 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SODA: Site Object Detection dAtaset for Deep Learning in Construction
Feb 19, 2022
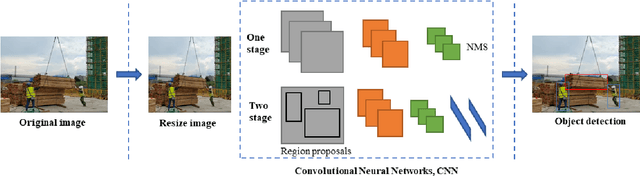
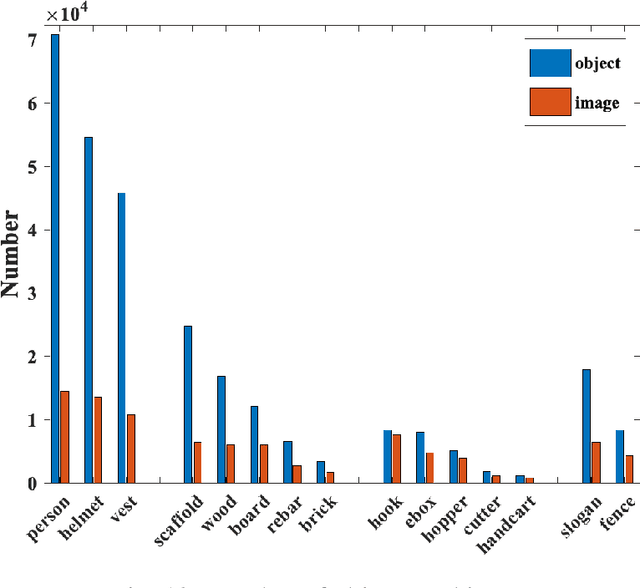
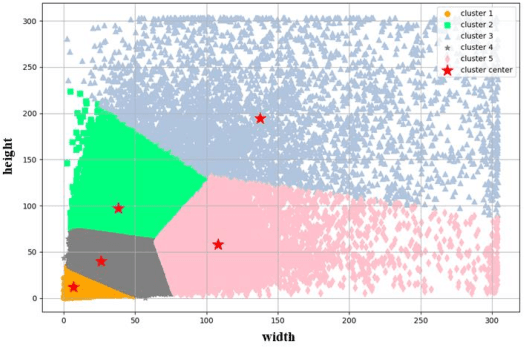
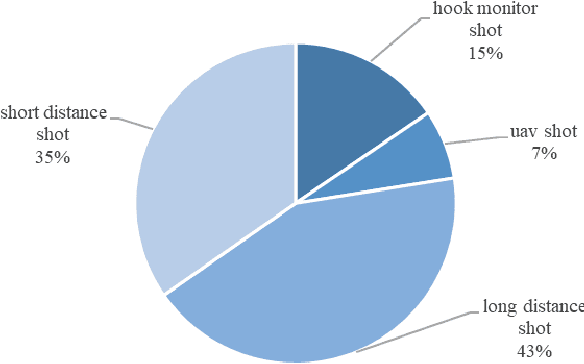
Computer vision-based deep learning object detection algorithms have been developed sufficiently powerful to support the ability to recognize various objects. Although there are currently general datasets for object detection, there is still a lack of large-scale, open-source dataset for the construction industry, which limits the developments of object detection algorithms as they tend to be data-hungry. Therefore, this paper develops a new large-scale image dataset specifically collected and annotated for the construction site, called Site Object Detection dAtaset (SODA), which contains 15 kinds of object classes categorized by workers, materials, machines, and layout. Firstly, more than 20,000 images were collected from multiple construction sites in different site conditions, weather conditions, and construction phases, which covered different angles and perspectives. After careful screening and processing, 19,846 images including 286,201 objects were then obtained and annotated with labels in accordance with predefined categories. Statistical analysis shows that the developed dataset is advantageous in terms of diversity and volume. Further evaluation with two widely-adopted object detection algorithms based on deep learning (YOLO v3/ YOLO v4) also illustrates the feasibility of the dataset for typical construction scenarios, achieving a maximum mAP of 81.47%. In this manner, this research contributes a large-scale image dataset for the development of deep learning-based object detection methods in the construction industry and sets up a performance benchmark for further evaluation of corresponding algorithms in this area.
