 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Diffusion Models as Masked Autoencoders
Apr 06, 2023

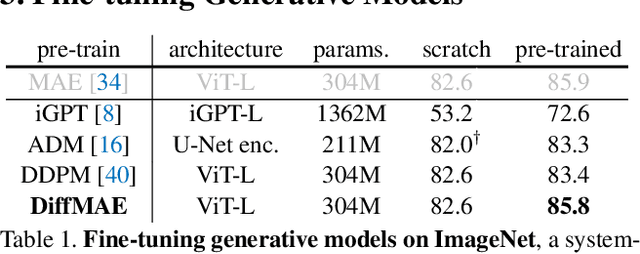

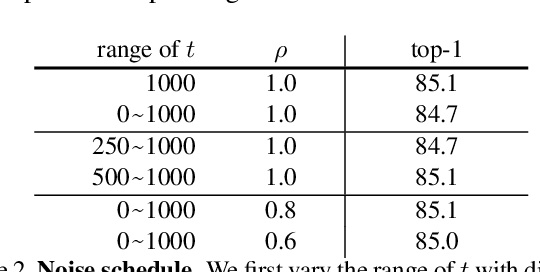
There has been a longstanding belief that generation can facilitate a true understanding of visual data. In line with this, we revisit generatively pre-training visual representations in light of recent interest in denoising diffusion models. While directly pre-training with diffusion models does not produce strong representations, we condition diffusion models on masked input and formulate diffusion models as masked autoencoders (DiffMAE). Our approach is capable of (i) serving as a strong initialization for downstream recognition tasks, (ii) conducting high-quality image inpainting, and (iii) being effortlessly extended to video where it produces state-of-the-art classification accuracy. We further perform a comprehensive study on the pros and cons of design choices and build connections between diffusion models and masked autoencoders.
Anomaly Detection via Gumbel Noise Score Matching
Apr 06, 2023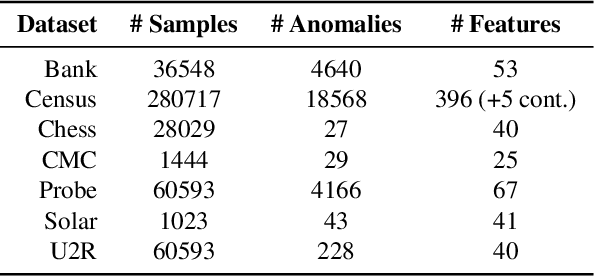
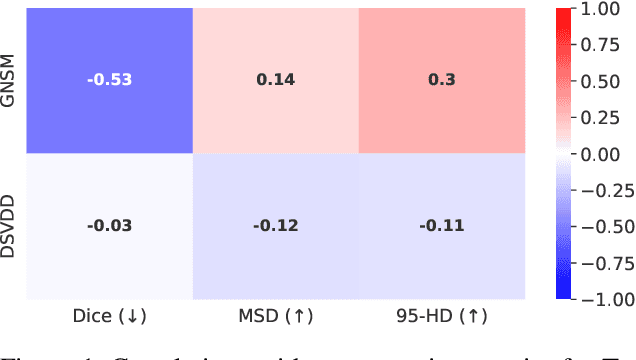
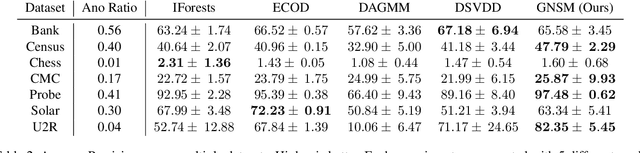

We propose Gumbel Noise Score Matching (GNSM), a novel unsupervised method to detect anomalies in categorical data. GNSM accomplishes this by estimating the scores, i.e. the gradients of log likelihoods w.r.t.~inputs, of continuously relaxed categorical distributions. We test our method on a suite of anomaly detection tabular datasets. GNSM achieves a consistently high performance across all experiments. We further demonstrate the flexibility of GNSM by applying it to image data where the model is tasked to detect poor segmentation predictions. Images ranked anomalous by GNSM show clear segmentation failures, with the outputs of GNSM strongly correlating with segmentation metrics computed on ground-truth. We outline the score matching training objective utilized by GNSM and provide an open-source implementation of our work.
