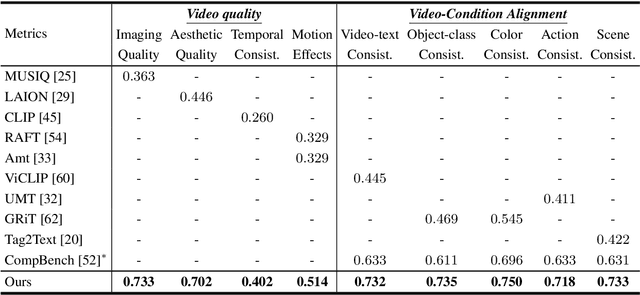
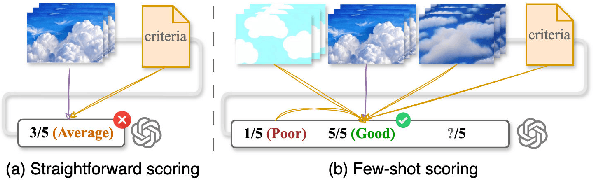
Video generation assessment is essential for ensuring that generative models produce visually realistic, high-quality videos while aligning with human expectations. Current video generation benchmarks fall into two main categories: traditional benchmarks, which use metrics and embeddings to evaluate generated video quality across multiple dimensions but often lack alignment with human judgments; and large language model (LLM)-based benchmarks, though capable of human-like reasoning, are constrained by a limited understanding of video quality metrics and cross-modal consistency. To address these challenges and establish a benchmark that better aligns with human preferences, this paper introduces Video-Bench, a comprehensive benchmark featuring a rich prompt suite and extensive evaluation dimensions. This benchmark represents the first attempt to systematically leverage MLLMs across all dimensions relevant to video generation assessment in generative models. By incorporating few-shot scoring and chain-of-query techniques, Video-Bench provides a structured, scalable approach to generated video evaluation. Experiments on advanced models including Sora demonstrate that Video-Bench achieves superior alignment with human preferences across all dimensions. Moreover, in instances where our framework's assessments diverge from human evaluations, it consistently offers more objective and accurate insights, suggesting an even greater potential advantage over traditional human judgment.
Uncertainty-aware Knowledge Tracing
Jan 09, 2025Knowledge Tracing (KT) is crucial in education assessment, which focuses on depicting students' learning states and assessing students' mastery of subjects. With the rise of modern online learning platforms, particularly massive open online courses (MOOCs), an abundance of interaction data has greatly advanced the development of the KT technology. Previous research commonly adopts deterministic representation to capture students' knowledge states, which neglects the uncertainty during student interactions and thus fails to model the true knowledge state in learning process. In light of this, we propose an Uncertainty-Aware Knowledge Tracing model (UKT) which employs stochastic distribution embeddings to represent the uncertainty in student interactions, with a Wasserstein self-attention mechanism designed to capture the transition of state distribution in student learning behaviors. Additionally, we introduce the aleatory uncertainty-aware contrastive learning loss, which strengthens the model's robustness towards different types of uncertainties. Extensive experiments on six real-world datasets demonstrate that UKT not only significantly surpasses existing deep learning-based models in KT prediction, but also shows unique advantages in handling the uncertainty of student interactions.