ImageTBAD: A 3D Computed Tomography Angiography Image Dataset for Automatic Segmentation of Type-B Aortic Dissection
Sep 01, 2021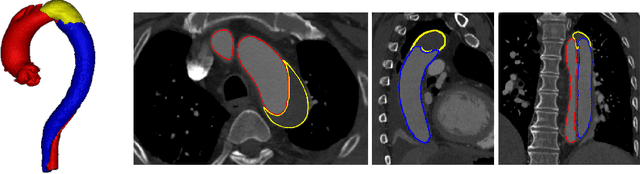

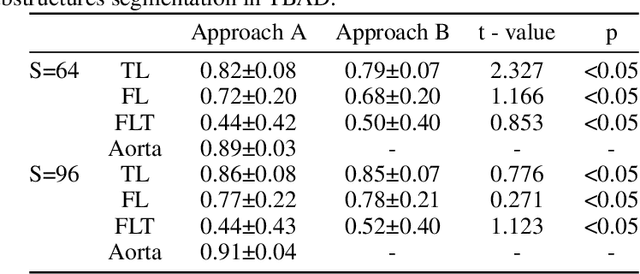
Type-B Aortic Dissection (TBAD) is one of the most serious cardiovascular events characterized by a growing yearly incidence,and the severity of disease prognosis. Currently, computed tomography angiography (CTA) has been widely adopted for the diagnosis and prognosis of TBAD. Accurate segmentation of true lumen (TL), false lumen (FL), and false lumen thrombus (FLT) in CTA are crucial for the precise quantification of anatomical features. However, existing works only focus on only TL and FL without considering FLT. In this paper, we propose ImageTBAD, the first 3D computed tomography angiography (CTA) image dataset of TBAD with annotation of TL, FL, and FLT. The proposed dataset contains 100 TBAD CTA images, which is of decent size compared with existing medical imaging datasets. As FLT can appear almost anywhere along the aorta with irregular shapes, segmentation of FLT presents a wide class of segmentation problems where targets exist in a variety of positions with irregular shapes. We further propose a baseline method for automatic segmentation of TBAD. Results show that the baseline method can achieve comparable results with existing works on aorta and TL segmentation. However, the segmentation accuracy of FLT is only 52%, which leaves large room for improvement and also shows the challenge of our dataset. To facilitate further research on this challenging problem, our dataset and codes are released to the public.
ProFormer: Learning Data-efficient Representations of Body Movement with Prototype-based Feature Augmentation and Visual Transformers
Feb 23, 2022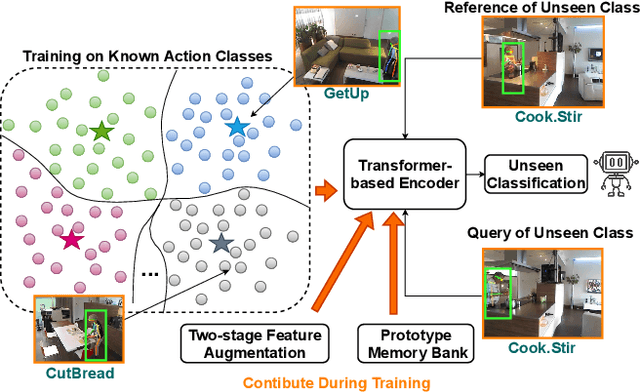
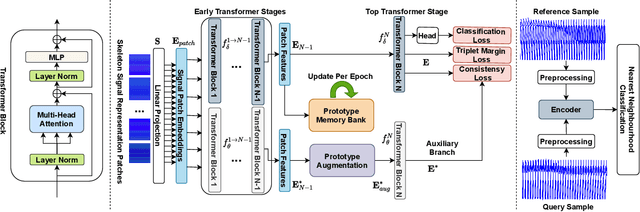
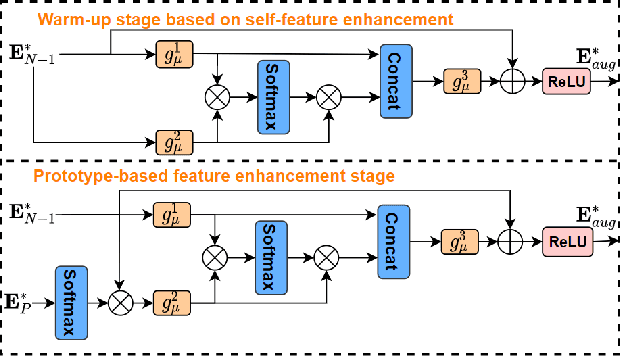
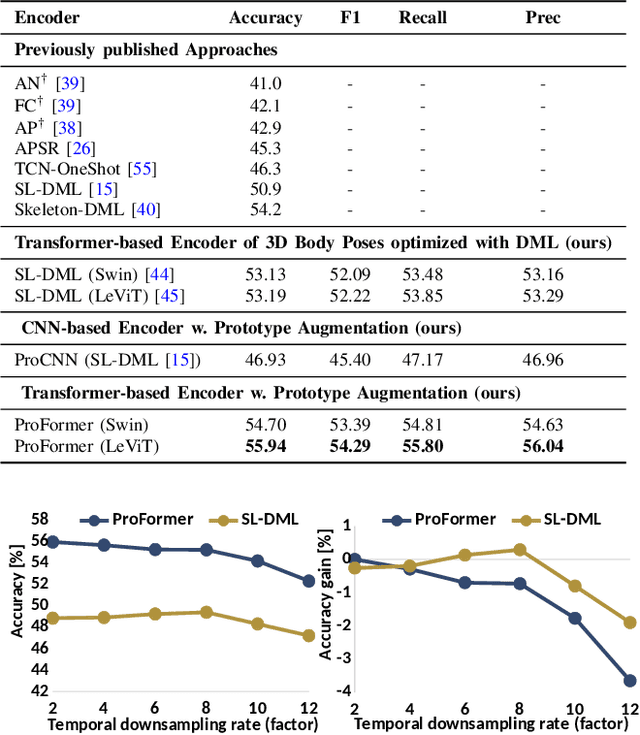
Automatically understanding human behaviour allows household robots to identify the most critical needs and plan how to assist the human according to the current situation. However, the majority of such methods are developed under the assumption that a large amount of labelled training examples is available for all concepts-of-interest. Robots, on the other hand, operate in constantly changing