DCFace: Synthetic Face Generation with Dual Condition Diffusion Model
Apr 14, 2023

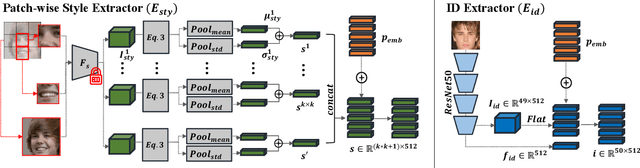
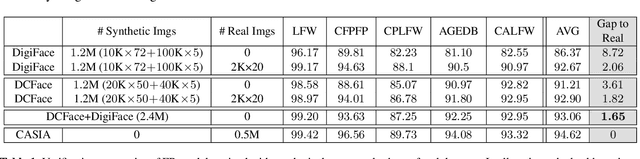
Generating synthetic datasets for training face recognition models is challenging because dataset generation entails more than creating high fidelity images. It involves generating multiple images of same subjects under different factors (\textit{e.g.}, variations in pose, illumination, expression, aging and occlusion) which follows the real image conditional distribution. Previous works have studied the generation of synthetic datasets using GAN or 3D models. In this work, we approach the problem from the aspect of combining subject appearance (ID) and external factor (style) conditions. These two conditions provide a direct way to control the inter-class and intra-class variations. To this end, we propose a Dual Condition Face Generator (DCFace) based on a diffusion model. Our novel Patch-wise style extractor and Time-step dependent ID loss enables DCFace to consistently produce face images of the same subject under different styles with precise control. Face recognition models trained on synthetic images from the proposed DCFace provide higher verification accuracies compared to previous works by $6.11\%$ on average in $4$ out of $5$ test datasets, LFW, CFP-FP, CPLFW, AgeDB and CALFW. Code is available at https://github.com/mk-minchul/dcface
CiPR: An Efficient Framework with Cross-instance Positive Relations for Generalized Category Discovery
Apr 14, 2023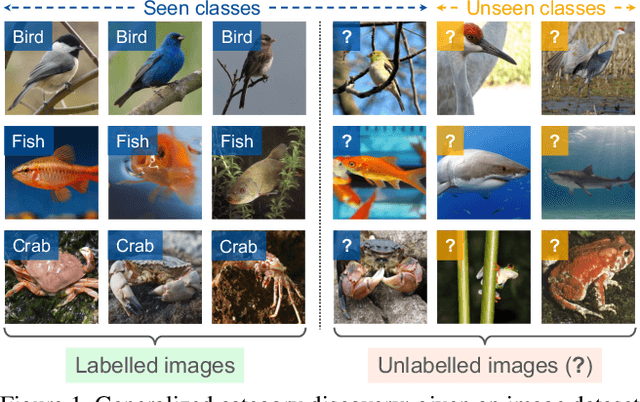
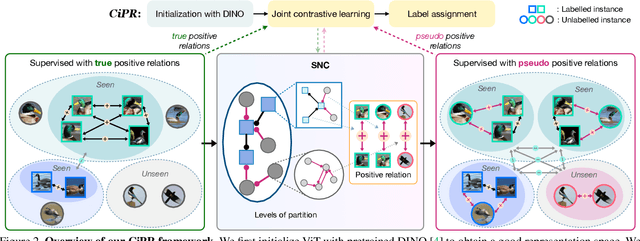
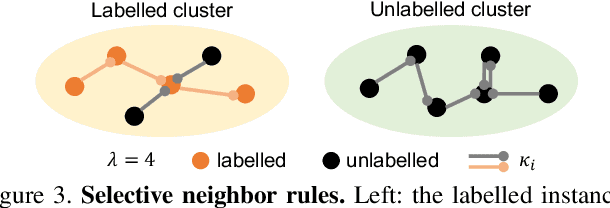
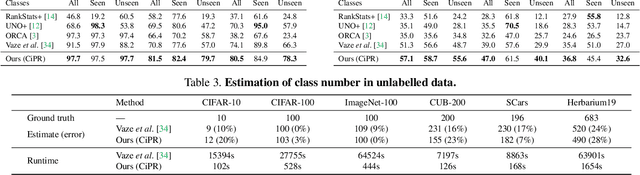
We tackle the issue of generalized category discovery (GCD). GCD considers the open-world problem of automatically clustering a partially labelled dataset, in which the unlabelled data contain instances from novel categories and also the labelled classes. In this paper, we address the GCD problem without a known category number in the unlabelled