 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlleviating LLM-based Generative Retrieval Hallucination in Alipay Search
Mar 27, 2025



Generative retrieval (GR) has revolutionized document retrieval with the advent of large language models (LLMs), and LLM-based GR is gradually being adopted by the industry. Despite its remarkable advantages and potential, LLM-based GR suffers from hallucination and generates documents that are irrelevant to the query in some instances, severely challenging its credibility in practical applications. We thereby propose an optimized GR framework designed to alleviate retrieval hallucination, which integrates knowledge distillation reasoning in model training and incorporate decision agent to further improve retrieval precision. Specifically, we employ LLMs to assess and reason GR retrieved query-document (q-d) pairs, and then distill the reasoning data as transferred knowledge to the GR model. Moreover, we utilize a decision agent as post-processing to extend the GR retrieved documents through retrieval model and select the most relevant ones from multi perspectives as the final generative retrieval result. Extensive offline experiments on real-world datasets and online A/B tests on Fund Search and Insurance Search in Alipay demonstrate our framework's superiority and effectiveness in improving search quality and conversion gains.
TikTalk: A Multi-Modal Dialogue Dataset for Real-World Chitchat
Jan 14, 2023



We present a novel multi-modal chitchat dialogue dataset-TikTalk aimed at facilitating the research of intelligent chatbots. It consists of the videos and corresponding dialogues users generate on video social applications. In contrast to existing multi-modal dialogue datasets, we construct dialogue corpora based on video comment-reply pairs, which is more similar to chitchat in real-world dialogue scenarios. Our dialogue context includes three modalities: text, vision, and audio. Compared with previous image-based dialogue datasets, the richer sources of context in TikTalk lead to a greater diversity of conversations. TikTalk contains over 38K videos and 367K dialogues. Data analysis shows that responses in TikTalk are in correlation with various contexts and external knowledge. It poses a great challenge for the deep understanding of multi-modal information and the generation of responses. We evaluate several baselines on three types of automatic metrics and conduct case studies. Experimental results demonstrate that there is still a large room for future improvement on TikTalk. Our dataset is available at \url{https://github.com/RUC-AIMind/TikTalk}.
Multimodal foundation models are better simulators of the human brain
Aug 17, 2022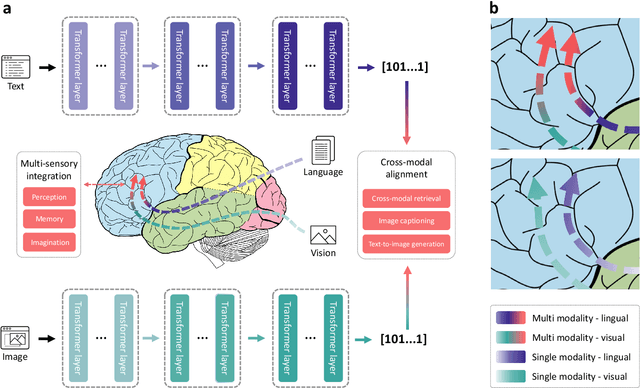
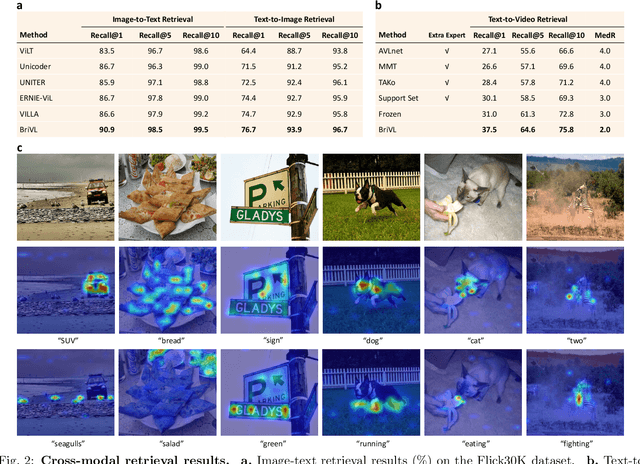

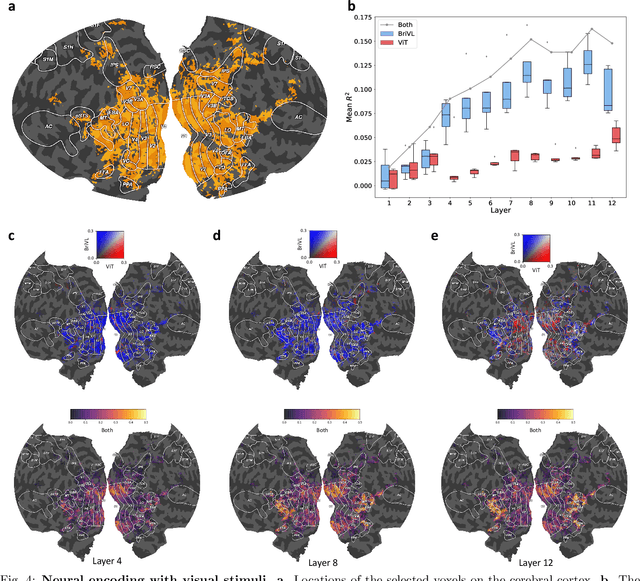
