 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRxr
Papers and Code
MapDream: Task-Driven Map Learning for Vision-Language Navigation
Feb 03, 2026Vision-Language Navigation (VLN) requires agents to follow natural language instructions in partially observed 3D environments, motivating map representations that aggregate spatial context beyond local perception. However, most existing approaches rely on hand-crafted maps constructed independently of the navigation policy. We argue that maps should instead be learned representations shaped directly by navigation objectives rather than exhaustive reconstructions. Based on this insight, we propose MapDream, a map-in-the-loop framework that formulates map construction as autoregressive bird's-eye-view (BEV) image synthesis. The framework jointly learns map generation and action prediction, distilling environmental context into a compact three-channel BEV map that preserves only navigation-critical affordances. Supervised pre-training bootstraps a reliable mapping-to-control interface, while the autoregressive design enables end-to-end joint optimization through reinforcement fine-tuning. Experiments on R2R-CE and RxR-CE achieve state-of-the-art monocular performance, validating task-driven generative map learning.
Dynamic Topology Awareness: Breaking the Granularity Rigidity in Vision-Language Navigation
Jan 29, 2026Vision-Language Navigation in Continuous Environments (VLN-CE) presents a core challenge: grounding high-level linguistic instructions into precise, safe, and long-horizon spatial actions. Explicit topological maps have proven to be a vital solution for providing robust spatial memory in such tasks. However, existing topological planning methods suffer from a "Granularity Rigidity" problem. Specifically, these methods typically rely on fixed geometric thresholds to sample nodes, which fails to adapt to varying environmental complexities. This rigidity leads to a critical mismatch: the model tends to over-sample in simple areas, causing computational redundancy, while under-sampling in high-uncertainty regions, increasing collision risks and compromising precision. To address this, we propose DGNav, a framework for Dynamic Topological Navigation, introducing a context-aware mechanism to modulate map density and connectivity on-the-fly. Our approach comprises two core innovations: (1) A Scene-Aware Adaptive Strategy that dynamically modulates graph construction thresholds based on the dispersion of predicted waypoints, enabling "densification on demand" in challenging environments; (2) A Dynamic Graph Transformer that reconstructs graph connectivity by fusing visual, linguistic, and geometric cues into dynamic edge weights, enabling the agent to filter out topological noise and enhancing instruction adherence. Extensive experiments on the R2R-CE and RxR-CE benchmarks demonstrate DGNav exhibits superior navigation performance and strong generalization capabilities. Furthermore, ablation studies confirm that our framework achieves an optimal trade-off between navigation efficiency and safe exploration. The code is available at https://github.com/shannanshouyin/DGNav.
DV-VLN: Dual Verification for Reliable LLM-Based Vision-and-Language Navigation
Jan 26, 2026Vision-and-Language Navigation (VLN) requires an embodied agent to navigate in a complex 3D environment according to natural language instructions. Recent progress in large language models (LLMs) has enabled language-driven navigation with improved interpretability. However, most LLM-based agents still rely on single-shot action decisions, where the model must choose one option from noisy, textualized multi-perspective observations. Due to local mismatches and imperfect intermediate reasoning, such decisions can easily deviate from the correct path, leading to error accumulation and reduced reliability in unseen environments. In this paper, we propose DV-VLN, a new VLN framework that follows a generate-then-verify paradigm. DV-VLN first performs parameter-efficient in-domain adaptation of an open-source LLaMA-2 backbone to produce a structured navigational chain-of-thought, and then verifies candidate actions with two complementary channels: True-False Verification (TFV) and Masked-Entity Verification (MEV). DV-VLN selects actions by aggregating verification successes across multiple samples, yielding interpretable scores for reranking. Experiments on R2R, RxR (English subset), and REVERIE show that DV-VLN consistently improves over direct prediction and sampling-only baselines, achieving competitive performance among language-only VLN agents and promising results compared with several cross-modal systems.Code is available at https://github.com/PlumJun/DV-VLN.
