 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWenLan 2.0: Make AI Imagine via a Multimodal Foundation Model
Oct 27, 2021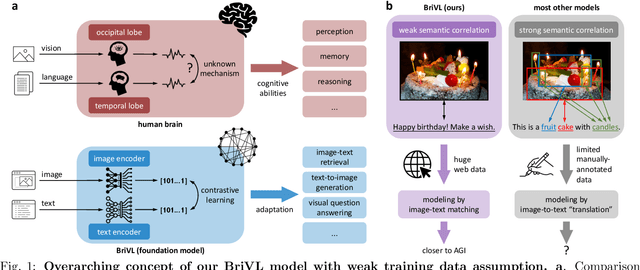


The fundamental goal of artificial intelligence (AI) is to mimic the core cognitive activities of human including perception, memory, and reasoning. Although tremendous success has been achieved in various AI research fields (e.g., computer vision and natural language processing), the majority of existing works only focus on acquiring single cognitive ability (e.g., image classification, reading comprehension, or visual commonsense reasoning). To overcome this limitation and take a solid step to artificial general intelligence (AGI), we develop a novel foundation model pre-trained with huge multimodal (visual and textual) data, which is able to be quickly adapted for a broad class of downstream cognitive tasks. Such a model is fundamentally different from the multimodal foundation models recently proposed in the literature that typically make strong semantic correlation assumption and expect exact alignment between image and text modalities in their pre-training data, which is often hard to satisfy in practice thus limiting their generalization abilities. To resolve this issue, we propose to pre-train our foundation model by self-supervised learning with weak semantic correlation data crawled from the Internet and show that state-of-the-art results can be obtained on a wide range of downstream tasks (both single-modal and cross-modal). Particularly, with novel model-interpretability tools developed in this work, we demonstrate that strong imagination ability (even with hints of commonsense) is now possessed by our foundation model. We believe our work makes a transformative stride towards AGI and will have broad impact on various AI+ fields (e.g., neuroscience and healthcare).
Pre-Trained Models: Past, Present and Future
Jun 15, 2021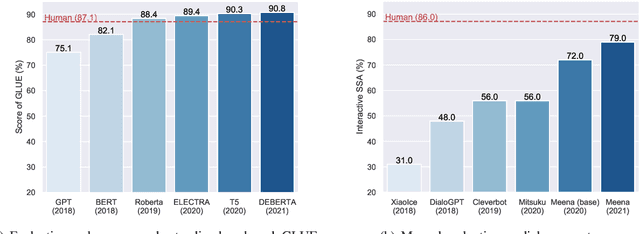
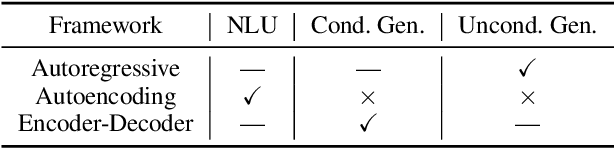
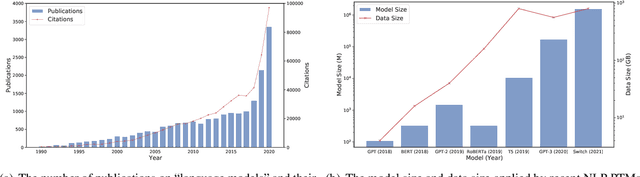
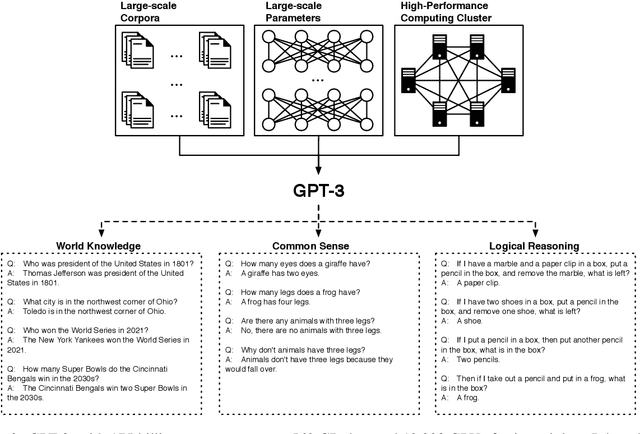
Large-scale pre-trained models (PTMs) such as BERT and GPT have recently achieved great success and become a milestone in the field of artificial intelligence (AI). Owing to sophisticated pre-training objectives and huge model parameters, large-scale PTMs can effectively capture knowledge from massive labeled and unlabeled data. By storing knowledge into huge parameters and fine-tuning on specific tasks, the rich knowledge implicitly encoded in huge parameters can benefit a variety of downstream tasks, which has been extensively demonstrated via experimental verification and empirical analysis. It is now the consensus of the AI community to adopt PTMs as backbone for downstream tasks rather than learning models from scratch. In this paper, we take a deep look into the history of pre-training, especially its special relation with transfer learning and self-supervised learning, to reveal the crucial position of PTMs in the AI development spectrum. Further, we comprehensively review the latest breakthroughs of PTMs. These breakthroughs are driven by the surge of computational power and the increasing availability of data, towards four important directions: designing effective architectures, utilizing rich contexts, improving computational efficiency, and conducting interpretation and theoretical analysis. Finally, we discuss a series of open problems and research directions of PTMs, and hope our view can inspire and advance the future study of PTMs.
