 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurface Vision Mamba: Leveraging Bidirectional State Space Model for Efficient Spherical Manifold Representation
Jan 24, 2025Attention-based methods have demonstrated exceptional performance in modelling long-range dependencies on spherical cortical surfaces, surpassing traditional Geometric Deep Learning (GDL) models. However, their extensive inference time and high memory demands pose challenges for application to large datasets with limited computing resources. Inspired by the state space model in computer vision, we introduce the attention-free Vision Mamba (Vim) to spherical surfaces, presenting a domain-agnostic architecture for analyzing data on spherical manifolds. Our method achieves surface patching by representing spherical data as a sequence of triangular patches derived from a subdivided icosphere. The proposed Surface Vision Mamba (SiM) is evaluated on multiple neurodevelopmental phenotype regression tasks using cortical surface metrics from neonatal brains. Experimental results demonstrate that SiM outperforms both attention- and GDL-based methods, delivering 4.8 times faster inference and achieving 91.7% lower memory consumption compared to the Surface Vision Transformer (SiT) under the Ico-4 grid partitioning. Sensitivity analysis further underscores the potential of SiM to identify subtle cognitive developmental patterns. The code is available at https://github.com/Rongzhao-He/surface-vision-mamba.
Are Large Language Models Possible to Conduct Cognitive Behavioral Therapy?
Jul 25, 2024



In contemporary society, the issue of psychological health has become increasingly prominent, characterized by the diversification, complexity, and universality of mental disorders. Cognitive Behavioral Therapy (CBT), currently the most influential and clinically effective psychological treatment method with no side effects, has limited coverage and poor quality in most countries. In recent years, researches on the recognition and intervention of emotional disorders using large language models (LLMs) have been validated, providing new possibilities for psychological assistance therapy. However, are LLMs truly possible to conduct cognitive behavioral therapy? Many concerns have been raised by mental health experts regarding the use of LLMs for therapy. Seeking to answer this question, we collected real CBT corpus from online video websites, designed and conducted a targeted automatic evaluation framework involving the evaluation of emotion tendency of generated text, structured dialogue pattern and proactive inquiry ability. For emotion tendency, we calculate the emotion tendency score of the CBT dialogue text generated by each model. For structured dialogue pattern, we use a diverse range of automatic evaluation metrics to compare speaking style, the ability to maintain consistency of topic and the use of technology in CBT between different models . As for inquiring to guide the patient, we utilize PQA (Proactive Questioning Ability) metric. We also evaluated the CBT ability of the LLM after integrating a CBT knowledge base to explore the help of introducing additional knowledge to enhance the model's CBT counseling ability. Four LLM variants with excellent performance on natural language processing are evaluated, and the experimental result shows the great potential of LLMs in psychological counseling realm, especially after combining with other technological means.
Identification of morphological fingerprint in perinatal brains using quasi-conformal mapping and contrastive learning
Nov 25, 2023



The morphological fingerprint in the brain is capable of identifying the uniqueness of an individual. However, whether such individual patterns are present in perinatal brains, and which morphological attributes or cortical regions better characterize the individual differences of ne-onates remain unclear. In this study, we proposed a deep learning framework that projected three-dimensional spherical meshes of three morphological features (i.e., cortical thickness, mean curvature, and sulcal depth) onto two-dimensional planes through quasi-conformal mapping, and employed the ResNet18 and contrastive learning for individual identification. We used the cross-sectional structural MRI data of 682 infants, incorporating with data augmentation, to train the model and fine-tuned the parameters based on 60 infants who had longitudinal scans. The model was validated on 30 longitudinal scanned infant data, and remarkable Top1 and Top5 accuracies of 71.37% and 84.10% were achieved, respectively. The sensorimotor and visual cortices were recognized as the most contributive regions in individual identification. Moreover, the folding morphology demonstrated greater discriminative capability than the cortical thickness, which could serve as the morphological fingerprint in perinatal brains. These findings provided evidence for the emergence of morphological fingerprints in the brain at the beginning of the third trimester, which may hold promising implications for understanding the formation of in-dividual uniqueness in the brain during early development.
