 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe 2nd EReL@MIR Workshop on Efficient Representation Learning for Multimodal Information Retrieval
May 26, 2026Multimodal representation learning has attracted increasing attention in AI, driven by the strong performance of large, pretrained multimodal foundation models such as Qwen, LLaVA, and CLIP. These models deliver impressive performance on a range of multimodal information retrieval (MIR) tasks, including web search, cross-modal retrieval, and recommender systems. Yet their massive parameter counts create major efficiency bottlenecks when adapting their representations for IR tasks during training, deployment, and inference. These limitations hinder the practical use of foundation models for representation learning in information retrieval. To address these issues, we propose organizing the EReL@MIR workshop at MM 2026, bringing together researchers from academia and industry to discuss emerging solutions, open challenges, and new efficiency metrics and benchmarks for multimodal IR representation learning in the foundation-model era. The workshop's official website is available at https://erel-mir.github.io/.
Benchmarking Multimodal Large Language Models for Missing Modality Completion in Product Catalogues
Jan 28, 2026Missing-modality information on e-commerce platforms, such as absent product images or textual descriptions, often arises from annotation errors or incomplete metadata, impairing both product presentation and downstream applications such as recommendation systems. Motivated by the multimodal generative capabilities of recent Multimodal Large Language Models (MLLMs), this work investigates a fundamental yet underexplored question: can MLLMs generate missing modalities for products in e-commerce scenarios? We propose the Missing Modality Product Completion Benchmark (MMPCBench), which consists of two sub-benchmarks: a Content Quality Completion Benchmark and a Recommendation Benchmark. We further evaluate six state-of-the-art MLLMs from the Qwen2.5-VL and Gemma-3 model families across nine real-world e-commerce categories, focusing on image-to-text and text-to-image completion tasks. Experimental results show that while MLLMs can capture high-level semantics, they struggle with fine-grained word-level and pixel- or patch-level alignment. In addition, performance varies substantially across product categories and model scales, and we observe no trivial correlation between model size and performance, in contrast to trends commonly reported in mainstream benchmarks. We also explore Group Relative Policy Optimization (GRPO) to better align MLLMs with this task. GRPO improves image-to-text completion but does not yield gains for text-to-image completion. Overall, these findings expose the limitations of current MLLMs in real-world cross-modal generation and represent an early step toward more effective missing-modality product completion.
Differentiable Semantic ID for Generative Recommendation
Jan 27, 2026Generative recommendation provides a novel paradigm in which each item is represented by a discrete semantic ID (SID) learned from rich content. Most existing methods treat SIDs as predefined and train recommenders under static indexing. In practice, SIDs are typically optimized only for content reconstruction rather than recommendation accuracy. This leads to an objective mismatch: the system optimizes an indexing loss to learn the SID and a recommendation loss for interaction prediction, but because the tokenizer is trained independently, the recommendation loss cannot update it. A natural approach is to make semantic indexing differentiable so that recommendation gradients can directly influence SID learning, but this often causes codebook collapse, where only a few codes are used. We attribute this issue to early deterministic assignments that limit codebook exploration, resulting in imbalance and unstable optimization. In this paper, we propose DIGER (Differentiable Semantic ID for Generative Recommendation), a first step toward effective differentiable semantic IDs for generative recommendation. DIGER introduces Gumbel noise to explicitly encourage early-stage exploration over codes, mitigating codebook collapse and improving code utilization. To balance exploration and convergence, we further design two uncertainty decay strategies that gradually reduce the Gumbel noise, enabling a smooth transition from early exploration to exploitation of learned SIDs. Extensive experiments on multiple public datasets demonstrate consistent improvements from differentiable semantic IDs. These results confirm the effectiveness of aligning indexing and recommendation objectives through differentiable SIDs and highlight differentiable semantic indexing as a promising research direction.
Focal-RegionFace: Generating Fine-Grained Multi-attribute Descriptions for Arbitrarily Selected Face Focal Regions
Jan 01, 2026In this paper, we introduce an underexplored problem in facial analysis: generating and recognizing multi-attribute natural language descriptions, containing facial action units (AUs), emotional states, and age estimation, for arbitrarily selected face regions (termed FaceFocalDesc). We argue that the system's ability to focus on individual facial areas leads to better understanding and control. To achieve this capability, we construct a new multi-attribute description dataset for arbitrarily selected face regions, providing rich region-level annotations and natural language descriptions. Further, we propose a fine-tuned vision-language model based on Qwen2.5-VL, called Focal-RegionFace for facial state analysis, which incrementally refines its focus on localized facial features through multiple progressively fine-tuning stages, resulting in interpretable age estimation, FAU and emotion detection. Experimental results show that Focal-RegionFace achieves the best performance on the new benchmark in terms of traditional and widely used metrics, as well as new proposed metrics. This fully verifies its effectiveness and versatility in fine-grained multi-attribute face region-focal analysis scenarios.