HR-NAS: Searching Efficient High-Resolution Neural Architectures with Lightweight Transformers
Jun 11, 2021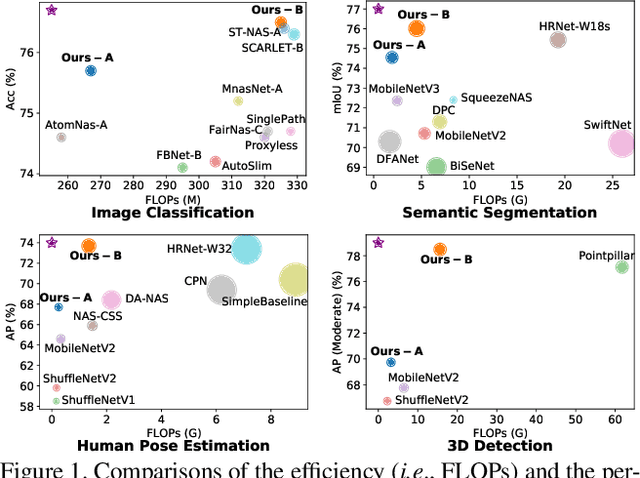
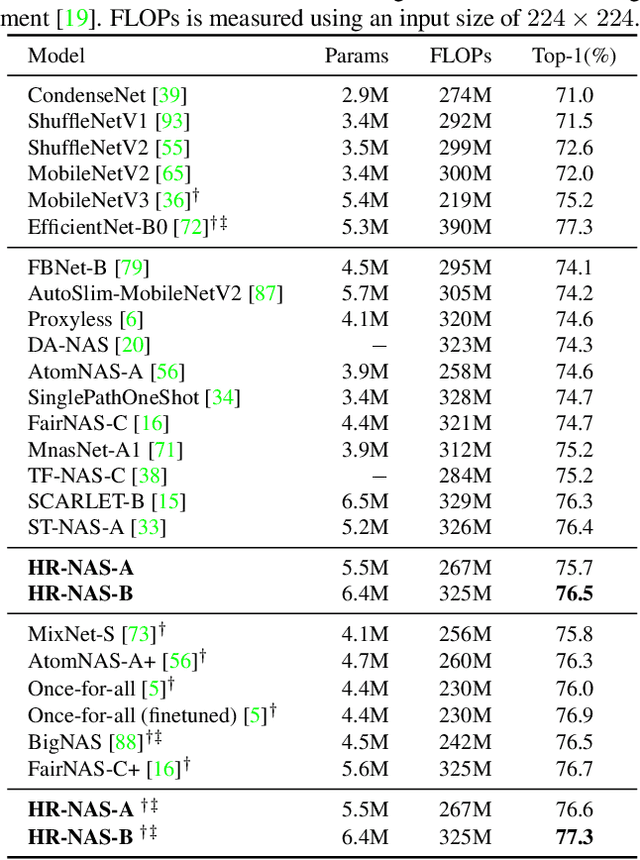
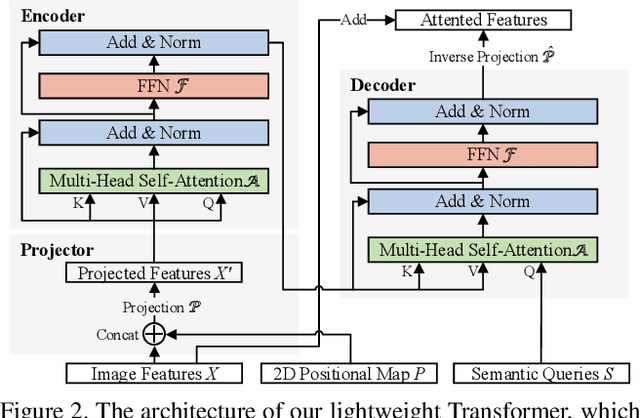
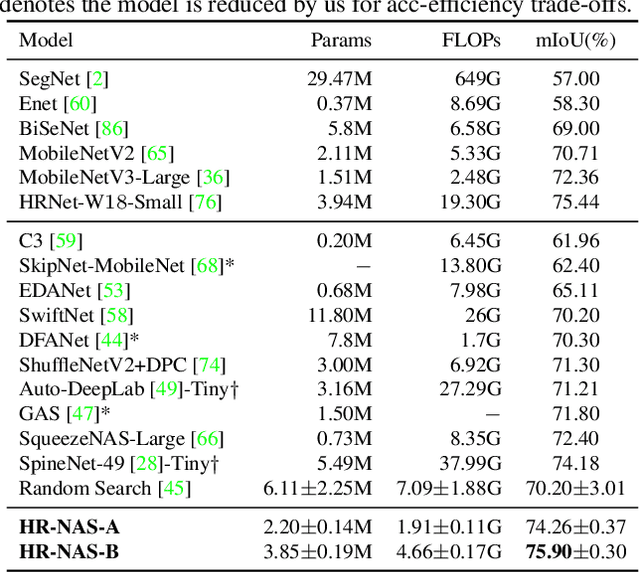
High-resolution representations (HR) are essential for dense prediction tasks such as segmentation, detection, and pose estimation. Learning HR representations is typically ignored in previous Neural Architecture Search (NAS) methods that focus on image classification. This work proposes a novel NAS method, called HR-NAS, which is able to find efficient and accurate networks for different tasks, by effectively encoding multiscale contextual information while maintaining high-resolution representations. In HR-NAS, we renovate the NAS search space as well as its searching strategy. To better encode multiscale image contexts in the search space of HR-NAS, we first carefully design a lightweight transformer, whose computational complexity can be dynamically changed with respect to different objective functions and computation budgets. To maintain high-resolution representations of the learned networks, HR-NAS adopts a multi-branch architecture that provides convolutional encoding of multiple feature resolutions, inspired by HRNet. Last, we proposed an efficient fine-grained search strategy to train HR-NAS, which effectively explores the search space, and finds optimal architectures given various tasks and computation resources. HR-NAS is capable of achieving state-of-the-art trade-offs between performance and FLOPs for three dense prediction