A microstructure estimation Transformer inspired by sparse representation for diffusion MRI
May 13, 2022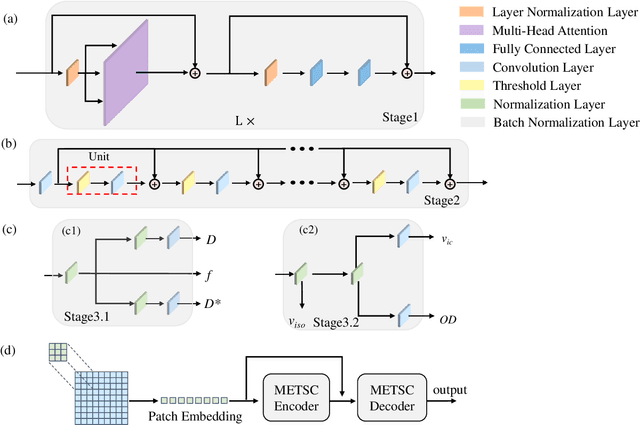
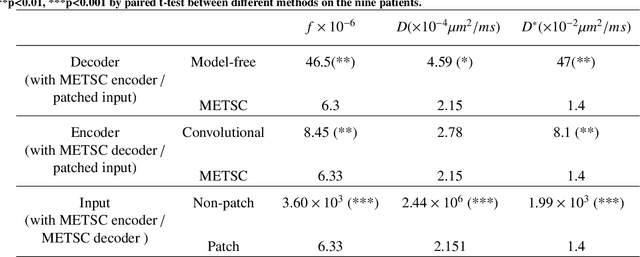
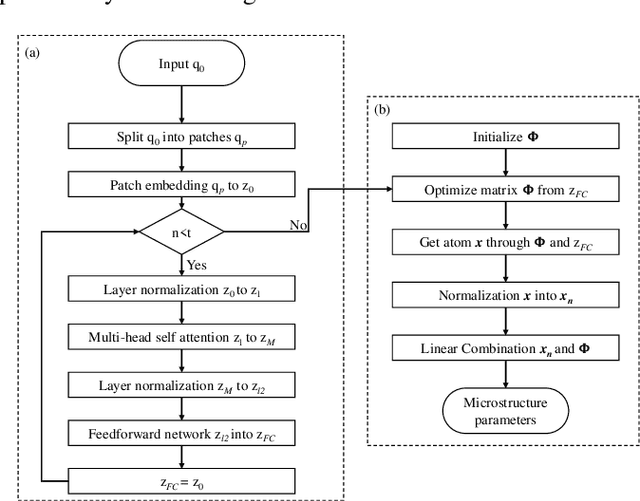

Diffusion magnetic resonance imaging (dMRI) is an important tool in characterizing tissue microstructure based on biophysical models, which are complex and highly non-linear. Resolving microstructures with optimization techniques is prone to estimation errors and requires dense sampling in the q-space. Deep learning based approaches have been proposed to overcome these limitations. Motivated by the superior performance of the Transformer, in this work, we present a learning-based framework based on Transformer, namely, a Microstructure Estimation Transformer with Sparse Coding (METSC) for dMRI-based microstructure estimation with downsampled q-space data. To take advantage of the Transformer while addressing its limitation in large training data requirements, we explicitly introduce an inductive bias - model bias into the Transformer using a sparse coding technique to facilitate the training process. Thus, the METSC is composed with three stages, an embedding stage, a sparse representation stage, and a mapping stage. The embedding stage is a Transformer-based structure that encodes the signal to ensure the voxel is represented effectively. In the sparse representation stage, a dictionary is constructed by solving a sparse reconstruction problem that unfolds the Iterative Hard Thresholding (IHT) process. The mapping stage is essentially a decoder that computes the microstructural parameters from the output of the second stage, based on the weighted sum of normalized dictionary coefficients where the weights are also learned. We tested our framework on two dMRI models with downsampled q-space data, including the intravoxel incoherent motion (IVIM) model and the neurite orientation dispersion and density imaging (NODDI) model. The proposed method achieved up to 11.25 folds of acceleration in scan time and outperformed the other state-of-the-art learning-based methods.
WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training
Mar 19, 2021
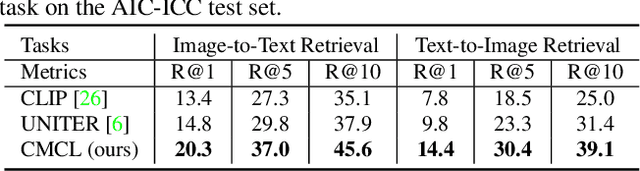
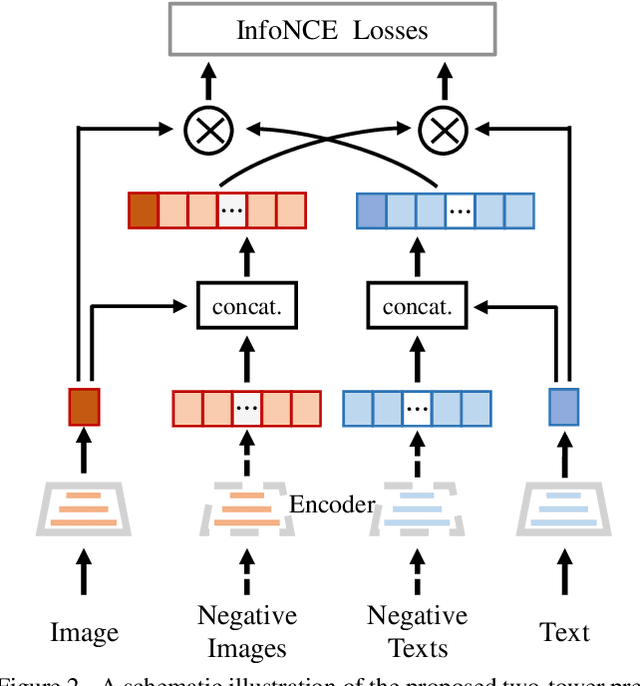
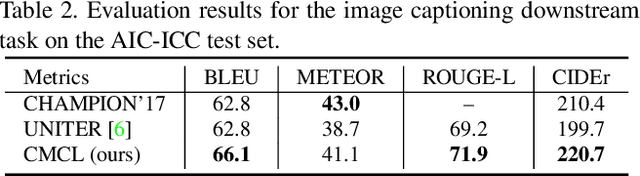
Multi-modal pre-training models have been intensively explored to bridge vision and language in recent years. However, most of them explicitly model the cross-modal interaction between image-text pairs, by assuming that there exists strong semantic correlation between the text and image modalities. Since this strong assumption is often invalid in real-world scenarios, we choose to implicitly model the cross-modal correlation for large-scale multi-modal pre-training, which is the focus of the Chinese project `WenLan' led by our team. Specifically, with the weak correlation assumption over image-text pairs, we propose a two-tower pre-training model called BriVL within the cross-modal contrastive learning framework. Unlike OpenAI CLIP that adopts a simple contrastive learning method, we devise a more advanced algorithm by adapting the latest method MoCo into the cross-modal scenario. By building a large queue-based dictionary, our BriVL can incorporate more negative samples in limited GPU resources. We further construct a large Chinese multi-source image-text dataset called RUC-CAS-WenLan for pre-training our BriVL model. Extensive experiments demonstrate that the pre-trained BriVL model outperforms both UNITER and OpenAI CLIP on various downstream tasks.