unstructured environments, and need to adapt to novel action categories from very few samples. Methods for data-efficient recognition from body poses increasingly leverage skeleton sequences structured as image-like arrays and then used as input to convolutional neural networks. We look at this paradigm from the perspective of transformer networks, for the first time exploring visual transformers as data-efficient encoders of skeleton movement. In our pipeline, body pose sequences cast as image-like representations are converted into patch embeddings and then passed to a visual transformer backbone optimized with deep metric learning. Inspired by recent success of feature enhancement methods in semi-supervised learning, we further introduce ProFormer -- an improved training strategy which uses soft-attention applied on iteratively estimated action category prototypes used to augment the embeddings and compute an auxiliary consistency loss. Extensive experiments consistently demonstrate the effectiveness of our approach for one-shot recognition from body poses, achieving state-of-the-art results on multiple datasets and surpassing the best published approach on the challenging NTU-120 one-shot benchmark by 1.84%. Our code will be made publicly available at https://github.com/KPeng9510/ProFormer.
SurroundDepth: Entangling Surrounding Views for Self-Supervised Multi-Camera Depth Estimation
Apr 07, 2022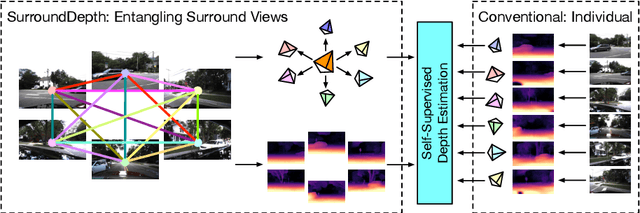
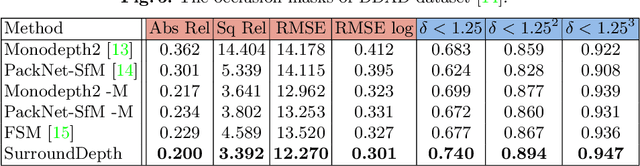
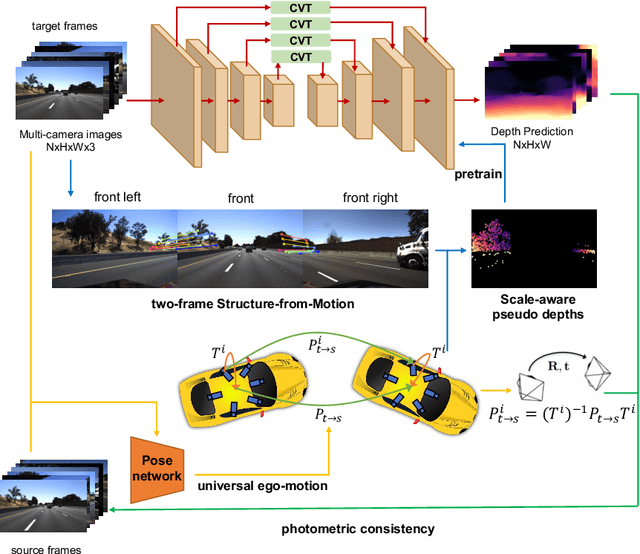

Depth estimation from images serves as the fundamental step of 3D perception for autonomous driving and is an economical alternative to expensive depth sensors like LiDAR. The temporal photometric consistency enables self-supervised depth estimation without labels, further facilitating its application. However, most existing methods predict the depth solely based on each monocular image and ignore the correlations among multiple surrounding cameras, which are typically available for modern self-driving vehicles. In this paper, we propose a SurroundDepth method to incorporate the information from multiple surrounding views to predict depth maps across cameras. Specifically, we employ a joint network to process all the surrounding views and propose a cross-view transformer to effectively fuse the information