ETP-R1: Evolving Topological Planning with Reinforcement Fine-tuning for Vision-Language Navigation in Continuous Environments
Dec 24, 2025Vision-Language Navigation in Continuous Environments (VLN-CE) requires an embodied agent to navigate towards target in continuous environments, following natural language instructions. While current graph-based methods offer an efficient, structured approach by abstracting the environment into a topological map and simplifying the action space to waypoint selection, they lag behind methods based on Large Vision-Language Models (LVLMs) in leveraging large-scale data and advanced training paradigms. In this paper, we try to bridge this gap by introducing ETP-R1, a framework that applies the paradigm of scaling up data and Reinforcement Fine-Tuning (RFT) to a graph-based VLN-CE model. To build a strong foundation, we first construct a high-quality, large-scale pretraining dataset using the Gemini API. This dataset consists of diverse, low-hallucination instructions for topological trajectories, providing rich supervision for our graph-based policy to map language to topological paths. This foundation is further strengthened by unifying data from both R2R and RxR tasks for joint pretraining. Building on this, we introduce a three-stage training paradigm, which culminates in the first application of closed-loop, online RFT to a graph-based VLN-CE model, powered by the Group Relative Policy Optimization (GRPO) algorithm. Extensive experiments demonstrate that our approach is highly effective, establishing new state-of-the-art performance across all major metrics on both the R2R-CE and RxR-CE benchmarks. Our code is available at https://github.com/Cepillar/ETP-R1.
Efficient-VLN: A Training-Efficient Vision-Language Navigation Model
Dec 11, 2025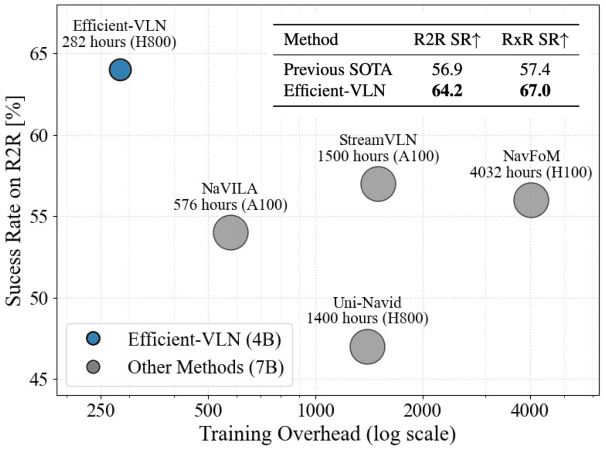
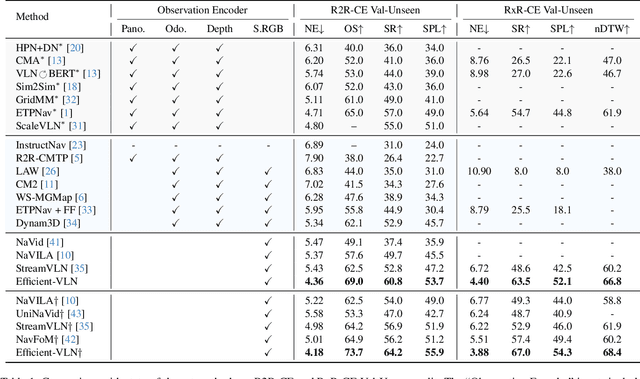
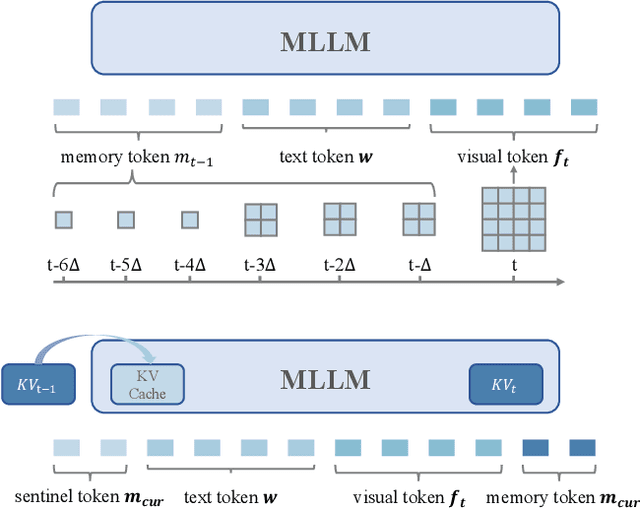
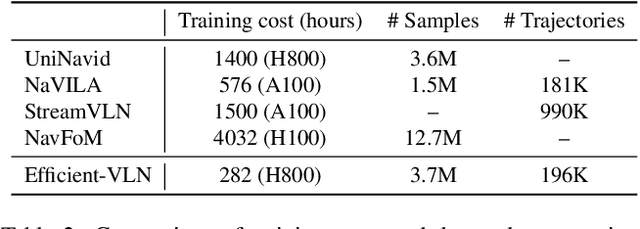
Multimodal large language models (MLLMs) have shown promising potential in Vision-Language Navigation (VLN). However, their practical development is severely hindered by the substantial training overhead. We recognize two key issues that contribute to the overhead: (1) the quadratic computational burden from processing long-horizon historical observations as massive sequences of tokens, and (2) the exploration-efficiency trade-off in DAgger, i.e., a data aggregation process of collecting agent-explored trajectories. While more exploration yields effective error-recovery trajectories for handling test-time distribution shifts, it comes at the cost of longer trajectory lengths for both training and inference. To address these challenges, we propose Efficient-VLN, a training-efficient VLN model. Specifically, to mitigate the token processing burden, we design two efficient memory mechanisms: a progressive memory that dynamically allocates more tokens to recent observations, and a learnable recursive memory that utilizes the key-value cache of learnable tokens as the memory state. Moreover, we introduce a dynamic mixed policy to balance the exploration-efficiency trade-off. Extensive experiments show that Efficient-VLN achieves state-of-the-art performance on R2R-CE (64.2% SR) and RxR-CE (67.0% SR). Critically, our model consumes merely 282 H800 GPU hours, demonstrating a dramatic reduction in training overhead compared to state-of-the-art methods.
