 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Division Gets Better: Learning Brightness-Aware and Detail-Sensitive Representations for Low-Light Image Enhancement
Jul 18, 2023




Low-light image enhancement strives to improve the contrast, adjust the visibility, and restore the distortion in color and texture. Existing methods usually pay more attention to improving the visibility and contrast via increasing the lightness of low-light images, while disregarding the significance of color and texture restoration for high-quality images. Against above issue, we propose a novel luminance and chrominance dual branch network, termed LCDBNet, for low-light image enhancement, which divides low-light image enhancement into two sub-tasks, e.g., luminance adjustment and chrominance restoration. Specifically, LCDBNet is composed of two branches, namely luminance adjustment network (LAN) and chrominance restoration network (CRN). LAN takes responsibility for learning brightness-aware features leveraging long-range dependency and local attention correlation. While CRN concentrates on learning detail-sensitive features via multi-level wavelet decomposition. Finally, a fusion network is designed to blend their learned features to produce visually impressive images. Extensive experiments conducted on seven benchmark datasets validate the effectiveness of our proposed LCDBNet, and the results manifest that LCDBNet achieves superior performance in terms of multiple reference/non-reference quality evaluators compared to other state-of-the-art competitors. Our code and pretrained model will be available.
Physics-Informed DeepMRI: Bridging the Gap from Heat Diffusion to k-Space Interpolation
Aug 30, 2023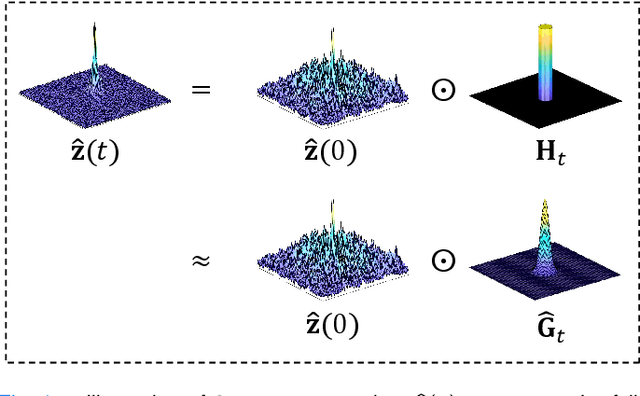
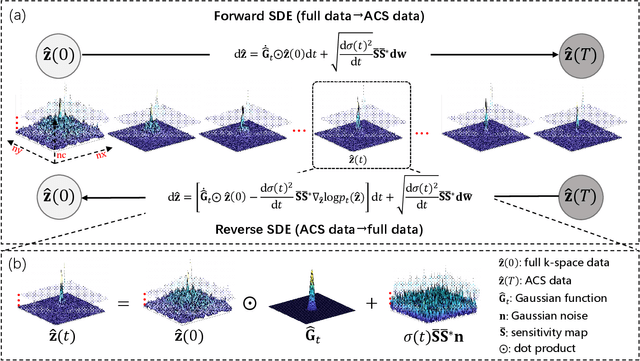

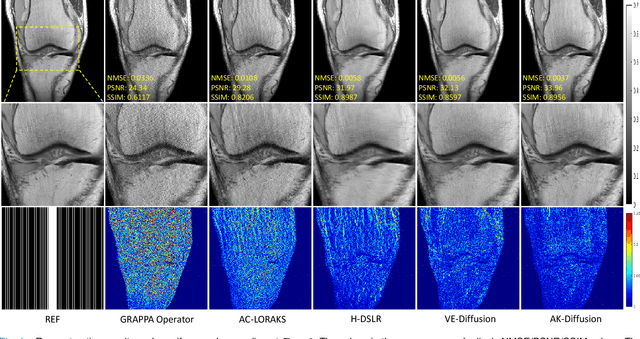
In the field of parallel imaging (PI), alongside image-domain regularization methods, substantial research has been dedicated to exploring $k$-space interpolation. However, the interpretability of these methods remains an unresolved issue. Furthermore, these approaches currently face acceleration limitations that are comparable to those experienced by image-domain methods. In order to enhance interpretability and overcome the acceleration limitations, this paper introduces an interpretable framework that unifies both $k$-space interpolation techniques and image-domain methods, grounded in the physical principles of heat diffusion equations. Building upon this foundational framework, a novel $k$-space interpolation method is proposed. Specifically, we model the process of high-frequency information attenuation in $k$-space as a heat diffusion equation, while the effort to reconstruct high-frequency information from low-frequency regions can be conceptualized as a reverse heat equation. However, solving the reverse heat equation poses a challenging inverse problem. To tackle this challenge, we modify the heat equation to align with the principles of magnetic resonance PI physics and employ the score-based generative method to precisely execute the modified reverse heat diffusion. Finally, experimental validation conducted on publicly available datasets demonstrates the superiority of the proposed approach over traditional $k$-space interpolation methods, deep learning-based $k$-space interpolation methods, and conventional diffusion models in terms of reconstruction accuracy, particularly in high-frequency regions.