data. We propose a framework, named CiPR, to bootstrap the representation by exploiting Cross-instance Positive Relations for contrastive learning in the partially labelled data which are neglected in existing methods. First, to obtain reliable cross-instance relations to facilitate the representation learning, we introduce a semi-supervised hierarchical clustering algorithm, named selective neighbor clustering (SNC), which can produce a clustering hierarchy directly from the connected components in the graph constructed by selective neighbors. We also extend SNC to be capable of label assignment for the unlabelled instances with the given class number. Moreover, we present a method to estimate the unknown class number using SNC with a joint reference score considering clustering indexes of both labelled and unlabelled data. Finally, we thoroughly evaluate our framework on public generic image recognition datasets and challenging fine-grained datasets, all establishing the new state-of-the-art.
Tailored Multi-Organ Segmentation with Model Adaptation and Ensemble
Apr 14, 2023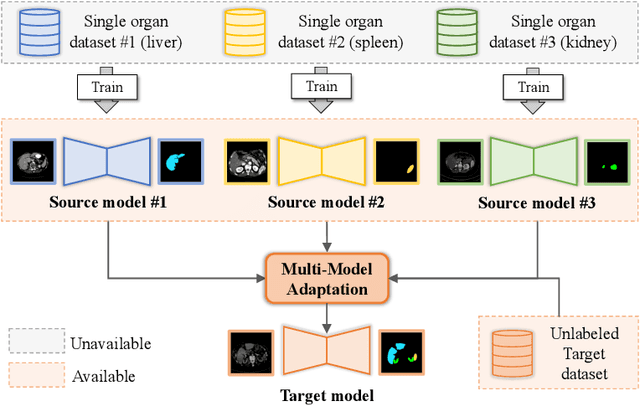
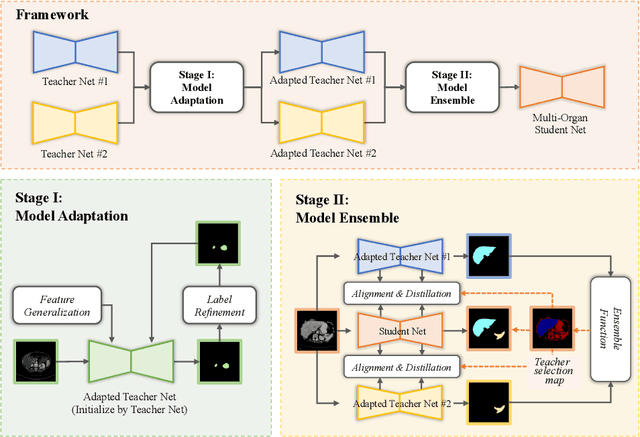
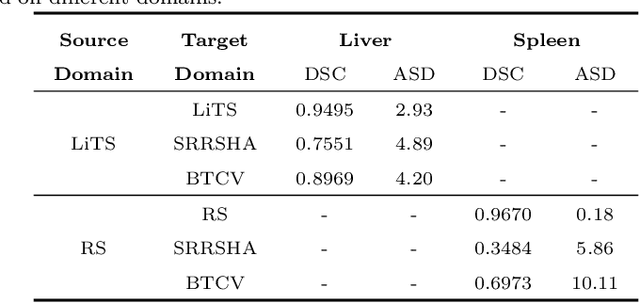
Multi-organ segmentation, which identifies and separates different organs in medical images, is a fundamental task in medical image analysis. Recently, the immense success of deep learning motivated its wide adoption in multi-organ segmentation tasks. However, due to expensive labor costs and expertise, the availability of multi-organ annotations is usually limited and hence poses a challenge in obtaining sufficient training data for deep learning-based methods. In this paper, we aim to address this issue by combining off-the-shelf single-organ segmentation models to develop a multi-organ segmentation model on the target dataset, which helps get rid of the dependence on annotated data for multi-organ segmentation. To this end, we propose a novel dual-stage method that consists of a Model Adaptation stage and a Model Ensemble stage. The