Are Multimodal Embeddings Truly Beneficial for Recommendation? A Deep Dive into Whole vs. Individual Modalities
Aug 10, 2025Multimodal recommendation (MMRec) has emerged as a mainstream paradigm, typically leveraging text and visual embeddings extracted from pre-trained models such as Sentence-BERT, Vision Transformers, and ResNet. This approach is founded on the intuitive assumption that incorporating multimodal embeddings can enhance recommendation performance. However, despite its popularity, this assumption lacks comprehensive empirical verification. This presents a critical research gap. To address it, we pose the central research question of this paper: Are multimodal embeddings truly beneficial for recommendation? To answer this question, we conduct a large-scale empirical study examining the role of text and visual embeddings in modern MMRec models, both as a whole and individually. Specifically, we pose two key research questions: (1) Do multimodal embeddings as a whole improve recommendation performance? (2) Is each individual modality - text and image - useful when used alone? To isolate the effect of individual modalities - text or visual - we employ a modality knockout strategy by setting the corresponding embeddings to either constant values or random noise. To ensure the scale and comprehensiveness of our study, we evaluate 14 widely used state-of-the-art MMRec models. Our findings reveal that: (1) multimodal embeddings generally enhance recommendation performance - particularly when integrated through more sophisticated graph-based fusion models. Surprisingly, commonly adopted baseline models with simple fusion schemes, such as VBPR and BM3, show only limited gains. (2) The text modality alone achieves performance comparable to the full multimodal setting in most cases, whereas the image modality alone does not. These results offer foundational insights and practical guidance for the MMRec community. We will release our code and datasets to facilitate future research.
The 1st EReL@MIR Workshop on Efficient Representation Learning for Multimodal Information Retrieval
Apr 21, 2025Multimodal representation learning has garnered significant attention in the AI community, largely due to the success of large pre-trained multimodal foundation models like LLaMA, GPT, Mistral, and CLIP. These models have achieved remarkable performance across various tasks of multimodal information retrieval (MIR), including web search, cross-modal retrieval, and recommender systems, etc. However, due to their enormous parameter sizes, significant efficiency challenges emerge across training, deployment, and inference stages when adapting these models' representation for IR tasks. These challenges present substantial obstacles to the practical adaptation of foundation models for representation learning in information retrieval tasks. To address these pressing issues, we propose organizing the first EReL@MIR workshop at the Web Conference 2025, inviting participants to explore novel solutions, emerging problems, challenges, efficiency evaluation metrics and benchmarks. This workshop aims to provide a platform for both academic and industry researchers to engage in discussions, share insights, and foster collaboration toward achieving efficient and effective representation learning for multimodal information retrieval in the era of large foundation models.
Teach Me How to Denoise: A Universal Framework for Denoising Multi-modal Recommender Systems via Guided Calibration
Apr 19, 2025The surge in multimedia content has led to the development of Multi-Modal Recommender Systems (MMRecs), which use diverse modalities such as text, images, videos, and audio for more personalized recommendations. However, MMRecs struggle with noisy data caused by misalignment among modal content and the gap between modal semantics and recommendation semantics. Traditional denoising methods are inadequate due to the complexity of multi-modal data. To address this, we propose a universal guided in-sync distillation denoising framework for multi-modal recommendation (GUIDER), designed to improve MMRecs by denoising user feedback. Specifically, GUIDER uses a re-calibration strategy to identify clean and noisy interactions from modal content. It incorporates a Denoising Bayesian Personalized Ranking (DBPR) loss function to handle implicit user feedback. Finally, it applies a denoising knowledge distillation objective based on Optimal Transport distance to guide the alignment from modality representations to recommendation semantics. GUIDER can be seamlessly integrated into existing MMRecs methods as a plug-and-play solution. Experimental results on four public datasets demonstrate its effectiveness and generalizability. Our source code is available at https://github.com/Neon-Jing/Guider
CROSSAN: Towards Efficient and Effective Adaptation of Multiple Multimodal Foundation Models for Sequential Recommendation
Apr 14, 2025Multimodal Foundation Models (MFMs) excel at representing diverse raw modalities (e.g., text, images, audio, videos, etc.). As recommender systems increasingly incorporate these modalities, leveraging MFMs to generate better representations has great potential. However, their application in sequential recommendation remains largely unexplored. This is primarily because mainstream adaptation methods, such as Fine-Tuning and even Parameter-Efficient Fine-Tuning (PEFT) techniques (e.g., Adapter and LoRA), incur high computational costs, especially when integrating multiple modality encoders, thus hindering research progress. As a result, it remains unclear whether we can efficiently and effectively adapt multiple (>2) MFMs for the sequential recommendation task. To address this, we propose a plug-and-play Cross-modal Side Adapter Network (CROSSAN). Leveraging the fully decoupled side adapter-based paradigm, CROSSAN achieves high efficiency while enabling cross-modal learning across diverse modalities. To optimize the final stage of multimodal fusion across diverse modalities, we adopt the Mixture of Modality Expert Fusion (MOMEF) mechanism. CROSSAN achieves superior performance on the public datasets for adapting four foundation models with raw modalities. Performance consistently improves as more MFMs are adapted. We will release our code and datasets to facilitate future research.