from multiple views. We apply cross-view self-attention to efficiently enable the global interactions between multi-camera feature maps. Different from self-supervised monocular depth estimation, we are able to predict real-world scales given multi-camera extrinsic matrices. To achieve this goal, we adopt structure-from-motion to extract scale-aware pseudo depths to pretrain the models. Further, instead of predicting the ego-motion of each individual camera, we estimate a universal ego-motion of the vehicle and transfer it to each view to achieve multi-view consistency. In experiments, our method achieves the state-of-the-art performance on the challenging multi-camera depth estimation datasets DDAD and nuScenes.
Realistic Image Normalization for Multi-Domain Segmentation
Oct 01, 2020
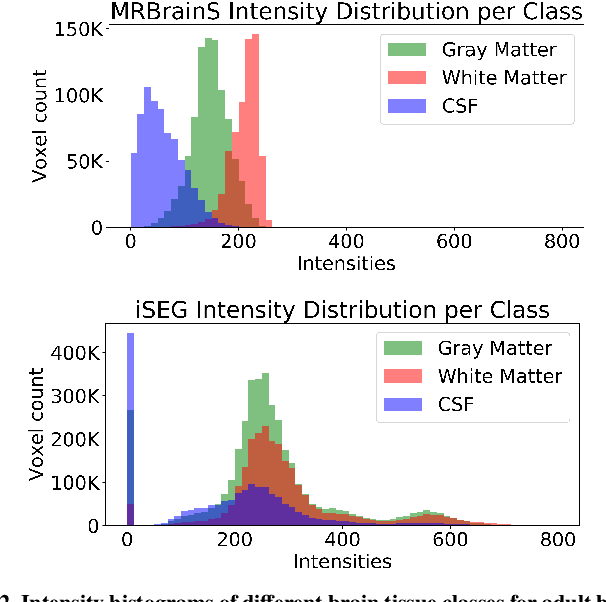
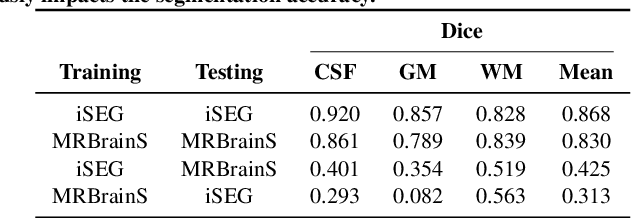
Image normalization is a building block in medical image analysis. Conventional approaches are customarily utilized on a per-dataset basis. This strategy, however, prevents the current normalization algorithms from fully exploiting the complex joint information available across multiple datasets. Consequently, ignoring such joint information has a direct impact on the performance of segmentation algorithms. This paper proposes to revisit the conventional image normalization approach by instead learning a common normalizing function across multiple datasets. Jointly normalizing multiple datasets is shown to yield consistent normalized images as well as an improved image segmentation. To do so, a fully automated adversarial and task-driven normalization approach is employed as it facilitates the training of realistic and interpretable images while keeping performance on-par with the state-of-the-art. The adversarial training of our network aims at finding the optimal transfer function to improve both the segmentation accuracy and the generation of realistic images. We evaluated the performance of our normalizer on both infant and adult brains images from the iSEG, MRBrainS and ABIDE datasets. Results reveal the potential of our normalization approach for segmentation, with Dice improvements of up to 57.5% over our baseline. Our method can also enhance data availability by increasing the number of samples available when learning from multiple imaging domains.