first stage enhances the generalization of each off-the-shelf segmentation model on the target domain, while the second stage distills and integrates knowledge from multiple adapted single-organ segmentation models. Extensive experiments on four abdomen datasets demonstrate that our proposed method can effectively leverage off-the-shelf single-organ segmentation models to obtain a tailored model for multi-organ segmentation with high accuracy.
Phantom Embeddings: Using Embedding Space for Model Regularization in Deep Neural Networks
Apr 14, 2023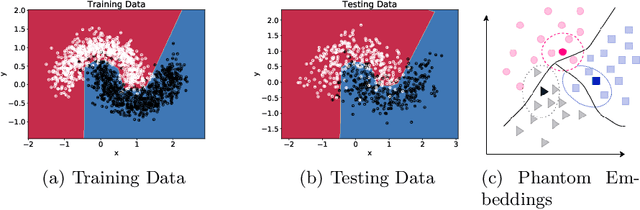
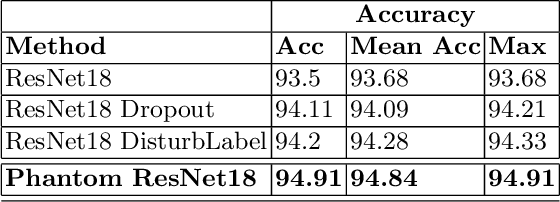
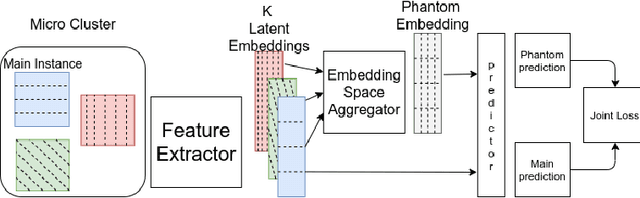
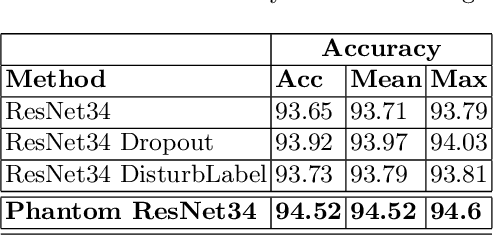
The strength of machine learning models stems from their ability to learn complex function approximations from data; however, this strength also makes training deep neural networks challenging. Notably, the complex models tend to memorize the training data, which results in poor regularization performance on test data. The regularization techniques such as L1, L2, dropout, etc. are proposed to reduce the overfitting effect; however, they bring in additional hyperparameters tuning complexity. These methods also fall short when the inter-class similarity is high due to the underlying data distribution, leading to a less accurate model. In this paper, we present a novel approach to regularize the models by leveraging the information-rich latent embeddings and their high intra-class correlation. We create phantom embeddings from a subset of homogenous samples and use these phantom embeddings to decrease the inter-class similarity of instances in their latent embedding space. The resulting models generalize better as a combination of their embedding and regularize them without requiring an expensive hyperparameter search. We evaluate our method on two popular and challenging image classification datasets (CIFAR and FashionMNIST) and show how our approach outperforms the standard baselines while displaying better training behavior.
