 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAIHRI: Task-Aware 3D Human Keypoints Localization for Close-Range Human-Robot Interaction
Apr 10, 2026Accurate 3D human keypoints localization is a critical technology enabling robots to achieve natural and safe physical interaction with users. Conventional 3D human keypoints estimation methods primarily focus on the whole-body reconstruction quality relative to the root joint. However, in practical human-robot interaction (HRI) scenarios, robots are more concerned with the precise metric-scale spatial localization of task-relevant body parts under the egocentric camera 3D coordinate. We propose TAIHRI, the first Vision-Language Model (VLM) tailored for close-range HRI perception, capable of understanding users' motion commands and directing the robot's attention to the most task-relevant keypoints. By quantizing 3D keypoints into a finite interaction space, TAIHRI precisely localize the 3D spatial coordinates of critical body parts by 2D keypoint reasoning via next token prediction, and seamlessly adapt to downstream tasks such as natural language control or global space human mesh recovery. Experiments on egocentric interaction benchmarks demonstrate that TAIHRI achieves superior estimation accuracy for task-critical body parts. We believe TAIHRI opens new research avenues in the field of embodied human-robot interaction. Code is available at: https://github.com/Tencent/TAIHRI.
UniPR: Unified Object-level Real-to-Sim Perception and Reconstruction from a Single Stereo Pair
Mar 20, 2026Perceiving and reconstructing objects from images are critical for real-to-sim transfer tasks, which are widely used in the robotics community. Existing methods rely on multiple submodules such as detection, segmentation, shape reconstruction, and pose estimation to complete the pipeline. However, such modular pipelines suffer from inefficiency and cumulative error, as each stage operates on only partial or locally refined information while discarding global context. To address these limitations, we propose UniPR, the first end-to-end object-level real-to-sim perception and reconstruction framework. Operating directly on a single stereo image pair, UniPR leverages geometric constraints to resolve the scale ambiguity. We introduce Pose-Aware Shape Representation to eliminate the need for per-category canonical definitions and to bridge the gap between reconstruction and pose estimation tasks. Furthermore, we construct a large-vocabulary stereo dataset, LVS6D, comprising over 6,300 objects, to facilitate large-scale research in this area. Extensive experiments demonstrate that UniPR reconstructs all objects in a scene in parallel within a single forward pass, achieving significant efficiency gains and preserves true physical proportions across diverse object types, highlighting its potential for practical robotic applications.
Universal Pose Pretraining for Generalizable Vision-Language-Action Policies
Feb 23, 2026Existing Vision-Language-Action (VLA) models often suffer from feature collapse and low training efficiency because they entangle high-level perception with sparse, embodiment-specific action supervision. Since these models typically rely on VLM backbones optimized for Visual Question Answering (VQA), they excel at semantic identification but often overlook subtle 3D state variations that dictate distinct action patterns. To resolve these misalignments, we propose Pose-VLA, a decoupled paradigm that separates VLA training into a pre-training phase for extracting universal 3D spatial priors in a unified camera-centric space, and a post-training phase for efficient embodiment alignment within robot-specific action space. By introducing discrete pose tokens as a universal representation, Pose-VLA seamlessly integrates spatial grounding from diverse 3D datasets with geometry-level trajectories from robotic demonstrations. Our framework follows a two-stage pre-training pipeline, establishing fundamental spatial grounding via poses followed by motion alignment through trajectory supervision. Extensive evaluations demonstrate that Pose-VLA achieves state-of-the-art results on RoboTwin 2.0 with a 79.5% average success rate and competitive performance on LIBERO at 96.0%. Real-world experiments further showcase robust generalization across diverse objects using only 100 demonstrations per task, validating the efficiency of our pre-training paradigm.
VinT-6D: A Large-Scale Object-in-hand Dataset from Vision, Touch and Proprioception
Jan 06, 2025



This paper addresses the scarcity of large-scale datasets for accurate object-in-hand pose estimation, which is crucial for robotic in-hand manipulation within the ``Perception-Planning-Control" paradigm. Specifically, we introduce VinT-6D, the first extensive multi-modal dataset integrating vision, touch, and proprioception, to enhance robotic manipulation. VinT-6D comprises 2 million VinT-Sim and 0.1 million VinT-Real splits, collected via simulations in MuJoCo and Blender and a custom-designed real-world platform. This dataset is tailored for robotic hands, offering models with whole-hand tactile perception and high-quality, well-aligned data. To the best of our knowledge, the VinT-Real is the largest considering the collection difficulties in the real-world environment so that it can bridge the gap of simulation to real compared to the previous works. Built upon VinT-6D, we present a benchmark method that shows significant improvements in performance by fusing multi-modal information. The project is available at https://VinT-6D.github.io/.
