 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-free Temporal Object Tracking in Surgical Videos
Mar 08, 2026Purpose: In this paper, we present a novel approach for online object tracking in laparoscopic cholecystectomy (LC) surgical videos, targeting localisation and tracking of critical anatomical structures and instruments. Our method addresses the challenges of costly pixel-level annotations and label inconsistencies inherent in existing datasets. Methods: Leveraging the inherent object localisation capabilities of pre-trained text-to-image diffusion models, we extract representative features from surgical frames without any training or fine-tuning. Our tracking framework uses these features, along with cross-frame interactions via an affinity matrix inspired by query-key-value attention, to ensure temporal continuity in the tracking process. Results: Through a pilot study, we first demonstrate that diffusion features exhibit superior object localisation and consistent semantics across different decoder levels and temporal frames. Later, we perform extensive experiments to validate the effectiveness of our approach, showcasing its superiority over competitors for the task of temporal object tracking. Specifically, we achieve a per-pixel classification accuracy of 79.19%, mean Jaccard Score of 56.20%, and mean F-Score of 79.48% on the publicly available CholeSeg8K dataset. Conclusion: Our work not only introduces a novel application of text-to-image diffusion models but also contributes to advancing the field of surgical video analysis, offering a promising avenue for accurate and cost-effective temporal object tracking in minimally invasive surgery videos.
* Accepted in IPCAI 2025
Doodle Your Keypoints: Sketch-Based Few-Shot Keypoint Detection
Jul 10, 2025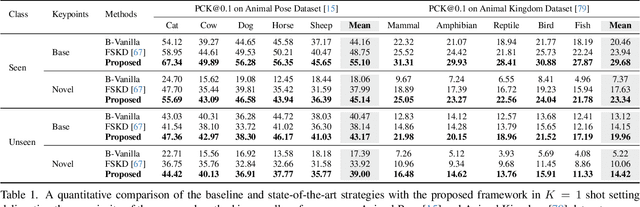


Keypoint detection, integral to modern machine perception, faces challenges in few-shot learning, particularly when source data from the same distribution as the query is unavailable. This gap is addressed by leveraging sketches, a popular form of human expression, providing a source-free alternative. However, challenges arise in mastering cross-modal embeddings and handling user-specific sketch styles. Our proposed framework overcomes these hurdles with a prototypical setup, combined with a grid-based locator and prototypical domain adaptation. We also demonstrate success in few-shot convergence across novel keypoints and classes through extensive experiments.
Sketch Down the FLOPs: Towards Efficient Networks for Human Sketch
May 29, 2025
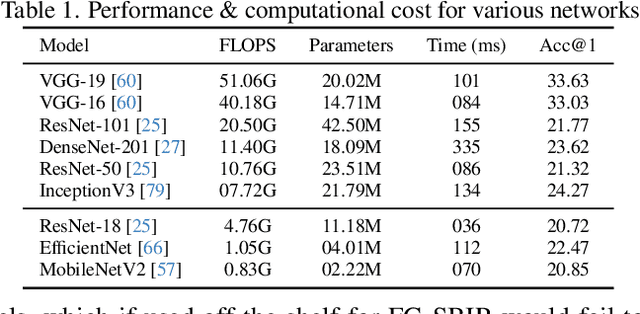
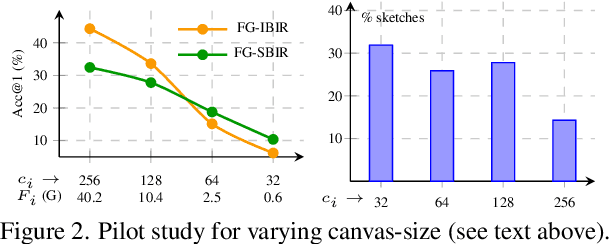