tasks and an image classification task, given only small computational budgets. For example, HR-NAS surpasses SqueezeNAS that is specially designed for semantic segmentation while improving efficiency by 45.9%. Code is available at https://github.com/dingmyu/HR-NAS
SVT-Net: Super Light-Weight Sparse Voxel Transformer for Large Scale Place Recognition
May 30, 2021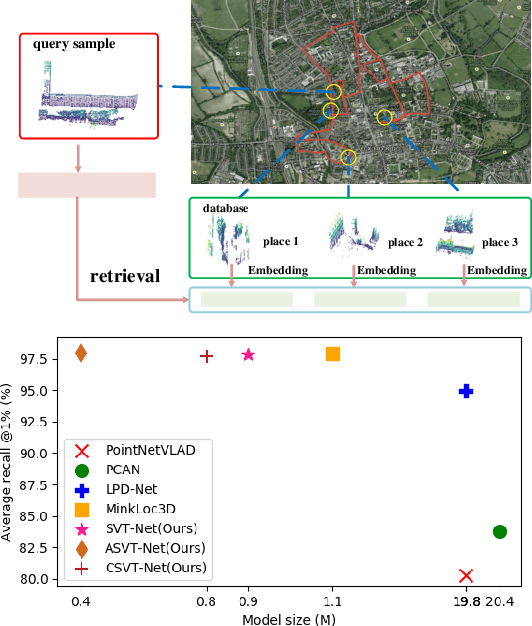
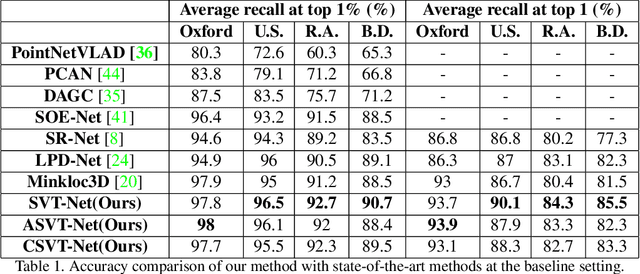
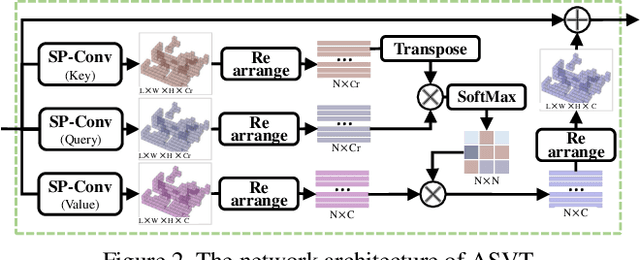
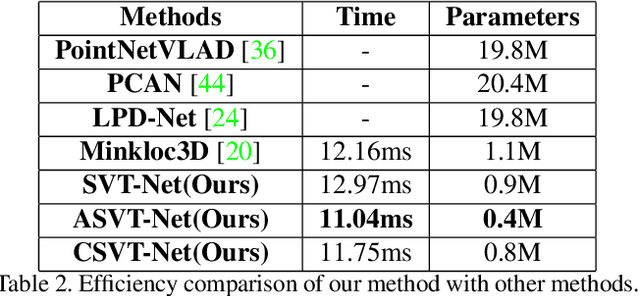
Point cloud-based large scale place recognition is fundamental for many applications like Simultaneous Localization and Mapping (SLAM). Although many models have been proposed and have achieved good performance by learning short-range local features, long-range contextual properties have often been neglected. Moreover, the model size has also become a bottleneck for their wide applications. To overcome these challenges, we propose a super light-weight network model termed SVT-Net for large scale place recognition. Specifically, on top of the highly efficient 3D Sparse Convolution (SP-Conv), an Atom-based Sparse Voxel Transformer (ASVT) and a Cluster-based Sparse Voxel Transformer (CSVT) are proposed to learn both short-range local features and long-range contextual features in this model. Consisting of ASVT and CSVT, SVT-Net can achieve state-of-the-art on benchmark datasets in terms of both accuracy and speed with a super-light model size (0.9M). Meanwhile, two simplified versions of SVT-Net are introduced, which also achieve state-of-the-art and further reduce the model size to 0.8M and 0.4M respectively.