Deep Equilibrium Assisted Block Sparse Coding of Inter-dependent Signals: Application to Hyperspectral Imaging
Mar 29, 2022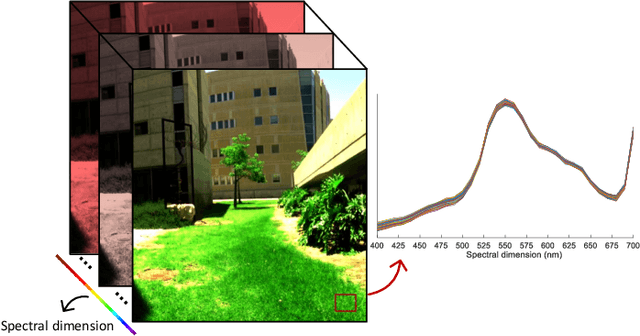
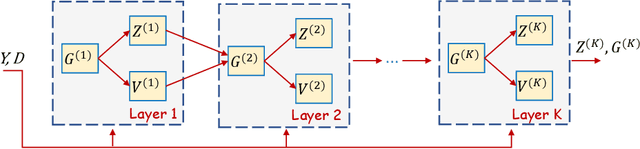
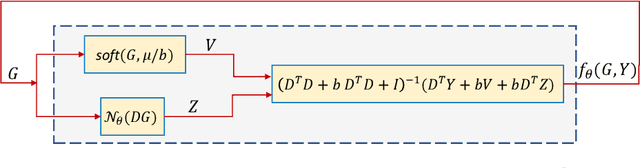
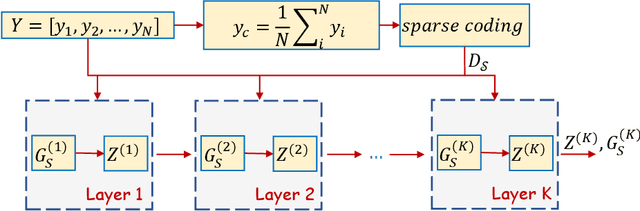
In this study, the problem of computing a sparse representation for datasets of inter-dependent signals, given a fixed dictionary, is considered. A dataset of inter-dependent signals is defined as a matrix whose columns demonstrate strong dependencies. A computational efficient sparse coding optimization problem is derived by employing regularization terms that are adapted to the properties of the signals of interest. Exploiting the merits of the learnable regularization techniques, a neural network is employed to act as structure prior and reveal the underlying signal interdependencies. To solve the optimization problem Deep unrolling and Deep equilibrium based algorithms are developed, forming highly interpretable and concise deep-learning-based architectures, that process the input dataset in a block-by-block fashion. Extensive simulation results, in the context of hyperspectral image denoising, are provided, that demonstrate that the proposed algorithms outperform significantly other sparse coding approaches and exhibit superior performance against recent state-of-the-art deep-learning-based denoising models. In a wider perspective, our work provides a unique bridge between a classic approach, that is the sparse representation theory, and modern representation tools that are based on deep learning modeling.