CorrectNav: Self-Correction Flywheel Empowers Vision-Language-Action Navigation Model
Aug 14, 2025Existing vision-and-language navigation models often deviate from the correct trajectory when executing instructions. However, these models lack effective error correction capability, hindering their recovery from errors. To address this challenge, we propose Self-correction Flywheel, a novel post-training paradigm. Instead of considering the model's error trajectories on the training set as a drawback, our paradigm emphasizes their significance as a valuable data source. We have developed a method to identify deviations in these error trajectories and devised innovative techniques to automatically generate self-correction data for perception and action. These self-correction data serve as fuel to power the model's continued training. The brilliance of our paradigm is revealed when we re-evaluate the model on the training set, uncovering new error trajectories. At this time, the self-correction flywheel begins to spin. Through multiple flywheel iterations, we progressively enhance our monocular RGB-based VLA navigation model CorrectNav. Experiments on R2R-CE and RxR-CE benchmarks show CorrectNav achieves new state-of-the-art success rates of 65.1% and 69.3%, surpassing prior best VLA navigation models by 8.2% and 16.4%. Real robot tests in various indoor and outdoor environments demonstrate \method's superior capability of error correction, dynamic obstacle avoidance, and long instruction following.
Observation-Graph Interaction and Key-Detail Guidance for Vision and Language Navigation
Mar 14, 2025Vision and Language Navigation (VLN) requires an agent to navigate through environments following natural language instructions. However, existing methods often struggle with effectively integrating visual observations and instruction details during navigation, leading to suboptimal path planning and limited success rates. In this paper, we propose OIKG (Observation-graph Interaction and Key-detail Guidance), a novel framework that addresses these limitations through two key components: (1) an observation-graph interaction module that decouples angular and visual information while strengthening edge representations in the navigation space, and (2) a key-detail guidance module that dynamically extracts and utilizes fine-grained location and object information from instructions. By enabling more precise cross-modal alignment and dynamic instruction interpretation, our approach significantly improves the agent's ability to follow complex navigation instructions. Extensive experiments on the R2R and RxR datasets demonstrate that OIKG achieves state-of-the-art performance across multiple evaluation metrics, validating the effectiveness of our method in enhancing navigation precision through better observation-instruction alignment.
