 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient-VLN: A Training-Efficient Vision-Language Navigation Model
Dec 11, 2025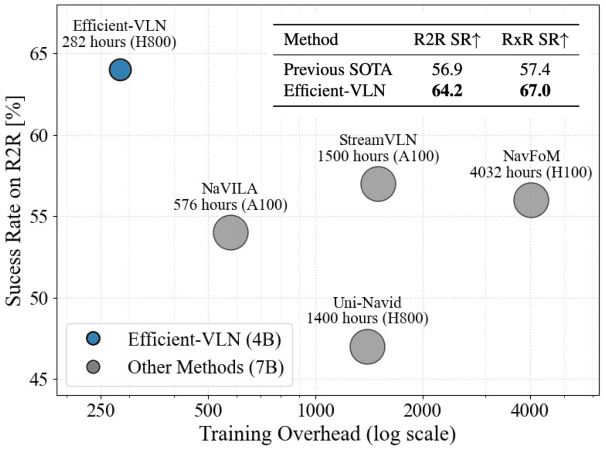
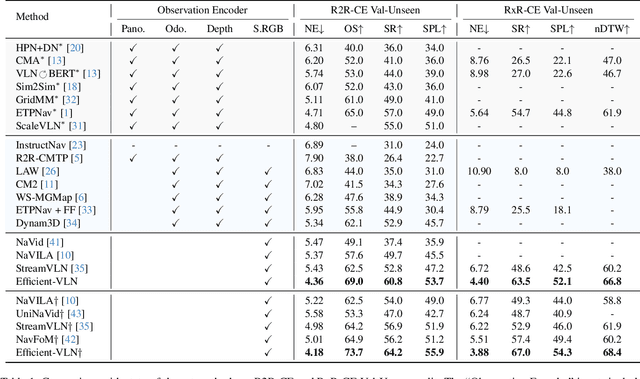
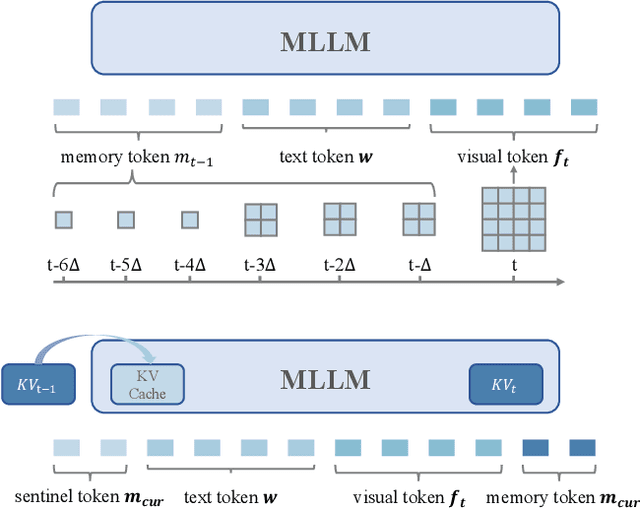
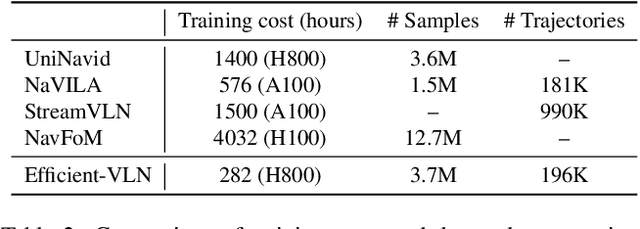
Multimodal large language models (MLLMs) have shown promising potential in Vision-Language Navigation (VLN). However, their practical development is severely hindered by the substantial training overhead. We recognize two key issues that contribute to the overhead: (1) the quadratic computational burden from processing long-horizon historical observations as massive sequences of tokens, and (2) the exploration-efficiency trade-off in DAgger, i.e., a data aggregation process of collecting agent-explored trajectories. While more exploration yields effective error-recovery trajectories for handling test-time distribution shifts, it comes at the cost of longer trajectory lengths for both training and inference. To address these challenges, we propose Efficient-VLN, a training-efficient VLN model. Specifically, to mitigate the token processing burden, we design two efficient memory mechanisms: a progressive memory that dynamically allocates more tokens to recent observations, and a learnable recursive memory that utilizes the key-value cache of learnable tokens as the memory state. Moreover, we introduce a dynamic mixed policy to balance the exploration-efficiency trade-off. Extensive experiments show that Efficient-VLN achieves state-of-the-art performance on R2R-CE (64.2% SR) and RxR-CE (67.0% SR). Critically, our model consumes merely 282 H800 GPU hours, demonstrating a dramatic reduction in training overhead compared to state-of-the-art methods.
Learning from Videos for 3D World: Enhancing MLLMs with 3D Vision Geometry Priors
May 30, 2025Previous research has investigated the application of Multimodal Large Language Models (MLLMs) in understanding 3D scenes by interpreting them as videos. These approaches generally depend on comprehensive 3D data inputs, such as point clouds or reconstructed Bird's-Eye View (BEV) maps. In our research, we advance this field by enhancing the capability of MLLMs to understand and reason in 3D spaces directly from video data, without the need for additional 3D input. We propose a novel and efficient method, the Video-3D Geometry Large Language Model (VG LLM). Our approach employs a 3D visual geometry encoder that extracts 3D prior information from video sequences. This information is integrated with visual tokens and fed into the MLLM. Extensive experiments have shown that our method has achieved substantial improvements in various tasks related to 3D scene understanding and spatial reasoning, all directly learned from video sources. Impressively, our 4B model, which does not rely on explicit 3D data inputs, achieves competitive results compared to existing state-of-the-art methods, and even surpasses the Gemini-1.5-Pro in the VSI-Bench evaluations.
C$^2$LEVA: Toward Comprehensive and Contamination-Free Language Model Evaluation
Dec 06, 2024