ACE-BERT: Adversarial Cross-modal Enhanced BERT for E-commerce Retrieval
Dec 14, 2021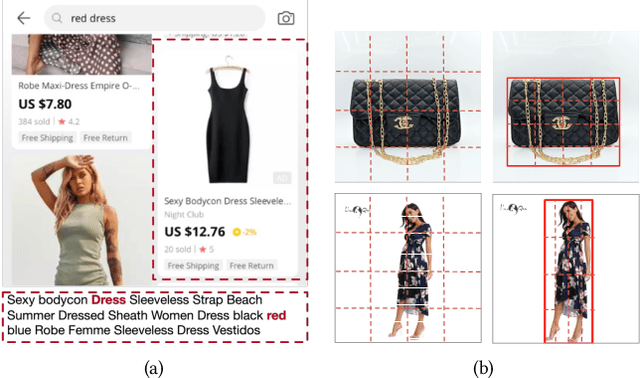

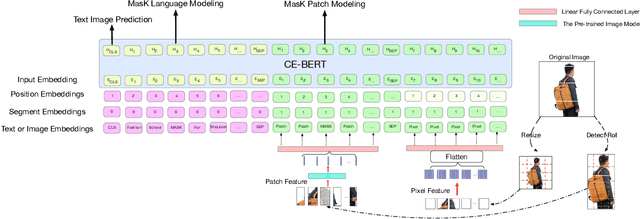

Nowadays on E-commerce platforms, products are presented to the customers with multiple modalities. These multiple modalities are significant for a retrieval system while providing attracted products for customers. Therefore, how to take into account those multiple modalities simultaneously to boost the retrieval performance is crucial. This problem is a huge challenge to us due to the following reasons: (1) the way of extracting patch features with the pre-trained image model (e.g., CNN-based model) has much inductive bias. It is difficult to capture the efficient information from the product image in E-commerce. (2) The heterogeneity of multimodal data makes it challenging to construct the representations of query text and product including title and image in a common subspace. We propose a novel Adversarial Cross-modal Enhanced BERT (ACE-BERT) for efficient E-commerce retrieval. In detail, ACE-BERT leverages the patch features and pixel features as image representation. Thus the Transformer architecture can be applied directly to the raw image sequences. With the pre-trained enhanced BERT as the backbone network, ACE-BERT further adopts adversarial learning by adding a domain classifier to ensure the distribution consistency of different modality representations for the purpose of narrowing down the representation gap between query and product. Experimental results demonstrate that ACE-BERT outperforms the state-of-the-art approaches on the retrieval task. It is remarkable that ACE-BERT has already been deployed in our E-commerce's search engine, leading to 1.46% increase in revenue.
Partial-Attribution Instance Segmentation for Astronomical Source Detection and Deblending
Jan 12, 2022
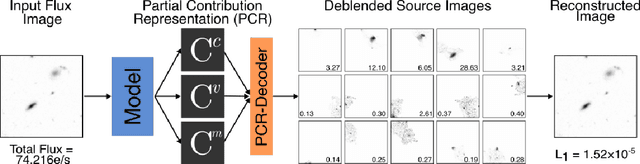
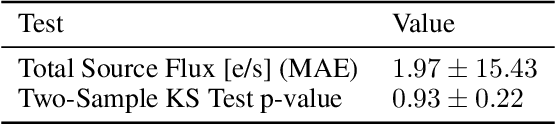
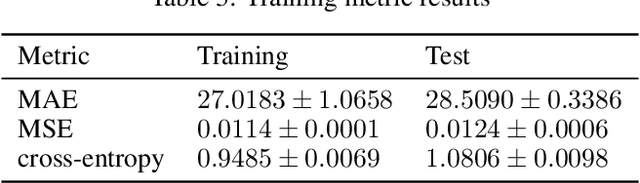
Astronomical source deblending is the process of separating the contribution of individual stars or galaxies (sources) to an image comprised of multiple, possibly overlapping sources. Astronomical sources display a wide range of sizes and brightnesses and may show substantial overlap in images. Astronomical imaging data can further challenge off-the-shelf computer vision algorithms owing to its high dynamic range, low signal-to-noise ratio, and unconventional image format. These challenges make source deblending an open area of astronomical research, and in this work, we introduce a new approach called Partial-Attribution Instance Segmentation that enables source detection and deblending in a manner tractable for deep learning models. We provide a novel neural network implementation as a demonstration of the method.