Learning Versatile Neural Architectures by Propagating Network Codes
Mar 24, 2021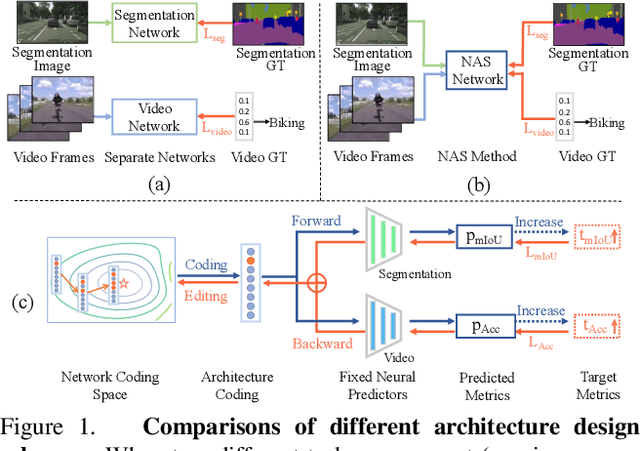

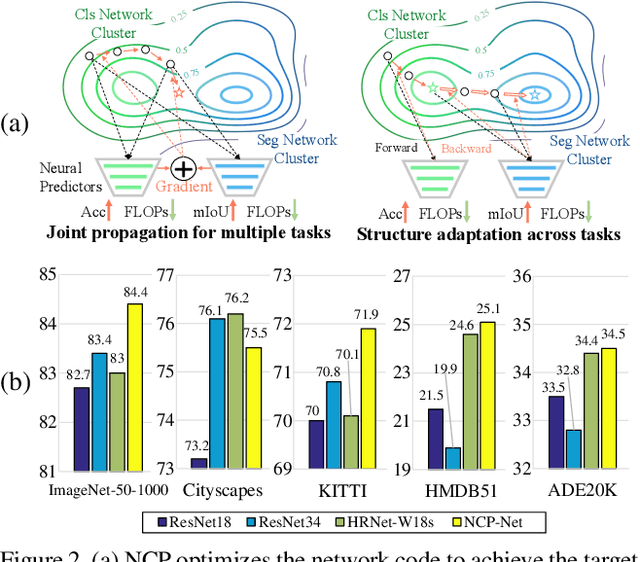
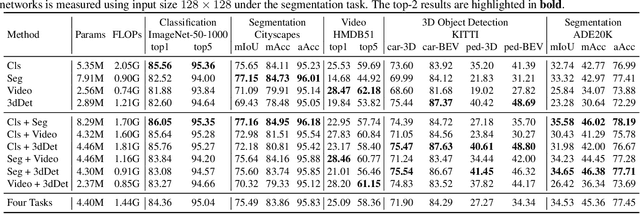
This work explores how to design a single neural network that is capable of adapting to multiple heterogeneous tasks of computer vision, such as image segmentation, 3D detection, and video recognition. This goal is challenging because network architecture designs in different tasks are inconsistent. We solve this challenge by proposing Network Coding Propagation (NCP), a novel "neural predictor", which is able to predict an architecture's performance in multiple datasets and tasks. Unlike prior arts of neural architecture search (NAS) that typically focus on a single task, NCP has several unique benefits. (1) NCP can be trained on different NAS benchmarks, such as NAS-Bench-201 and NAS-Bench-MR, which contains a novel network space designed by us for jointly searching an architecture among multiple tasks, including ImageNet, Cityscapes, KITTI, and HMDB51. (2) NCP learns from network codes but not original data, enabling it to update the architecture efficiently across datasets. (3) Extensive experiments evaluate NCP on object classification, detection, segmentation, and video recognition. For example, with 17\% fewer FLOPs, a single architecture returned by NCP achieves 86\% and 77.16\% on ImageNet-50-1000 and Cityscapes respectively, outperforming its counterparts. More interestingly, NCP enables a single architecture applicable to both image segmentation and video recognition, which achieves competitive performance on both HMDB51 and ADE20K compared to the singular counterparts. Code is available at https://github.com/dingmyu/NCP}{https://github.com/dingmyu/NCP.
WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training
Mar 19, 2021
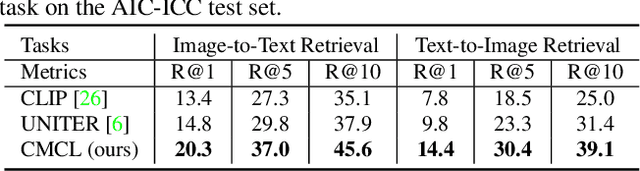
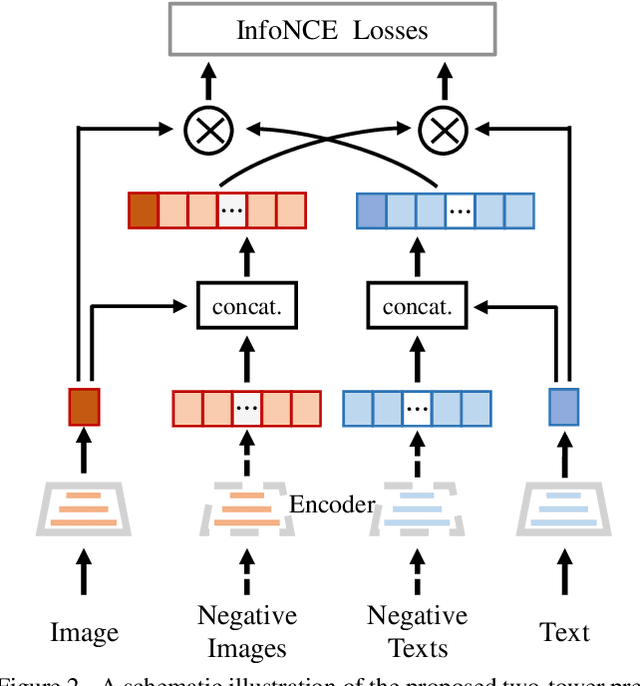
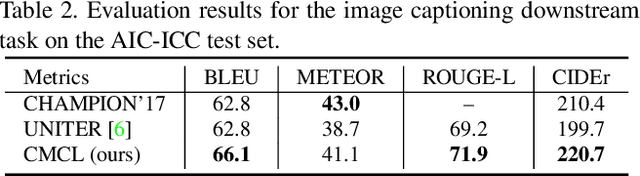
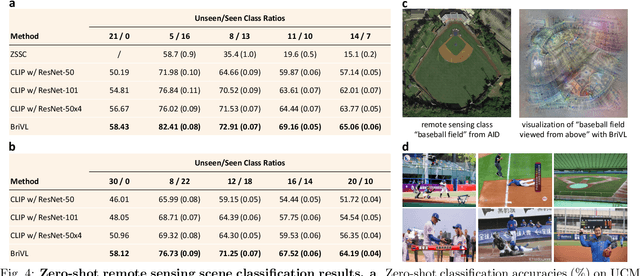
Multi-modal pre-training models have been intensively explored to bridge vision and language in recent years. However, most of them explicitly model the cross-modal interaction between image-text pairs, by assuming that there exists strong semantic correlation between the text and image modalities. Since this strong assumption is often invalid in real-world scenarios, we choose to implicitly model the cross-modal correlation for large-scale multi-modal pre-training, which is the focus of the Chinese project `WenLan' led by our team. Specifically, with the weak correlation assumption over image-text pairs, we propose a two-tower pre-training model called BriVL within the cross-modal contrastive learning framework. Unlike OpenAI CLIP that adopts a simple contrastive learning method, we devise a more advanced algorithm by adapting the latest method MoCo into the cross-modal scenario. By building a large queue-based dictionary, our BriVL can incorporate more negative samples in limited GPU resources. We further construct a large Chinese multi-source image-text dataset called RUC-CAS-WenLan for pre-training our BriVL model. Extensive experiments demonstrate that the pre-trained BriVL model outperforms both UNITER and OpenAI CLIP on various downstream tasks.