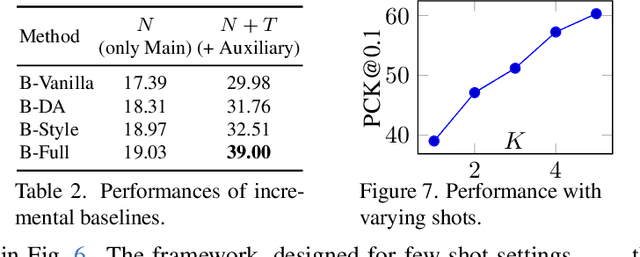
As sketch research has collectively matured over time, its adaptation for at-mass commercialisation emerges on the immediate horizon. Despite an already mature research endeavour for photos, there is no research on the efficient inference specifically designed for sketch data. In this paper, we first demonstrate existing state-of-the-art efficient light-weight models designed for photos do not work on sketches. We then propose two sketch-specific components which work in a plug-n-play manner on any photo efficient network to adapt them to work on sketch data. We specifically chose fine-grained sketch-based image retrieval (FG-SBIR) as a demonstrator as the most recognised sketch problem with immediate commercial value. Technically speaking, we first propose a cross-modal knowledge distillation network to transfer existing photo efficient networks to be compatible with sketch, which brings down number of FLOPs and model parameters by 97.96% percent and 84.89% respectively. We then exploit the abstract trait of sketch to introduce a RL-based canvas selector that dynamically adjusts to the abstraction level which further cuts down number of FLOPs by two thirds. The end result is an overall reduction of 99.37% of FLOPs (from 40.18G to 0.254G) when compared with a full network, while retaining the accuracy (33.03% vs 32.77%) -- finally making an efficient network for the sparse sketch data that exhibit even fewer FLOPs than the best photo counterpart.
SketchFusion: Learning Universal Sketch Features through Fusing Foundation Models
Mar 18, 2025While foundation models have revolutionised computer vision, their effectiveness for sketch understanding remains limited by the unique challenges of abstract, sparse visual inputs. Through systematic analysis, we uncover two fundamental limitations: Stable Diffusion (SD) struggles to extract meaningful features from abstract sketches (unlike its success with photos), and exhibits a pronounced frequency-domain bias that suppresses essential low-frequency components needed for sketch understanding. Rather than costly retraining, we address these limitations by strategically combining SD with CLIP, whose strong semantic understanding naturally compensates for SD's spatial-frequency biases. By dynamically injecting CLIP features into SD's denoising process and adaptively aggregating features across semantic levels, our method achieves state-of-the-art performance in sketch retrieval (+3.35%), recognition (+1.06%), segmentation (+29.42%), and correspondence learning (+21.22%), demonstrating the first truly universal sketch feature representation in the era of foundation models.
Freestyle Sketch-in-the-Loop Image Segmentation
Jan 27, 2025In this paper, we expand the domain of sketch research into the field of image segmentation, aiming to establish freehand sketches as a query modality for subjective image segmentation. Our innovative approach introduces a "sketch-in-the-loop" image segmentation framework, enabling the segmentation of visual concepts partially, completely, or in groupings - a truly "freestyle" approach - without the need for a purpose-made dataset (i.e., mask-free). This framework capitalises on the synergy between sketch-based image retrieval (SBIR) models and large-scale pre-trained models (CLIP or DINOv2). The former provides an effective training signal, while fine-tuned versions of the latter execute the subjective segmentation. Additionally, our purpose-made augmentation strategy enhances the versatility of our sketch-guided mask generation, allowing segmentation at multiple granularity levels. Extensive evaluations across diverse benchmark datasets underscore the superior performance of our method in comparison to existing approaches across various evaluation scenarios.
DreamColour: Controllable Video Colour Editing without Training
Dec 06, 2024



Video colour editing is a crucial task for content creation, yet existing solutions either require painstaking frame-by-frame manipulation or produce unrealistic results with temporal artefacts. We present a practical, training-free framework that makes precise video colour editing accessible through an intuitive interface while maintaining professional-quality output. Our key insight is that by decoupling spatial and temporal aspects of colour editing, we can better align with users' natural workflow -- allowing them to focus on precise colour selection in key frames before automatically propagating changes across time. We achieve this through a novel technical framework that combines: (i) a simple point-and-click interface merging grid-based colour selection with automatic instance segmentation for precise spatial control, (ii) bidirectional colour propagation that leverages inherent video motion patterns, and (iii) motion-aware blending that ensures smooth transitions even with complex object movements. Through extensive evaluation on diverse scenarios, we demonstrate that our approach matches or exceeds state-of-the-art methods while eliminating the need for training or specialized hardware, making professional-quality video colour editing accessible to everyone.
Do Generalised Classifiers really work on Human Drawn Sketches?
Jul 04, 2024