Recent advances in large language models (LLMs) have shown significant promise, yet their evaluation raises concerns, particularly regarding data contamination due to the lack of access to proprietary training data. To address this issue, we present C$^2$LEVA, a comprehensive bilingual benchmark featuring systematic contamination prevention. C$^2$LEVA firstly offers a holistic evaluation encompassing 22 tasks, each targeting a specific application or ability of LLMs, and secondly a trustworthy assessment due to our contamination-free tasks, ensured by a systematic contamination prevention strategy that fully automates test data renewal and enforces data protection during benchmark data release. Our large-scale evaluation of 15 open-source and proprietary models demonstrates the effectiveness of C$^2$LEVA.
Video-3D LLM: Learning Position-Aware Video Representation for 3D Scene Understanding
Nov 30, 2024



The rapid advancement of Multimodal Large Language Models (MLLMs) has significantly impacted various multimodal tasks. However, these models face challenges in tasks that require spatial understanding within 3D environments. Efforts to enhance MLLMs, such as incorporating point cloud features, have been made, yet a considerable gap remains between the models' learned representations and the inherent complexity of 3D scenes. This discrepancy largely stems from the training of MLLMs on predominantly 2D data, which restricts their effectiveness in comprehending 3D spaces. To address this issue, in this paper, we propose a novel generalist model, i.e., Video-3D LLM, for 3D scene understanding. By treating 3D scenes as dynamic videos and incorporating 3D position encoding into these representations, our Video-3D LLM aligns video representations with real-world spatial contexts more accurately. Additionally, we have implemented a maximum coverage sampling technique to optimize the balance between computational costs and performance efficiency. Extensive experiments demonstrate that our model achieves state-of-the-art performance on several 3D scene understanding benchmarks, including ScanRefer, Multi3DRefer, Scan2Cap, ScanQA, and SQA3D.
Towards Learning a Generalist Model for Embodied Navigation
Dec 06, 2023



Building a generalist agent that can interact with the world is the intriguing target of AI systems, thus spurring the research for embodied navigation, where an agent is required to navigate according to instructions or respond to queries. Despite the major progress attained, previous works primarily focus on task-specific agents and lack generalizability to unseen scenarios. Recently, LLMs have presented remarkable capabilities across various fields, and provided a promising opportunity for embodied navigation. Drawing on this, we propose the first generalist model for embodied navigation, NaviLLM. It adapts LLMs to embodied navigation by introducing schema-based instruction. The schema-based instruction flexibly casts various tasks into generation problems, thereby unifying a wide range of tasks. This approach allows us to integrate diverse data sources from various datasets into the training, equipping NaviLLM with a wide range of capabilities required by embodied navigation. We conduct extensive experiments to evaluate the performance and generalizability of our model. The experimental results demonstrate that our unified model achieves state-of-the-art performance on CVDN, SOON, and ScanQA. Specifically, it surpasses the previous stats-of-the-art method by a significant margin of 29% in goal progress on CVDN. Moreover, our model also demonstrates strong generalizability and presents impressive results on unseen tasks, e.g., embodied question answering and 3D captioning.
CLEVA: Chinese Language Models EVAluation Platform
Aug 09, 2023



With the continuous emergence of Chinese Large Language Models (LLMs), how to evaluate a model's capabilities has become an increasingly significant issue. The absence of a comprehensive Chinese benchmark that thoroughly assesses a model's performance, the unstandardized and incomparable prompting procedure, and the prevalent risk of contamination pose major challenges in the current evaluation of Chinese LLMs. We present CLEVA, a user-friendly platform crafted to holistically evaluate Chinese LLMs. Our platform employs a standardized workflow to assess LLMs' performance across various dimensions, regularly updating a competitive leaderboard. To alleviate contamination, CLEVA curates a significant proportion of new data and develops a sampling strategy that guarantees a unique subset for each leaderboard round. Empowered by an easy-to-use interface that requires just a few mouse clicks and a model API, users can conduct a thorough evaluation with minimal coding. Large-scale experiments featuring 23 influential Chinese LLMs have validated CLEVA's efficacy.
Towards Unifying Multi-Lingual and Cross-Lingual Summarization
May 16, 2023