Contrastive Prototype Learning with Augmented Embeddings for Few-Shot Learning
Jan 23, 2021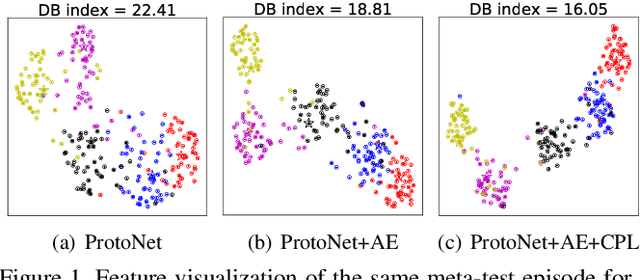
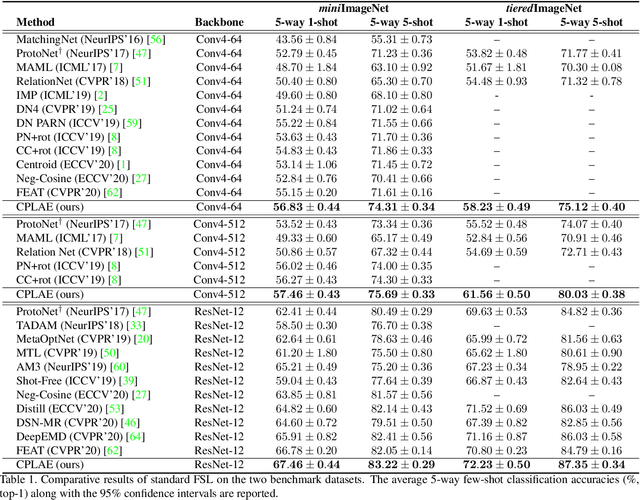
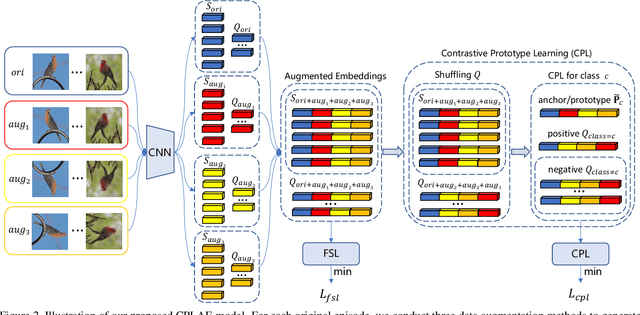

Most recent few-shot learning (FSL) methods are based on meta-learning with episodic training. In each meta-training episode, a discriminative feature embedding and/or classifier are first constructed from a support set in an inner loop, and then evaluated in an outer loop using a query set for model updating. This query set sample centered learning objective is however intrinsically limited in addressing the lack of training data problem in the support set. In this paper, a novel contrastive prototype learning with augmented embeddings (CPLAE) model is proposed to overcome this limitation. First, data augmentations are introduced to both the support and query sets with each sample now being represented as an augmented embedding (AE) composed of concatenated embeddings of both the original and augmented versions. Second, a novel support set class prototype centered contrastive loss is proposed for contrastive prototype learning (CPL). With a class prototype as an anchor, CPL aims to pull the query samples of the same class closer and those of different classes further away. This support set sample centered loss is highly complementary to the existing query centered loss, fully exploiting the limited training data in each episode. Extensive experiments on several benchmarks demonstrate that our proposed CPLAE achieves new state-of-the-art.