MaMMUT: A Simple Architecture for Joint Learning for MultiModal Tasks
Mar 30, 2023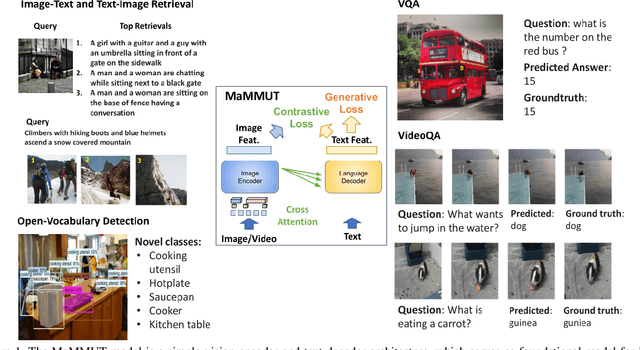
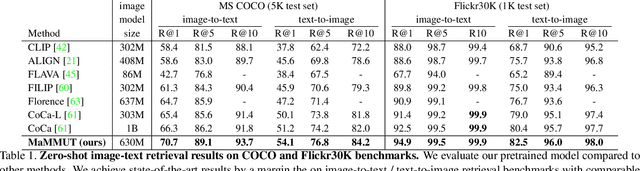
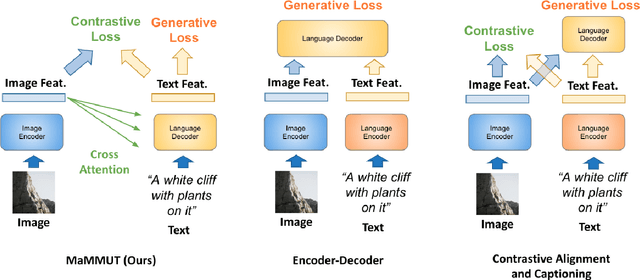
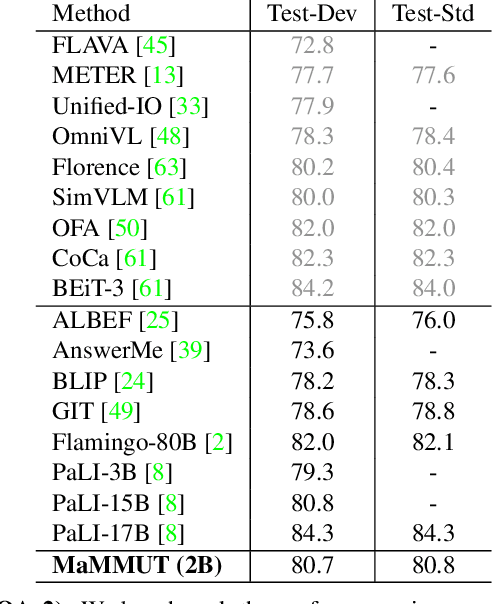
The development of language models have moved from encoder-decoder to decoder-only designs. In addition, the common knowledge has it that the two most popular multimodal tasks, the generative and contrastive tasks, tend to conflict with one another, are hard to accommodate in one architecture, and further need complex adaptations for downstream tasks. We propose a novel paradigm of training with a decoder-only model for multimodal tasks, which is surprisingly effective in jointly learning of these disparate vision-language tasks. This is done with a simple model, called MaMMUT. It consists of a single vision encoder and a text decoder, and is able to accommodate contrastive and generative learning by a novel two-pass approach on the text decoder. We demonstrate that joint learning of these diverse objectives is simple, effective, and maximizes the weight-sharing of the model across these tasks. Furthermore, the same architecture enables straightforward extensions to open-vocabulary object detection and video-language tasks. The model tackles a diverse range of tasks, while being modest in capacity. Our model achieves the state of the art on image-text and text-image retrieval, video question answering and open-vocabulary detection tasks, outperforming much larger and more extensively trained foundational models. It shows very competitive results on VQA and Video Captioning, especially considering its capacity. Ablations confirm the flexibility and advantages of our approach.