Multimodal learning, especially large-scale multimodal pre-training, has developed rapidly over the past few years and led to the greatest advances in artificial intelligence (AI). Despite its effectiveness, understanding the underlying mechanism of multimodal pre-training models still remains a grand challenge. Revealing the explainability of such models is likely to enable breakthroughs of novel learning paradigms in the AI field. To this end, given the multimodal nature of the human brain, we propose to explore the explainability of multimodal learning models with the aid of non-invasive brain imaging technologies such as functional magnetic resonance imaging (fMRI). Concretely, we first present a newly-designed multimodal foundation model pre-trained on 15 million image-text pairs, which has shown strong multimodal understanding and generalization abilities in a variety of cognitive downstream tasks. Further, from the perspective of neural encoding (based on our foundation model), we find that both visual and lingual encoders trained multimodally are more brain-like compared with unimodal ones. Particularly, we identify a number of brain regions where multimodally-trained encoders demonstrate better neural encoding performance. This is consistent with the findings in existing studies on exploring brain multi-sensory integration. Therefore, we believe that multimodal foundation models are more suitable tools for neuroscientists to study the multimodal signal processing mechanisms in the human brain. Our findings also demonstrate the potential of multimodal foundation models as ideal computational simulators to promote both AI-for-brain and brain-for-AI research.
WenLan 2.0: Make AI Imagine via a Multimodal Foundation Model
Oct 27, 2021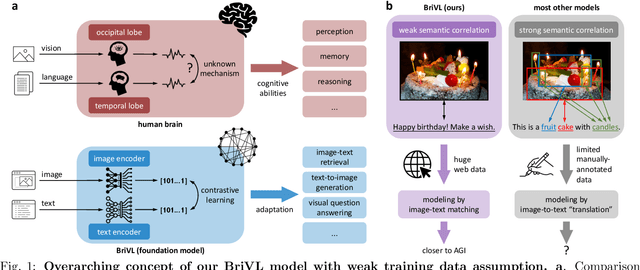


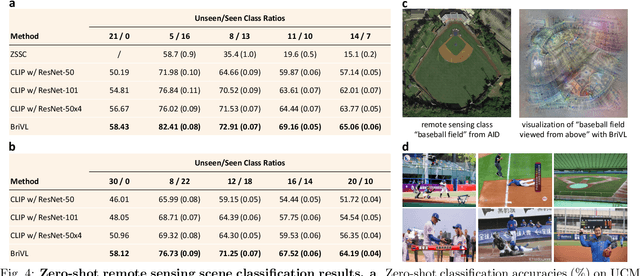
The fundamental goal of artificial intelligence (AI) is to mimic the core cognitive activities of human including perception, memory, and reasoning. Although tremendous success has been achieved in various AI research fields (e.g., computer vision and natural language processing), the majority of existing works only focus on acquiring single cognitive ability (e.g., image classification, reading comprehension, or visual commonsense reasoning). To overcome this limitation and take a solid step to artificial general intelligence (AGI), we develop a novel foundation model pre-trained with huge multimodal (visual and textual) data, which is able to be quickly adapted for a broad class of downstream cognitive tasks. Such a model is fundamentally different from the multimodal foundation models recently proposed in the literature that typically make strong semantic correlation assumption and expect exact alignment between image and text modalities in their pre-training data, which is often hard to satisfy in practice thus limiting their generalization abilities. To resolve this issue, we propose to pre-train our foundation model by self-supervised learning with weak semantic correlation data crawled from the Internet and show that state-of-the-art results can be obtained on a wide range of downstream tasks (both single-modal and cross-modal). Particularly, with novel model-interpretability tools developed in this work, we demonstrate that strong imagination ability (even with hints of commonsense) is now possessed by our foundation model. We believe our work makes a transformative stride towards AGI and will have broad impact on various AI+ fields (e.g., neuroscience and healthcare).
WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training
Mar 19, 2021
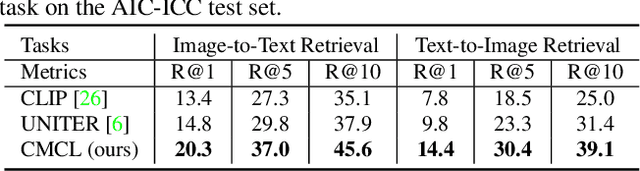
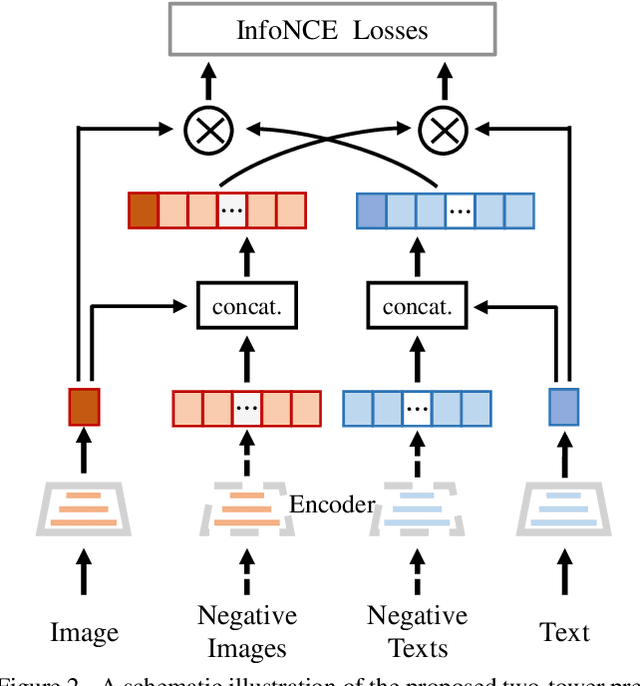
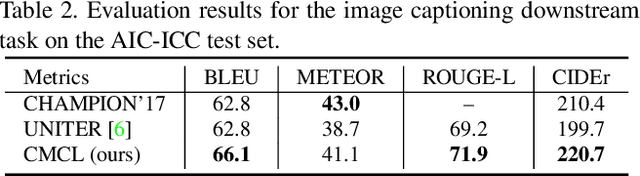
Multi-modal pre-training models have been intensively explored to bridge vision and language in recent years. However, most of them explicitly model the cross-modal interaction between image-text pairs, by assuming that there exists strong semantic correlation between the text and image modalities. Since this strong assumption is often invalid in real-world scenarios, we choose to implicitly model the cross-modal correlation for large-scale multi-modal pre-training, which is the focus of the Chinese project `WenLan' led by our team. Specifically, with the weak correlation assumption over image-text pairs, we propose a two-tower pre-training model called BriVL within the cross-modal contrastive learning framework. Unlike OpenAI CLIP that adopts a simple contrastive learning method, we devise a more advanced algorithm by adapting the latest method MoCo into the cross-modal scenario. By building a large queue-based dictionary, our BriVL can incorporate more negative samples in limited GPU resources. We further construct a large Chinese multi-source image-text dataset called RUC-CAS-WenLan for pre-training our BriVL model. Extensive experiments demonstrate that the pre-trained BriVL model outperforms both UNITER and OpenAI CLIP on various downstream tasks.