Margin-Based Transfer Bounds for Meta Learning with Deep Feature Embedding
Dec 02, 2020

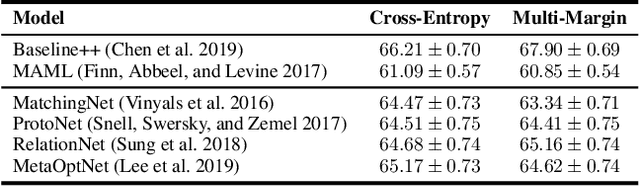
By transferring knowledge learned from seen/previous tasks, meta learning aims to generalize well to unseen/future tasks. Existing meta-learning approaches have shown promising empirical performance on various multiclass classification problems, but few provide theoretical analysis on the classifiers' generalization ability on future tasks. In this paper, under the assumption that all classification tasks are sampled from the same meta-distribution, we leverage margin theory and statistical learning theory to establish three margin-based transfer bounds for meta-learning based multiclass classification (MLMC). These bounds reveal that the expected error of a given classification algorithm for a future task can be estimated with the average empirical error on a finite number of previous tasks, uniformly over a class of preprocessing feature maps/deep neural networks (i.e. deep feature embeddings). To validate these bounds, instead of the commonly-used cross-entropy loss, a multi-margin loss is employed to train a number of representative MLMC models. Experiments on three benchmarks show that these margin-based models still achieve competitive performance, validating the practical value of our margin-based theoretical analysis.
Counterfactual VQA: A Cause-Effect Look at Language Bias
Jun 15, 2020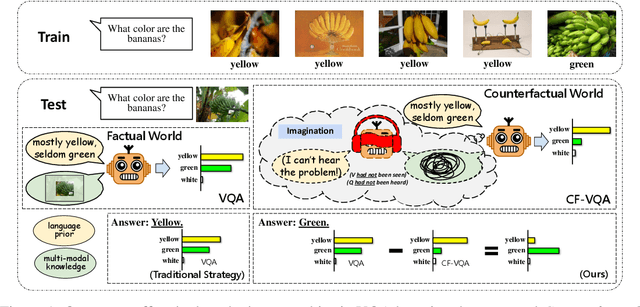
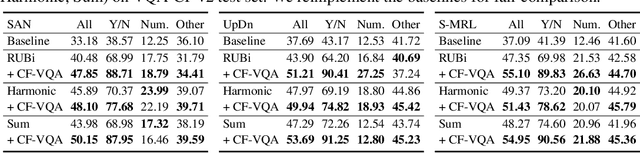
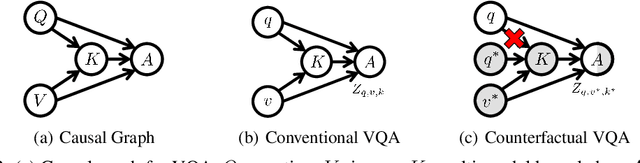
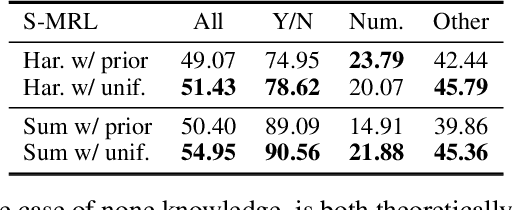
Visual Question Answering (VQA) models tend to rely on the language bias and thus fail to learn the reasoning from visual knowledge, which is however the original intention of VQA. In this paper, we propose a novel cause-effect look at the language bias, where the bias is formulated as the direct effect of question on answer from the view of causal inference. The effect can be captured by counterfactual VQA, where the image had not existed in an imagined scenario. Our proposed cause-effect look 1) is general to any baseline VQA architecture, 2) achieves significant improvement on the language-bias sensitive VQA-CP dataset, and 3) fills the theoretical gap in recent language prior based works.