Multimodal Representation Learning Techniques for Comprehensive Facial State Analysis
Apr 14, 2025



Multimodal foundation models have significantly improved feature representation by integrating information from multiple modalities, making them highly suitable for a broader set of applications. However, the exploration of multimodal facial representation for understanding perception has been limited. Understanding and analyzing facial states, such as Action Units (AUs) and emotions, require a comprehensive and robust framework that bridges visual and linguistic modalities. In this paper, we present a comprehensive pipeline for multimodal facial state analysis. First, we compile a new Multimodal Face Dataset (MFA) by generating detailed multilevel language descriptions of face, incorporating Action Unit (AU) and emotion descriptions, by leveraging GPT-4o. Second, we introduce a novel Multilevel Multimodal Face Foundation model (MF^2) tailored for Action Unit (AU) and emotion recognition. Our model incorporates comprehensive visual feature modeling at both local and global levels of face image, enhancing its ability to represent detailed facial appearances. This design aligns visual representations with structured AU and emotion descriptions, ensuring effective cross-modal integration. Third, we develop a Decoupled Fine-Tuning Network (DFN) that efficiently adapts MF^2 across various tasks and datasets. This approach not only reduces computational overhead but also broadens the applicability of the foundation model to diverse scenarios. Experimentation show superior performance for AU and emotion detection tasks.
* Accepted by ICME2025
Video-Bench: Human-Aligned Video Generation Benchmark
Apr 07, 2025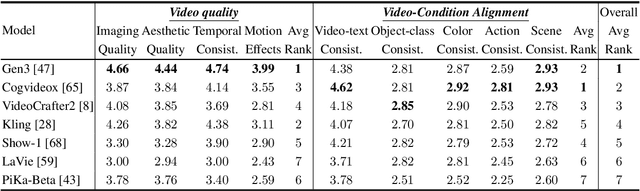
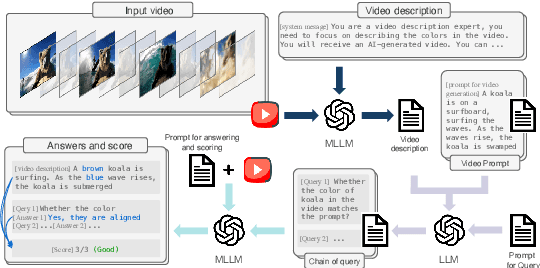
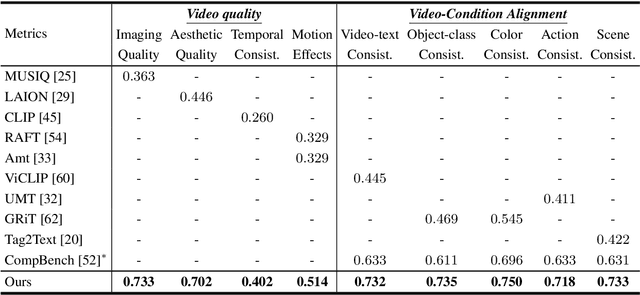
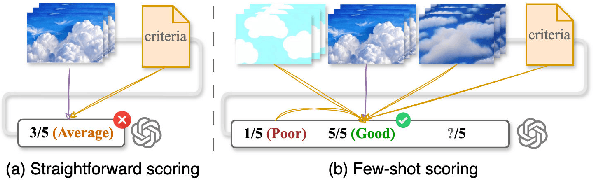
Video generation assessment is essential for ensuring that generative models produce visually realistic, high-quality videos while aligning with human expectations. Current video generation benchmarks fall into two main categories: traditional benchmarks, which use metrics and embeddings to evaluate generated video quality across multiple dimensions but often lack alignment with human judgments; and large language model (LLM)-based benchmarks, though capable of human-like reasoning, are constrained by a limited understanding of video quality metrics and cross-modal consistency. To address these challenges and establish a benchmark that better aligns with human preferences, this paper introduces Video-Bench, a comprehensive benchmark featuring a rich prompt suite and extensive evaluation dimensions. This benchmark represents the first attempt to systematically leverage MLLMs across all dimensions relevant to video generation assessment in generative models. By incorporating few-shot scoring and chain-of-query techniques, Video-Bench provides a structured, scalable approach to generated video evaluation. Experiments on advanced models including Sora demonstrate that Video-Bench achieves superior alignment with human preferences across all dimensions. Moreover, in instances where our framework's assessments diverge from human evaluations, it consistently offers more objective and accurate insights, suggesting an even greater potential advantage over traditional human judgment.