NutritionVerse: Empirical Study of Various Dietary Intake Estimation Approaches
Sep 14, 2023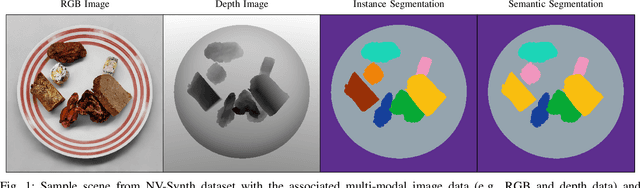



Accurate dietary intake estimation is critical for informing policies and programs to support healthy eating, as malnutrition has been directly linked to decreased quality of life. However self-reporting methods such as food diaries suffer from substantial bias. Other conventional dietary assessment techniques and emerging alternative approaches such as mobile applications incur high time costs and may necessitate trained personnel. Recent work has focused on using computer vision and machine learning to automatically estimate dietary intake from food images, but the lack of comprehensive datasets with diverse viewpoints, modalities and food annotations hinders the accuracy and realism of such methods. To address this limitation, we introduce NutritionVerse-Synth, the first large-scale dataset of 84,984 photorealistic synthetic 2D food images with associated dietary information and multimodal annotations (including depth images, instance masks, and semantic masks). Additionally, we collect a real image dataset, NutritionVerse-Real, containing 889 images of 251 dishes to evaluate realism. Leveraging these novel datasets, we develop and benchmark NutritionVerse, an empirical study of various dietary intake estimation approaches, including indirect segmentation-based and direct prediction networks. We further fine-tune models pretrained on synthetic data with real images to provide insights into the fusion of synthetic and real data. Finally, we release both datasets (NutritionVerse-Synth, NutritionVerse-Real) on https://www.kaggle.com/nutritionverse/datasets as part of an open initiative to accelerate machine learning for dietary sensing.