To adapt text summarization to the multilingual world, previous work proposes multi-lingual summarization (MLS) and cross-lingual summarization (CLS). However, these two tasks have been studied separately due to the different definitions, which limits the compatible and systematic research on both of them. In this paper, we aim to unify MLS and CLS into a more general setting, i.e., many-to-many summarization (M2MS), where a single model could process documents in any language and generate their summaries also in any language. As the first step towards M2MS, we conduct preliminary studies to show that M2MS can better transfer task knowledge across different languages than MLS and CLS. Furthermore, we propose Pisces, a pre-trained M2MS model that learns language modeling, cross-lingual ability and summarization ability via three-stage pre-training. Experimental results indicate that our Pisces significantly outperforms the state-of-the-art baselines, especially in the zero-shot directions, where there is no training data from the source-language documents to the target-language summaries.
Towards Unifying Reference Expression Generation and Comprehension
Oct 24, 2022



Reference Expression Generation (REG) and Comprehension (REC) are two highly correlated tasks. Modeling REG and REC simultaneously for utilizing the relation between them is a promising way to improve both. However, the problem of distinct inputs, as well as building connections between them in a single model, brings challenges to the design and training of the joint model. To address the problems, we propose a unified model for REG and REC, named UniRef. It unifies these two tasks with the carefully-designed Image-Region-Text Fusion layer (IRTF), which fuses the image, region and text via the image cross-attention and region cross-attention. Additionally, IRTF could generate pseudo input regions for the REC task to enable a uniform way for sharing the identical representation space across the REC and REG. We further propose Vision-conditioned Masked Language Modeling (VMLM) and Text-Conditioned Region Prediction (TRP) to pre-train UniRef model on multi-granular corpora. The VMLM and TRP are directly related to REG and REC, respectively, but could help each other. We conduct extensive experiments on three benchmark datasets, RefCOCO, RefCOCO+ and RefCOCOg. Experimental results show that our model outperforms previous state-of-the-art methods on both REG and REC.
A Survey on Cross-Lingual Summarization
Mar 23, 2022
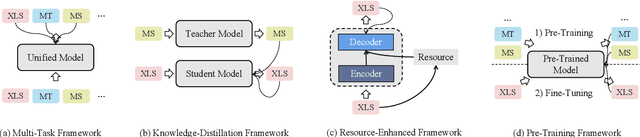

Cross-lingual summarization is the task of generating a summary in one language (e.g., English) for the given document(s) in a different language (e.g., Chinese). Under the globalization background, this task has attracted increasing attention of the computational linguistics community. Nevertheless, there still remains a lack of comprehensive review for this task. Therefore, we present the first systematic critical review on the datasets, approaches and challenges in this field. Specifically, we carefully organize existing datasets and approaches according to different construction methods and solution paradigms, respectively. For each type of datasets or approaches, we thoroughly introduce and summarize previous efforts and further compare them with each other to provide deeper analyses. In the end, we also discuss promising directions and offer our thoughts to facilitate future research. This survey is for both beginners and experts in cross-lingual summarization, and we hope it will serve as a starting point as well as a source of new ideas for researchers and engineers interested in this area.
Spot the Difference: A Cooperative Object-Referring Game in Non-Perfectly Co-Observable Scene
Mar 16, 2022
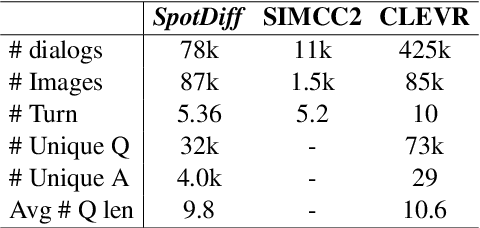
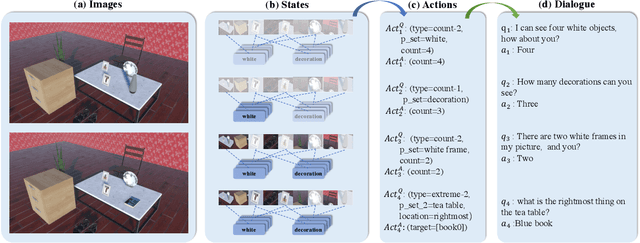
Visual dialog has witnessed great progress after introducing various vision-oriented goals into the conversation, especially such as GuessWhich and GuessWhat, where the only image is visible by either and both of the questioner and the answerer, respectively. Researchers explore more on visual dialog tasks in such kind of single- or perfectly co-observable visual scene, while somewhat neglect the exploration on tasks of non perfectly co-observable visual scene, where the images accessed by two agents may not be exactly the same, often occurred in practice. Although building common ground in non-perfectly co-observable visual scene through conversation is significant for advanced dialog agents, the lack of such dialog task and corresponding large-scale dataset makes it impossible to carry out in-depth research. To break this limitation, we propose an object-referring game in non-perfectly co-observable visual scene, where the goal is to spot the difference between the similar visual scenes through conversing in natural language. The task addresses challenges of the dialog strategy in non-perfectly co-observable visual scene and the ability of categorizing objects. Correspondingly, we construct a large-scale multimodal dataset, named SpotDiff, which contains 87k Virtual Reality images and 97k dialogs generated by self-play. Finally, we give benchmark models for this task, and conduct extensive experiments to evaluate its performance as well as analyze its main challenges.