This paper, for the first time, marries large foundation models with human sketch understanding. We demonstrate what this brings -- a paradigm shift in terms of generalised sketch representation learning (e.g., classification). This generalisation happens on two fronts: (i) generalisation across unknown categories (i.e., open-set), and (ii) generalisation traversing abstraction levels (i.e., good and bad sketches), both being timely challenges that remain unsolved in the sketch literature. Our design is intuitive and centred around transferring the already stellar generalisation ability of CLIP to benefit generalised learning for sketches. We first "condition" the vanilla CLIP model by learning sketch-specific prompts using a novel auxiliary head of raster to vector sketch conversion. This importantly makes CLIP "sketch-aware". We then make CLIP acute to the inherently different sketch abstraction levels. This is achieved by learning a codebook of abstraction-specific prompt biases, a weighted combination of which facilitates the representation of sketches across abstraction levels -- low abstract edge-maps, medium abstract sketches in TU-Berlin, and highly abstract doodles in QuickDraw. Our framework surpasses popular sketch representation learning algorithms in both zero-shot and few-shot setups and in novel settings across different abstraction boundaries.
Freeview Sketching: View-Aware Fine-Grained Sketch-Based Image Retrieval
Jul 01, 2024



In this paper, we delve into the intricate dynamics of Fine-Grained Sketch-Based Image Retrieval (FG-SBIR) by addressing a critical yet overlooked aspect -- the choice of viewpoint during sketch creation. Unlike photo systems that seamlessly handle diverse views through extensive datasets, sketch systems, with limited data collected from fixed perspectives, face challenges. Our pilot study, employing a pre-trained FG-SBIR model, highlights the system's struggle when query-sketches differ in viewpoint from target instances. Interestingly, a questionnaire however shows users desire autonomy, with a significant percentage favouring view-specific retrieval. To reconcile this, we advocate for a view-aware system, seamlessly accommodating both view-agnostic and view-specific tasks. Overcoming dataset limitations, our first contribution leverages multi-view 2D projections of 3D objects, instilling cross-modal view awareness. The second contribution introduces a customisable cross-modal feature through disentanglement, allowing effortless mode switching. Extensive experiments on standard datasets validate the effectiveness of our method.
SketchDeco: Decorating B&W Sketches with Colour
May 29, 2024



This paper introduces a novel approach to sketch colourisation, inspired by the universal childhood activity of colouring and its professional applications in design and story-boarding. Striking a balance between precision and convenience, our method utilises region masks and colour palettes to allow intuitive user control, steering clear of the meticulousness of manual colour assignments or the limitations of textual prompts. By strategically combining ControlNet and staged generation, incorporating Stable Diffusion v1.5, and leveraging BLIP-2 text prompts, our methodology facilitates faithful image generation and user-directed colourisation. Addressing challenges of local and global consistency, we employ inventive solutions such as an inversion scheme, guided sampling, and a self-attention mechanism with a scaling factor. The resulting tool is not only fast and training-free but also compatible with consumer-grade Nvidia RTX 4090 Super GPUs, making it a valuable asset for both creative professionals and enthusiasts in various fields. Project Page: \url{https://chaitron.github.io/SketchDeco/}
How to Handle Sketch-Abstraction in Sketch-Based Image Retrieval?
Mar 20, 2024



In this paper, we propose a novel abstraction-aware sketch-based image retrieval framework capable of handling sketch abstraction at varied levels. Prior works had mainly focused on tackling sub-factors such as drawing style and order, we instead attempt to model abstraction as a whole, and propose feature-level and retrieval granularity-level designs so that the system builds into its DNA the necessary means to interpret abstraction. On learning abstraction-aware features, we for the first-time harness the rich semantic embedding of pre-trained StyleGAN model, together with a novel abstraction-level mapper that deciphers the level of abstraction and dynamically selects appropriate dimensions in the feature matrix correspondingly, to construct a feature matrix embedding that can be freely traversed to accommodate different levels of abstraction. For granularity-level abstraction understanding, we dictate that the retrieval model should not treat all abstraction-levels equally and introduce a differentiable surrogate Acc.@q loss to inject that understanding into the system. Different to the gold-standard triplet loss, our Acc.@q loss uniquely allows a sketch to narrow/broaden its focus in terms of how stringent the evaluation should be - the more abstract a sketch, the less stringent (higher q). Extensive experiments depict our method to outperform existing state-of-the-arts in standard SBIR tasks along with challenging scenarios like early retrieval, forensic sketch-photo matching, and style-invariant retrieval.