Virchow: A Million-Slide Digital Pathology Foundation Model
Sep 14, 2023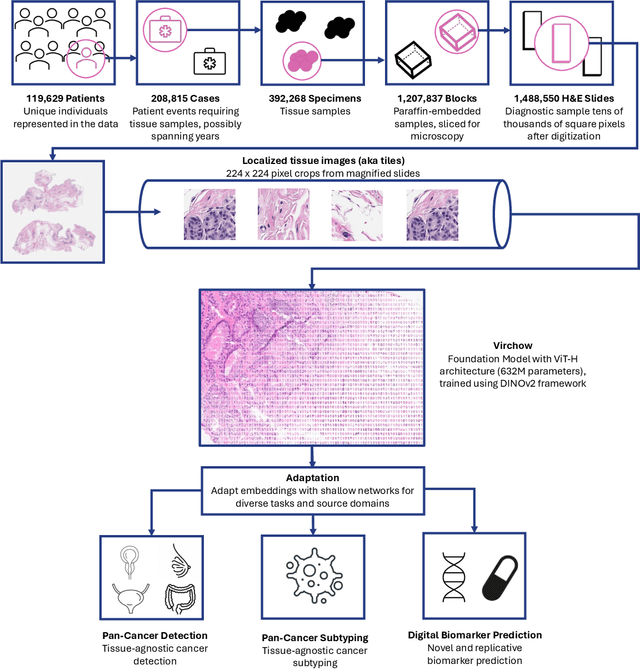
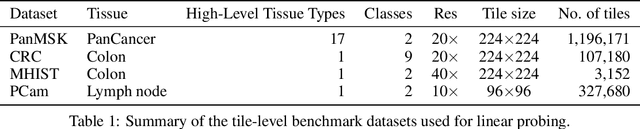
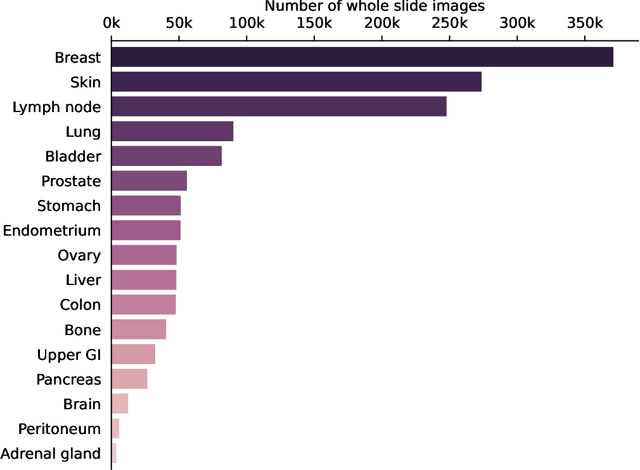
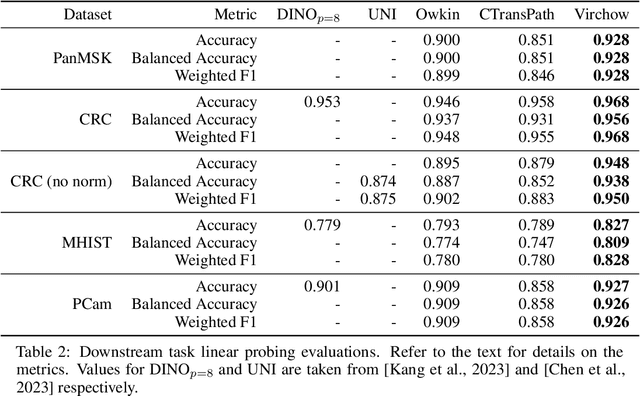
Computational pathology uses artificial intelligence to enable precision medicine and decision support systems through the analysis of whole slide images. It has the potential to revolutionize the diagnosis and treatment of cancer. However, a major challenge to this objective is that for many specific computational pathology tasks the amount of data is inadequate for development. To address this challenge, we created Virchow, a 632 million parameter deep neural network foundation model for computational pathology. Using self-supervised learning, Virchow is trained on 1.5 million hematoxylin and eosin stained whole slide images from diverse tissue groups, which is orders of magnitude more data than previous works. When evaluated on downstream tasks including tile-level pan-cancer detection and subtyping and slide-level biomarker prediction, Virchow outperforms state-of-the-art systems both on internal datasets drawn from the same population as the pretraining data as well as external public datasets. Virchow achieves 93% balanced accuracy for pancancer tile classification, and AUCs of 0.983 for colon microsatellite instability status prediction and 0.967 for breast CDH1 status prediction. The gains in performance highlight the importance of pretraining on massive pathology image datasets, suggesting pretraining on even larger datasets could continue improving performance for many high-impact applications where limited amounts of training data are available, such as drug outcome prediction.