Constraint-Aware Zero-Shot Vision-Language Navigation in Continuous Environments
Dec 13, 2024We address the task of Vision-Language Navigation in Continuous Environments (VLN-CE) under the zero-shot setting. Zero-shot VLN-CE is particularly challenging due to the absence of expert demonstrations for training and minimal environment structural prior to guide navigation. To confront these challenges, we propose a Constraint-Aware Navigator (CA-Nav), which reframes zero-shot VLN-CE as a sequential, constraint-aware sub-instruction completion process. CA-Nav continuously translates sub-instructions into navigation plans using two core modules: the Constraint-Aware Sub-instruction Manager (CSM) and the Constraint-Aware Value Mapper (CVM). CSM defines the completion criteria for decomposed sub-instructions as constraints and tracks navigation progress by switching sub-instructions in a constraint-aware manner. CVM, guided by CSM's constraints, generates a value map on the fly and refines it using superpixel clustering to improve navigation stability. CA-Nav achieves the state-of-the-art performance on two VLN-CE benchmarks, surpassing the previous best method by 12 percent and 13 percent in Success Rate on the validation unseen splits of R2R-CE and RxR-CE, respectively. Moreover, CA-Nav demonstrates its effectiveness in real-world robot deployments across various indoor scenes and instructions.
Category-level Object Detection, Pose Estimation and Reconstruction from Stereo Images
Jul 09, 2024We study the 3D object understanding task for manipulating everyday objects with different material properties (diffuse, specular, transparent and mixed). Existing monocular and RGB-D methods suffer from scale ambiguity due to missing or imprecise depth measurements. We present CODERS, a one-stage approach for Category-level Object Detection, pose Estimation and Reconstruction from Stereo images. The base of our pipeline is an implicit stereo matching module that combines stereo image features with 3D position information. Concatenating this presented module and the following transform-decoder architecture leads to end-to-end learning of multiple tasks required by robot manipulation. Our approach significantly outperforms all competing methods in the public TOD dataset. Furthermore, trained on simulated data, CODERS generalize well to unseen category-level object instances in real-world robot manipulation experiments. Our dataset, code, and demos will be available on our project page.
Mx2M: Masked Cross-Modality Modeling in Domain Adaptation for 3D Semantic Segmentation
Jul 09, 2023Existing methods of cross-modal domain adaptation for 3D semantic segmentation predict results only via 2D-3D complementarity that is obtained by cross-modal feature matching. However, as lacking supervision in the target domain, the complementarity is not always reliable. The results are not ideal when the domain gap is large. To solve the problem of lacking supervision, we introduce masked modeling into this task and propose a method Mx2M, which utilizes masked cross-modality modeling to reduce the large domain gap. Our Mx2M contains two components. One is the core solution, cross-modal removal and prediction (xMRP), which makes the Mx2M adapt to various scenarios and provides cross-modal self-supervision. The other is a new way of cross-modal feature matching, the dynamic cross-modal filter (DxMF) that ensures the whole method dynamically uses more suitable 2D-3D complementarity. Evaluation of the Mx2M on three DA scenarios, including Day/Night, USA/Singapore, and A2D2/SemanticKITTI, brings large improvements over previous methods on many metrics.
A Miniaturised Camera-based Multi-Modal Tactile Sensor
Mar 06, 2023



In conjunction with huge recent progress in camera and computer vision technology, camera-based sensors have increasingly shown considerable promise in relation to tactile sensing. In comparison to competing technologies (be they resistive, capacitive or magnetic based), they offer super-high-resolution, while suffering from fewer wiring problems. The human tactile system is composed of various types of mechanoreceptors, each able to perceive and process distinct information such as force, pressure, texture, etc. Camera-based tactile sensors such as GelSight mainly focus on high-resolution geometric sensing on a flat surface, and their force measurement capabilities are limited by the hysteresis and non-linearity of the silicone material. In this paper, we present a miniaturised dome-shaped camera-based tactile sensor that allows accurate force and tactile sensing in a single coherent system. The key novelty of the sensor design is as follows. First, we demonstrate how to build a smooth silicone hemispheric sensing medium with uniform markers on its curved surface. Second, we enhance the illumination of the rounded silicone with diffused LEDs. Third, we construct a force-sensitive mechanical structure in a compact form factor with usage of springs to accurately perceive forces. Our multi-modal sensor is able to acquire tactile information from multi-axis forces, local force distribution, and contact geometry, all in real-time. We apply an end-to-end deep learning method to process all the information.