Alignment-Enriched Tuning for Patch-Level Pre-trained Document Image Models
Dec 01, 2022
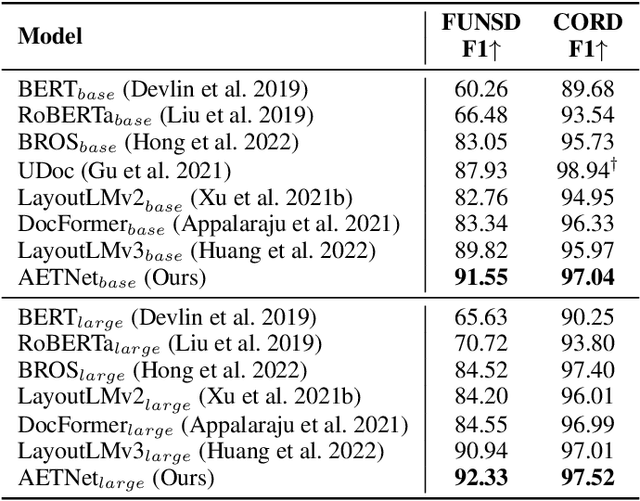
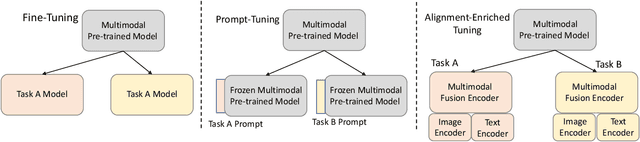

Alignment between image and text has shown promising improvements on patch-level pre-trained document image models. However, investigating more effective or finer-grained alignment techniques during pre-training requires a large amount of computation cost and time. Thus, a question naturally arises: Could we fine-tune the pre-trained models adaptive to downstream tasks with alignment objectives and achieve comparable or better performance? In this paper, we propose a new model architecture with alignment-enriched tuning (dubbed AETNet) upon pre-trained document image models, to adapt downstream tasks with the joint task-specific supervised and alignment-aware contrastive objective. Specifically, we introduce an extra visual transformer as the alignment-ware image encoder and an extra text transformer as the alignment-ware text encoder before multimodal fusion. We consider alignment in the following three aspects: 1) document-level alignment by leveraging the cross-modal and intra-modal contrastive loss; 2) global-local alignment for modeling localized and structural information in document images; and 3) local-level alignment for more accurate patch-level information. Experiments on various downstream tasks show that AETNet can achieve state-of-the-art performance on various downstream tasks. Notably, AETNet consistently outperforms state-of-the-art pre-trained models, such as LayoutLMv3 with fine-tuning techniques, on three different downstream tasks.