GRID: Scene-Graph-based Instruction-driven Robotic Task Planning
Sep 14, 2023Recent works have shown that Large Language Models (LLMs) can promote grounding instructions to robotic task planning. Despite the progress, most existing works focused on utilizing raw images to help LLMs understand environmental information, which not only limits the observation scope but also typically requires massive multimodal data collection and large-scale models. In this paper, we propose a novel approach called Graph-based Robotic Instruction Decomposer (GRID), leverages scene graph instead of image to perceive global scene information and continuously plans subtask in each stage for a given instruction. Our method encodes object attributes and relationships in graphs through an LLM and Graph Attention Networks, integrating instruction features to predict subtasks consisting of pre-defined robot actions and target objects in the scene graph. This strategy enables robots to acquire semantic knowledge widely observed in the environment from the scene graph. To train and evaluate GRID, we build a dataset construction pipeline to generate synthetic datasets in graph-based robotic task planning. Experiments have shown that our method outperforms GPT-4 by over 25.4% in subtask accuracy and 43.6% in task accuracy. Experiments conducted on datasets of unseen scenes and scenes with different numbers of objects showed that the task accuracy of GRID declined by at most 3.8%, which demonstrates its good cross-scene generalization ability. We validate our method in both physical simulation and the real world.
Federated Learning Over Images: Vertical Decompositions and Pre-Trained Backbones Are Difficult to Beat
Sep 06, 2023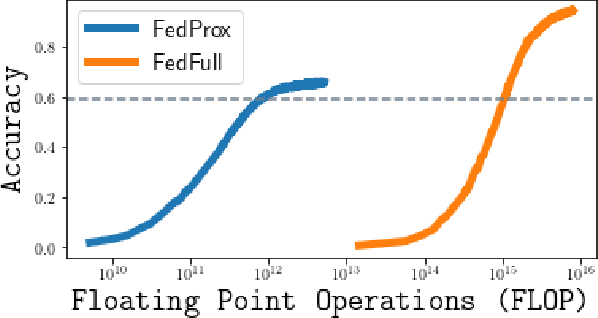
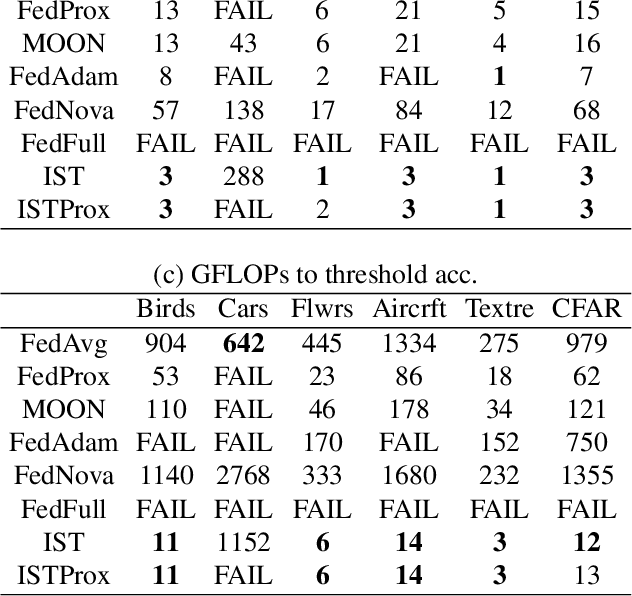
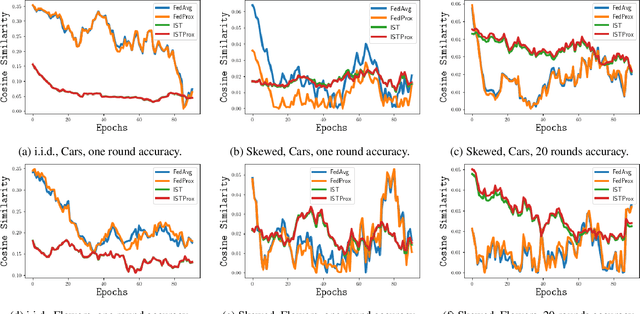
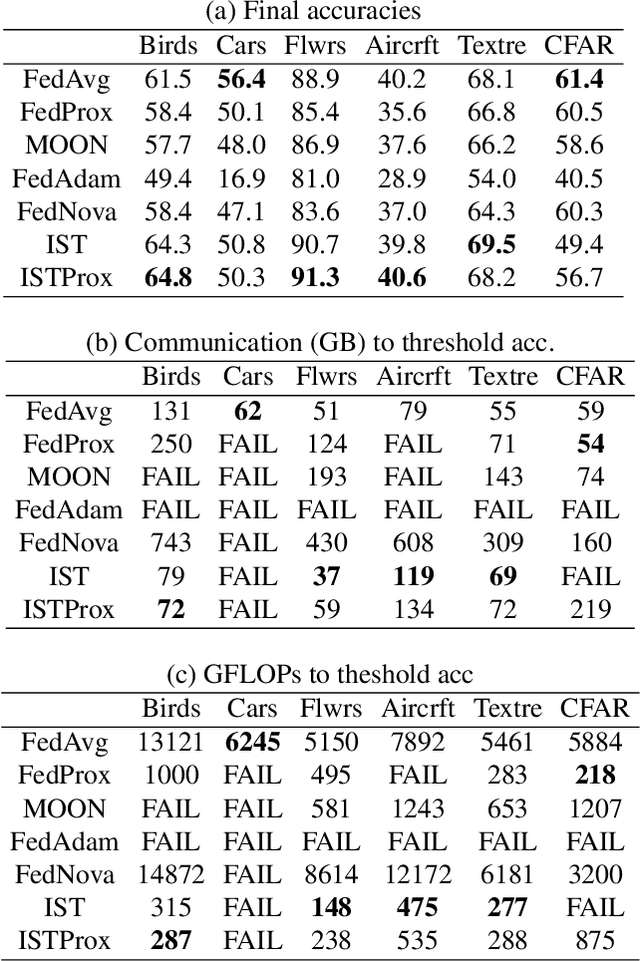
We carefully evaluate a number of algorithms for learning in a federated environment, and test their utility for a variety of image classification tasks. We consider many issues that have not been adequately considered before: whether learning over data sets that do not have diverse sets of images affects the results; whether to use a pre-trained feature extraction "backbone"; how to evaluate learner performance (we argue that classification accuracy is not enough), among others. Overall, across a wide variety of settings, we find that vertically decomposing a neural network seems to give the best results, and outperforms more standard reconciliation-used methods.
Reverse Knowledge Distillation: Training a Large Model using a Small One for Retinal Image Matching on Limited Data
Jul 21, 2023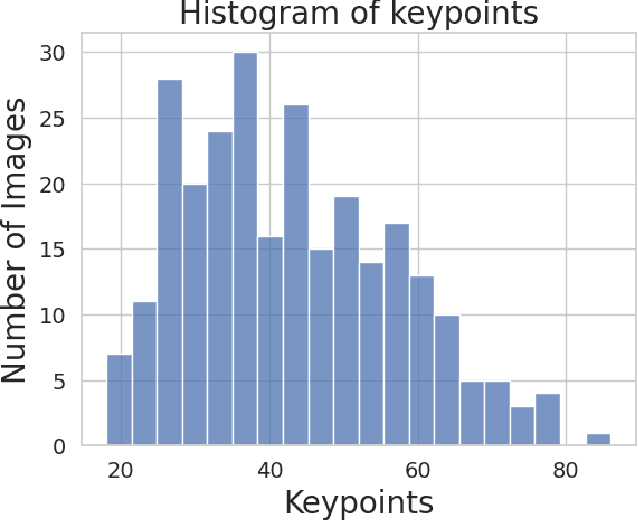