HVC-Net: Unifying Homography, Visibility, and Confidence Learning for Planar Object Tracking
Sep 19, 2022


Robust and accurate planar tracking over a whole video sequence is vitally important for many vision applications. The key to planar object tracking is to find object correspondences, modeled by homography, between the reference image and the tracked image. Existing methods tend to obtain wrong correspondences with changing appearance variations, camera-object relative motions and occlusions. To alleviate this problem, we present a unified convolutional neural network (CNN) model that jointly considers homography, visibility, and confidence. First, we introduce correlation blocks that explicitly account for the local appearance changes and camera-object relative motions as the base of our model. Second, we jointly learn the homography and visibility that links camera-object relative motions with occlusions. Third, we propose a confidence module that actively monitors the estimation quality from the pixel correlation distributions obtained in correlation blocks. All these modules are plugged into a Lucas-Kanade (LK) tracking pipeline to obtain both accurate and robust planar object tracking. Our approach outperforms the state-of-the-art methods on public POT and TMT datasets. Its superior performance is also verified on a real-world application, synthesizing high-quality in-video advertisements.
Domain Adaptation Gaze Estimation by Embedding with Prediction Consistency
Nov 15, 2020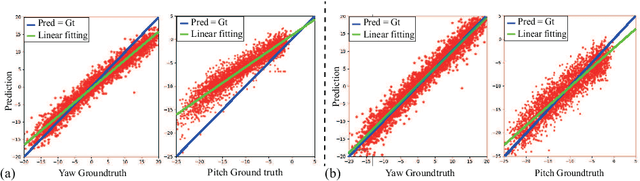
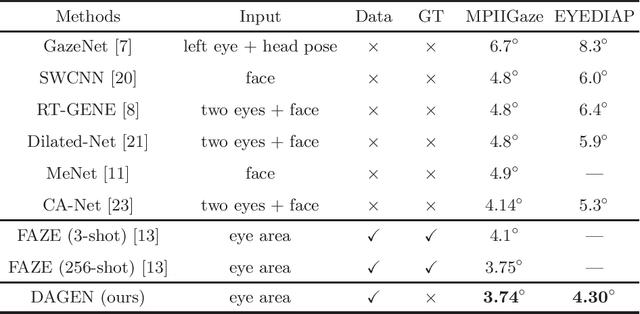
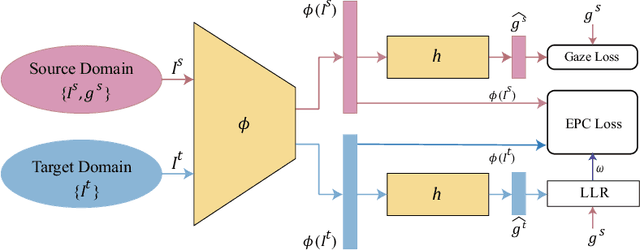

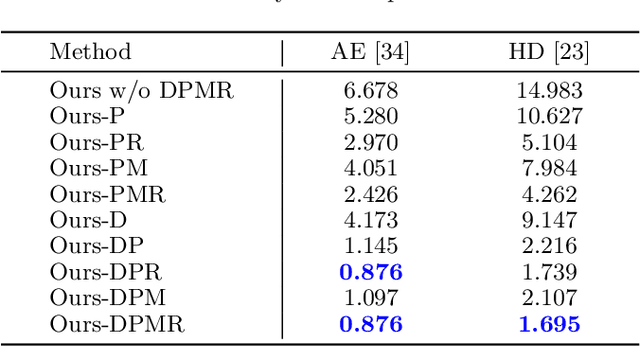
Gaze is the essential manifestation of human attention. In recent years, a series of work has achieved high accuracy in gaze estimation. However, the inter-personal difference limits the reduction of the subject-independent gaze estimation error. This paper proposes an unsupervised method for domain adaptation gaze estimation to eliminate the impact of inter-personal diversity. In domain adaption, we design an embedding representation with prediction consistency to ensure that the linear relationship between gaze directions in different domains remains consistent on gaze space and embedding space. Specifically, we employ source gaze to form a locally linear representation in the gaze space for each target domain prediction. Then the same linear combinations are applied in the embedding space to generate hypothesis embedding for the target domain sample, remaining prediction consistency. The deviation between the target and source domain is reduced by approximating the predicted and hypothesis embedding for the target domain sample. Guided by the proposed strategy, we design Domain Adaptation Gaze Estimation Network(DAGEN), which learns embedding with prediction consistency and achieves state-of-the-art results on both the MPIIGaze and the EYEDIAP datasets.