Domain-Adaptive Few-Shot Learning
Mar 19, 2020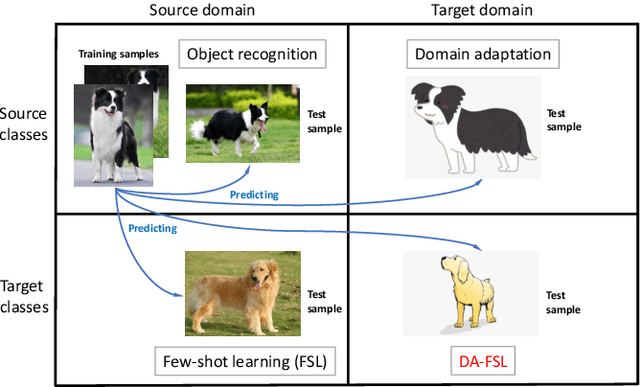
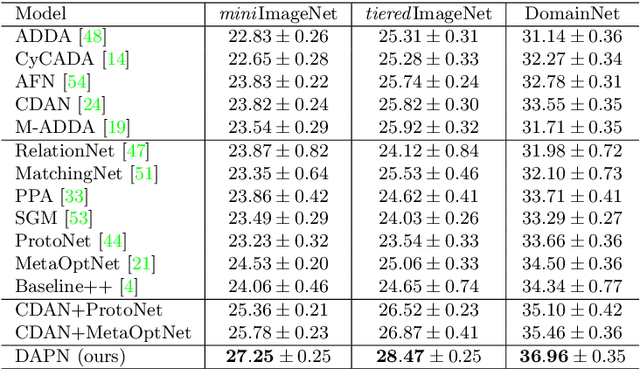
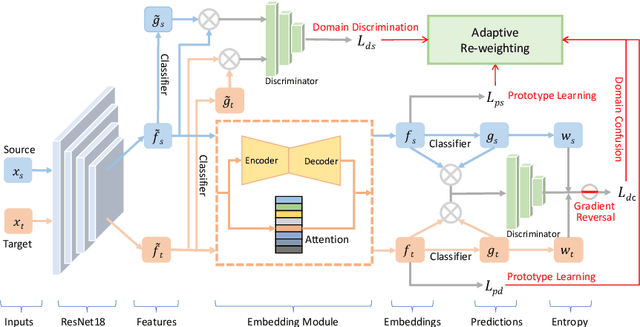
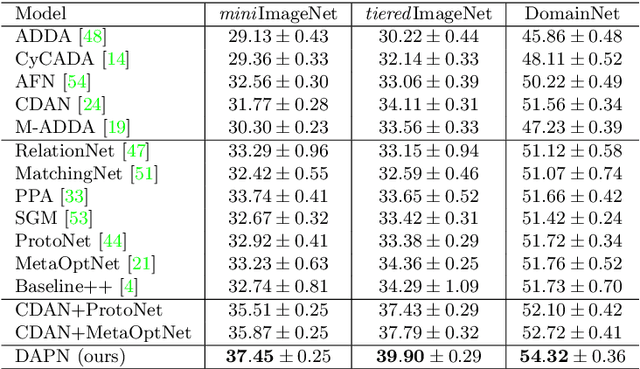
Existing few-shot learning (FSL) methods make the implicit assumption that the few target class samples are from the same domain as the source class samples. However, in practice this assumption is often invalid -- the target classes could come from a different domain. This poses an additional challenge of domain adaptation (DA) with few training samples. In this paper, the problem of domain-adaptive few-shot learning (DA-FSL) is tackled, which requires solving FSL and DA in a unified framework. To this end, we propose a novel domain-adversarial prototypical network (DAPN) model. It is designed to address a specific challenge in DA-FSL: the DA objective means that the source and target data distributions need to be aligned, typically through a shared domain-adaptive feature embedding space; but the FSL objective dictates that the target domain per class distribution must be different from that of any source domain class, meaning aligning the distributions across domains may harm the FSL performance. How to achieve global domain distribution alignment whilst maintaining source/target per-class discriminativeness thus becomes the key. Our solution is to explicitly enhance the source/target per-class separation before domain-adaptive feature embedding learning in the DAPN, in order to alleviate the negative effect of domain alignment on FSL. Extensive experiments show that our DAPN outperforms the state-of-the-art FSL and DA models, as well as their na\"ive combinations. The code is available at https://github.com/dingmyu/DAPN.