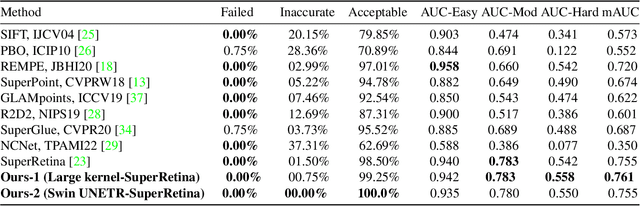
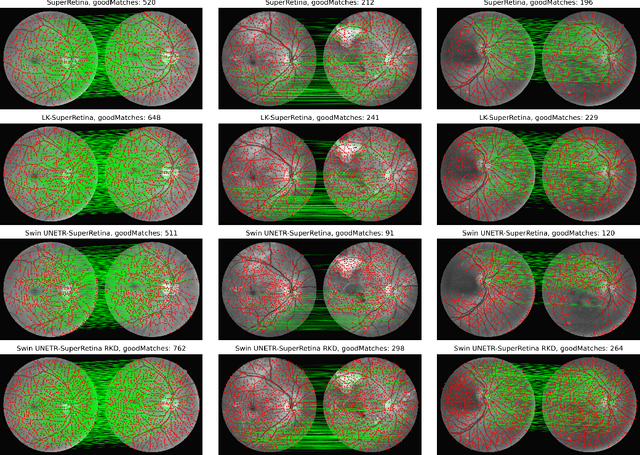
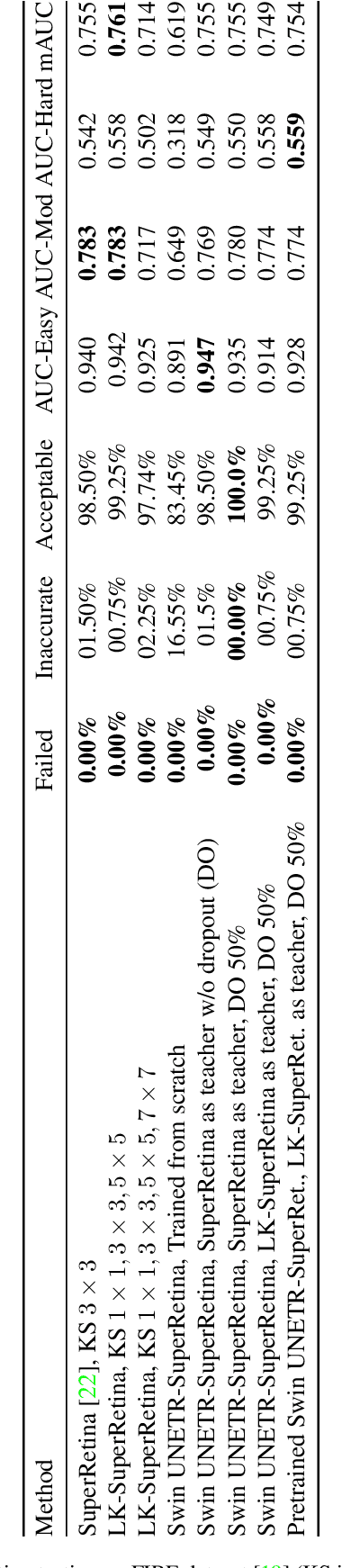
Retinal image matching plays a crucial role in monitoring disease progression and treatment response. However, datasets with matched keypoints between temporally separated pairs of images are not available in abundance to train transformer-based model. We propose a novel approach based on reverse knowledge distillation to train large models with limited data while preventing overfitting. Firstly, we propose architectural modifications to a CNN-based semi-supervised method called SuperRetina that help us improve its results on a publicly available dataset. Then, we train a computationally heavier model based on a vision transformer encoder using the lighter CNN-based model, which is counter-intuitive in the field knowledge-distillation research where training lighter models based on heavier ones is the norm. Surprisingly, such reverse knowledge distillation improves generalization even further. Our experiments suggest that high-dimensional fitting in representation space may prevent overfitting unlike training directly to match the final output. We also provide a public dataset with annotations for retinal image keypoint detection and matching to help the research community develop algorithms for retinal image applications.