Sketch2Saliency: Learning to Detect Salient Objects from Human Drawings
Mar 23, 2023
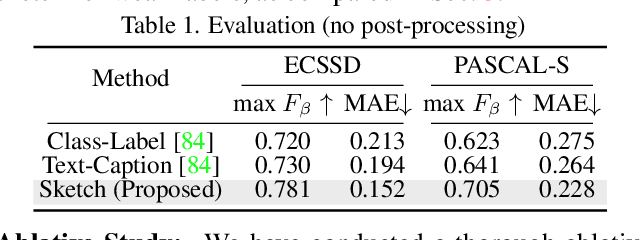

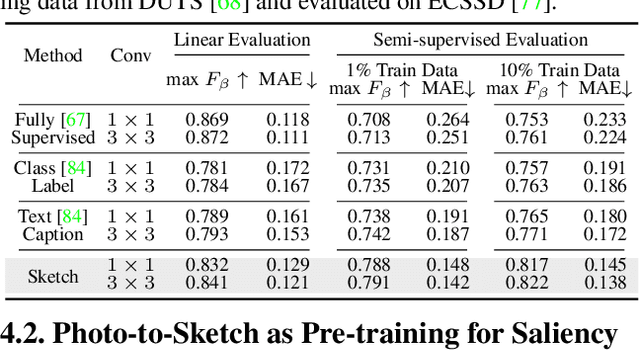
Human sketch has already proved its worth in various visual understanding tasks (e.g., retrieval, segmentation, image-captioning, etc). In this paper, we reveal a new trait of sketches - that they are also salient. This is intuitive as sketching is a natural attentive process at its core. More specifically, we aim to study how sketches can be used as a weak label to detect salient objects present in an image. To this end, we propose a novel method that emphasises on how "salient object" could be explained by hand-drawn sketches. To accomplish this, we introduce a photo-to-sketch generation model that aims to generate sequential sketch coordinates corresponding to a given visual photo through a 2D attention mechanism. Attention maps accumulated across the time steps give rise to salient regions in the process. Extensive quantitative and qualitative experiments prove our hypothesis and delineate how our sketch-based saliency detection model gives a competitive performance compared to the state-of-the-art.
TransPoser: Transformer as an Optimizer for Joint Object Shape and Pose Estimation
Mar 23, 2023
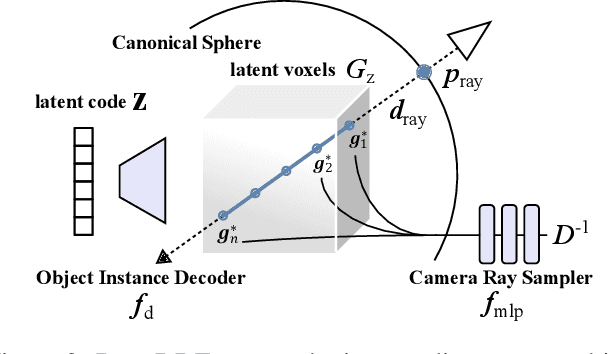
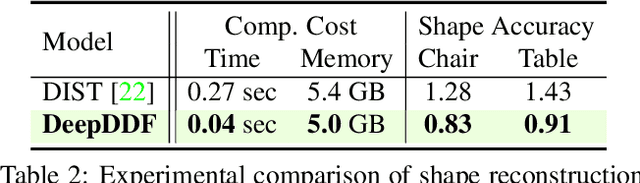
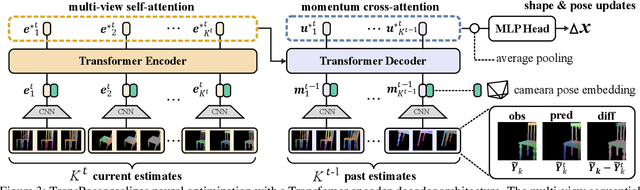
We propose a novel method for joint estimation of shape and pose of rigid objects from their sequentially observed RGB-D images. In sharp contrast to past approaches that rely on complex non-linear optimization, we propose to formulate it as a neural optimization that learns to efficiently estimate the shape and pose. We introduce Deep Directional Distance Function (DeepDDF), a neural network that directly outputs the depth image of an object given the camera viewpoint and viewing direction, for efficient error computation in 2D image space. We formulate the joint estimation itself as a Transformer which we refer to as TransPoser. We fully leverage the tokenization and multi-head attention to sequentially process the growing set of observations and to efficiently update the shape and pose with a learned momentum, respectively. Experimental results on synthetic and real data show that DeepDDF achieves high accuracy as a category-level object shape representation and TransPoser achieves state-of-the-art accuracy efficiently for joint shape and pose estimation.