Unsupervised domain adaptation and super resolution on drone images for autonomous dry herbage biomass estimation
Apr 18, 2022
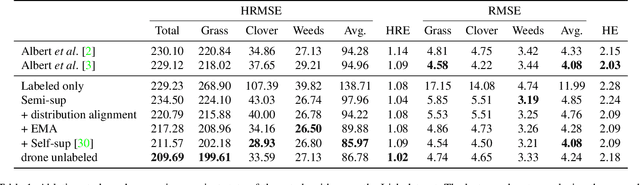

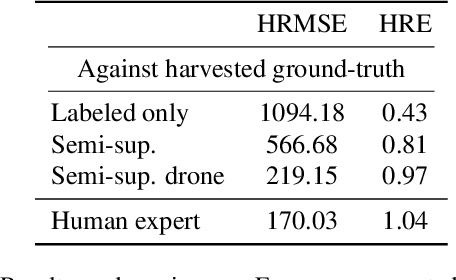
Herbage mass yield and composition estimation is an important tool for dairy farmers to ensure an adequate supply of high quality herbage for grazing and subsequently milk production. By accurately estimating herbage mass and composition, targeted nitrogen fertiliser application strategies can be deployed to improve localised regions in a herbage field, effectively reducing the negative impacts of over-fertilization on biodiversity and the environment. In this context, deep learning algorithms offer a tempting alternative to the usual means of sward composition estimation, which involves the destructive process of cutting a sample from the herbage field and sorting by hand all plant species in the herbage. The process is labour intensive and time consuming and so not utilised by farmers. Deep learning has been successfully applied in this context on images collected by high-resolution cameras on the ground. Moving the deep learning solution to drone imaging, however, has the potential to further improve the herbage mass yield and composition estimation task by extending the ground-level estimation to the large surfaces occupied by fields/paddocks. Drone images come at the cost of lower resolution views of the fields taken from a high altitude and requires further herbage ground-truth collection from the large surfaces covered by drone images. This paper proposes to transfer knowledge learned on ground-level images to raw drone images in an unsupervised manner. To do so, we use unpaired image style translation to enhance the resolution of drone images by a factor of eight and modify them to appear closer to their ground-level counterparts. We then ... ~\url{www.github.com/PaulAlbert31/Clover_SSL}.
STCrowd: A Multimodal Dataset for Pedestrian Perception in Crowded Scenes
Apr 03, 2022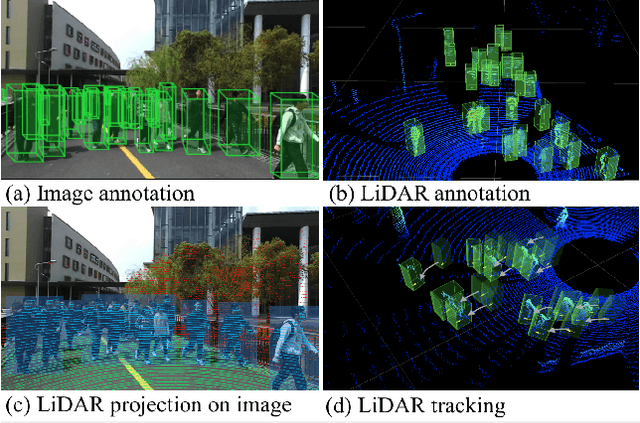
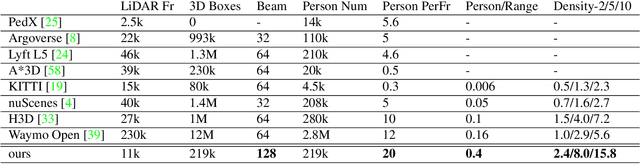

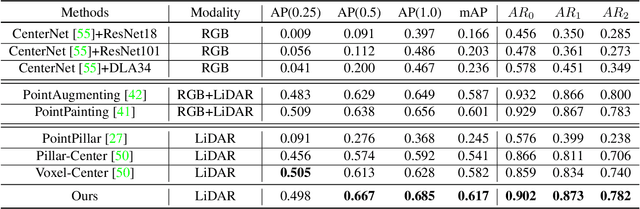
Accurately detecting and tracking pedestrians in 3D space is challenging due to large variations in rotations, poses and scales. The situation becomes even worse for dense crowds with severe occlusions. However, existing benchmarks either only provide 2D annotations, or have limited 3D annotations with low-density pedestrian distribution, making it difficult to build a reliable pedestrian perception system especially in crowded scenes. To better evaluate pedestrian perception algorithms in crowded scenarios, we introduce a large-scale multimodal dataset,STCrowd. Specifically, in STCrowd, there are a total of 219 K pedestrian instances and 20 persons per frame on average, with various levels of occlusion. We provide synchronized LiDAR point clouds and camera images as well as their corresponding 3D labels and joint IDs. STCrowd can be used for various tasks, including LiDAR-only, image-only, and sensor-fusion based pedestrian detection and tracking. We provide baselines for most of the tasks. In addition, considering the property of sparse global distribution and density-varying local distribution of pedestrians, we further propose a novel method, Density-aware Hierarchical heatmap Aggregation (DHA), to enhance pedestrian perception in crowded scenes. Extensive experiments show that our new method achieves state-of-the-art performance for pedestrian detection on various datasets.