NAVCON: A Cognitively Inspired and Linguistically Grounded Corpus for Vision and Language Navigation
Dec 17, 2024We present NAVCON, a large-scale annotated Vision-Language Navigation (VLN) corpus built on top of two popular datasets (R2R and RxR). The paper introduces four core, cognitively motivated and linguistically grounded, navigation concepts and an algorithm for generating large-scale silver annotations of naturally occurring linguistic realizations of these concepts in navigation instructions. We pair the annotated instructions with video clips of an agent acting on these instructions. NAVCON contains 236, 316 concept annotations for approximately 30, 0000 instructions and 2.7 million aligned images (from approximately 19, 000 instructions) showing what the agent sees when executing an instruction. To our knowledge, this is the first comprehensive resource of navigation concepts. We evaluated the quality of the silver annotations by conducting human evaluation studies on NAVCON samples. As further validation of the quality and usefulness of the resource, we trained a model for detecting navigation concepts and their linguistic realizations in unseen instructions. Additionally, we show that few-shot learning with GPT-4o performs well on this task using large-scale silver annotations of NAVCON.
Constraint-Aware Zero-Shot Vision-Language Navigation in Continuous Environments
Dec 13, 2024We address the task of Vision-Language Navigation in Continuous Environments (VLN-CE) under the zero-shot setting. Zero-shot VLN-CE is particularly challenging due to the absence of expert demonstrations for training and minimal environment structural prior to guide navigation. To confront these challenges, we propose a Constraint-Aware Navigator (CA-Nav), which reframes zero-shot VLN-CE as a sequential, constraint-aware sub-instruction completion process. CA-Nav continuously translates sub-instructions into navigation plans using two core modules: the Constraint-Aware Sub-instruction Manager (CSM) and the Constraint-Aware Value Mapper (CVM). CSM defines the completion criteria for decomposed sub-instructions as constraints and tracks navigation progress by switching sub-instructions in a constraint-aware manner. CVM, guided by CSM's constraints, generates a value map on the fly and refines it using superpixel clustering to improve navigation stability. CA-Nav achieves the state-of-the-art performance on two VLN-CE benchmarks, surpassing the previous best method by 12 percent and 13 percent in Success Rate on the validation unseen splits of R2R-CE and RxR-CE, respectively. Moreover, CA-Nav demonstrates its effectiveness in real-world robot deployments across various indoor scenes and instructions.
InstruGen: Automatic Instruction Generation for Vision-and-Language Navigation Via Large Multimodal Models
Nov 18, 2024



Recent research on Vision-and-Language Navigation (VLN) indicates that agents suffer from poor generalization in unseen environments due to the lack of realistic training environments and high-quality path-instruction pairs. Most existing methods for constructing realistic navigation scenes have high costs, and the extension of instructions mainly relies on predefined templates or rules, lacking adaptability. To alleviate the issue, we propose InstruGen, a VLN path-instruction pairs generation paradigm. Specifically, we use YouTube house tour videos as realistic navigation scenes and leverage the powerful visual understanding and generation abilities of large multimodal models (LMMs) to automatically generate diverse and high-quality VLN path-instruction pairs. Our method generates navigation instructions with different granularities and achieves fine-grained alignment between instructions and visual observations, which was difficult to achieve with previous methods. Additionally, we design a multi-stage verification mechanism to reduce hallucinations and inconsistency of LMMs. Experimental results demonstrate that agents trained with path-instruction pairs generated by InstruGen achieves state-of-the-art performance on the R2R and RxR benchmarks, particularly in unseen environments. Code is available at https://github.com/yanyu0526/InstruGen.