LCCo: Lending CLIP to Co-Segmentation
Aug 22, 2023
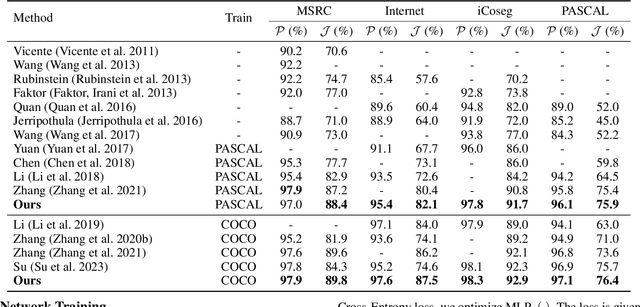
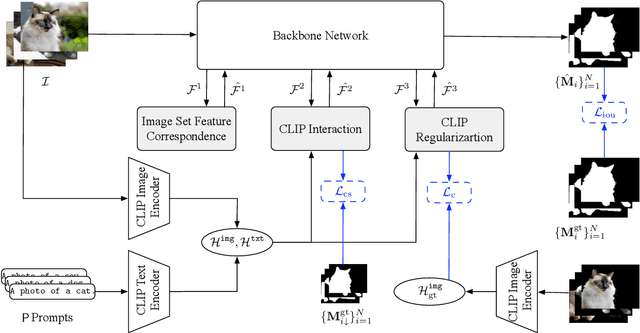
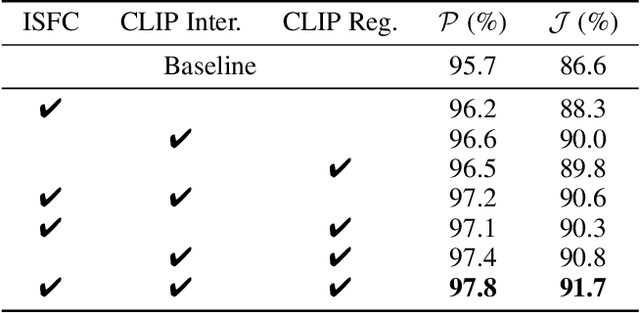
This paper studies co-segmenting the common semantic object in a set of images. Existing works either rely on carefully engineered networks to mine the implicit semantic information in visual features or require extra data (i.e., classification labels) for training. In this paper, we leverage the contrastive language-image pre-training framework (CLIP) for the task. With a backbone segmentation network that independently processes each image from the set, we introduce semantics from CLIP into the backbone features, refining them in a coarse-to-fine manner with three key modules: i) an image set feature correspondence module, encoding global consistent semantic information of the image set; ii) a CLIP interaction module, using CLIP-mined common semantics of the image set to refine the backbone feature; iii) a CLIP regularization module, drawing CLIP towards this co-segmentation task, identifying the best CLIP semantic and using it to regularize the backbone feature. Experiments on four standard co-segmentation benchmark datasets show that the performance of our method outperforms state-of-the-art methods.
Enhancing Dynamic Image Advertising with Vision-Language Pre-training
Jun 25, 2023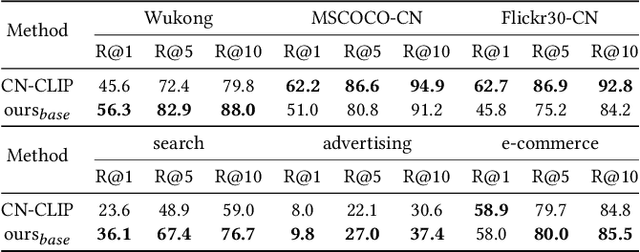



In the multimedia era, image is an effective medium in search advertising. Dynamic Image Advertising (DIA), a system that matches queries with ad images and generates multimodal ads, is introduced to improve user experience and ad revenue. The core of DIA is a query-image matching module performing ad image retrieval and relevance modeling. Current query-image matching suffers from limited and inconsistent data, and insufficient cross-modal interaction. Also, the separate optimization of retrieval and relevance models affects overall performance. To address this issue, we propose a vision-language framework consisting of two parts. First, we train a base model on large-scale image-text pairs to learn general multimodal representation. Then, we fine-tune the base model on advertising business data, unifying relevance modeling and retrieval through multi-objective learning. Our framework has been implemented in Baidu search advertising system "Phoneix Nest". Online evaluation shows that it improves cost per mille (CPM) and click-through rate (CTR) by 1.04% and 1.865%.
A ChatGPT Aided Explainable Framework for Zero-Shot Medical Image Diagnosis
Jul 05, 2023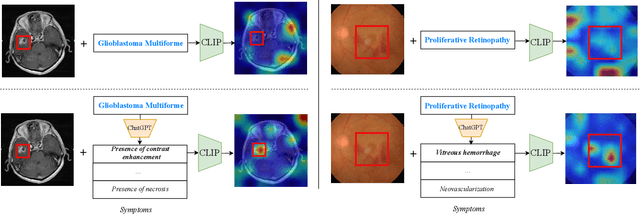
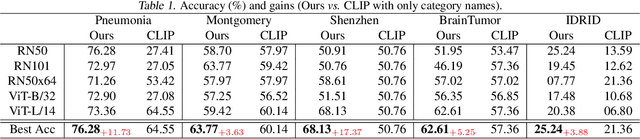
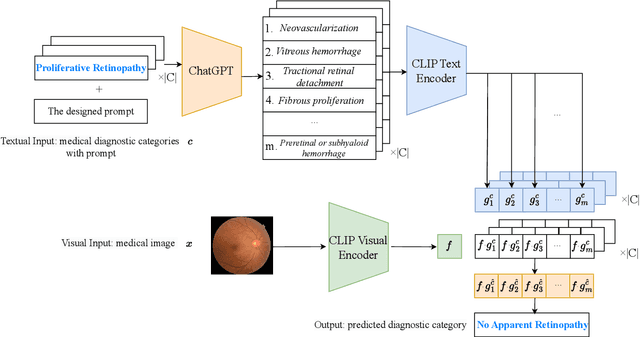
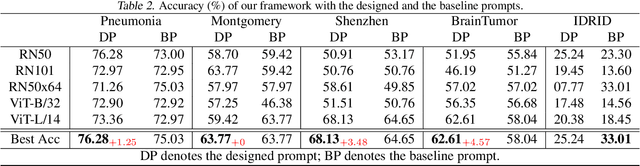
Zero-shot medical image classification is a critical process in real-world scenarios where we have limited access to all possible diseases or large-scale annotated data. It involves computing similarity scores between a query medical image and possible disease categories to determine the diagnostic result. Recent advances in pretrained vision-language models (VLMs) such as CLIP have shown great performance for zero-shot natural image recognition and exhibit benefits in medical applications. However, an explainable zero-shot medical image recognition framework with promising performance is yet under development. In this paper, we propose a novel CLIP-based zero-shot medical image classification framework supplemented with ChatGPT for explainable diagnosis, mimicking the diagnostic process performed by human experts. The key idea is to query large language models (LLMs) with category names to automatically generate additional cues and knowledge, such as disease symptoms or descriptions other than a single category name, to help provide more accurate and explainable diagnosis in CLIP. We further design specific prompts to enhance the quality of generated texts by ChatGPT that describe visual medical features. Extensive results on one private dataset and four public datasets along with detailed analysis demonstrate the effectiveness and explainability of our training-free zero-shot diagnosis pipeline, corroborating the great potential of VLMs and LLMs for medical applications.