 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair-CDA: Continuous and Directional Augmentation for Group Fairness
Apr 01, 2023In this work, we propose {\it Fair-CDA}, a fine-grained data augmentation strategy for imposing fairness constraints. We use a feature disentanglement method to extract the features highly related to the sensitive attributes. Then we show that group fairness can be achieved by regularizing the models on transition paths of sensitive features between groups. By adjusting the perturbation strength in the direction of the paths, our proposed augmentation is controllable and auditable. To alleviate the accuracy degradation caused by fairness constraints, we further introduce a calibrated model to impute labels for the augmented data. Our proposed method does not assume any data generative model and ensures good generalization for both accuracy and fairness. Experimental results show that Fair-CDA consistently outperforms state-of-the-art methods on widely-used benchmarks, e.g., Adult, CelebA and MovieLens. Especially, Fair-CDA obtains an 86.3\% relative improvement for fairness while maintaining the accuracy on the Adult dataset. Moreover, we evaluate Fair-CDA in an online recommendation system to demonstrate the effectiveness of our method in terms of accuracy and fairness.
DDP: Diffusion Model for Dense Visual Prediction
Mar 30, 2023



We propose a simple, efficient, yet powerful framework for dense visual predictions based on the conditional diffusion pipeline. Our approach follows a "noise-to-map" generative paradigm for prediction by progressively removing noise from a random Gaussian distribution, guided by the image. The method, called DDP, efficiently extends the denoising diffusion process into the modern perception pipeline. Without task-specific design and architecture customization, DDP is easy to generalize to most dense prediction tasks, e.g., semantic segmentation and depth estimation. In addition, DDP shows attractive properties such as dynamic inference and uncertainty awareness, in contrast to previous single-step discriminative methods. We show top results on three representative tasks with six diverse benchmarks, without tricks, DDP achieves state-of-the-art or competitive performance on each task compared to the specialist counterparts. For example, semantic segmentation (83.9 mIoU on Cityscapes), BEV map segmentation (70.6 mIoU on nuScenes), and depth estimation (0.05 REL on KITTI). We hope that our approach will serve as a solid baseline and facilitate future research
Mixed Autoencoder for Self-supervised Visual Representation Learning
Mar 30, 2023Masked Autoencoder (MAE) has demonstrated superior performance on various vision tasks via randomly masking image patches and reconstruction. However, effective data augmentation strategies for MAE still remain open questions, different from those in contrastive learning that serve as the most important part. This paper studies the prevailing mixing augmentation for MAE. We first demonstrate that naive mixing will in contrast degenerate model performance due to the increase of mutual information (MI). To address, we propose homologous recognition, an auxiliary pretext task, not only to alleviate the MI increasement by explicitly requiring each patch to recognize homologous patches, but also to perform object-aware self-supervised pre-training for better downstream dense perception performance. With extensive experiments, we demonstrate that our proposed Mixed Autoencoder (MixedAE) achieves the state-of-the-art transfer results among masked image modeling (MIM) augmentations on different downstream tasks with significant efficiency. Specifically, our MixedAE outperforms MAE by +0.3% accuracy, +1.7 mIoU and +0.9 AP on ImageNet-1K, ADE20K and COCO respectively with a standard ViT-Base. Moreover, MixedAE surpasses iBOT, a strong MIM method combined with instance discrimination, while accelerating training by 2x. To our best knowledge, this is the very first work to consider mixing for MIM from the perspective of pretext task design. Code will be made available.
ContraNeRF: Generalizable Neural Radiance Fields for Synthetic-to-real Novel View Synthesis via Contrastive Learning
Mar 30, 2023Although many recent works have investigated generalizable NeRF-based novel view synthesis for unseen scenes, they seldom consider the synthetic-to-real generalization, which is desired in many practical applications. In this work, we first investigate the effects of synthetic data in synthetic-to-real novel view synthesis and surprisingly observe that models trained with synthetic data tend to produce sharper but less accurate volume densities. For pixels where the volume densities are correct, fine-grained details will be obtained. Otherwise, severe artifacts will be produced. To maintain the advantages of using synthetic data while avoiding its negative effects, we propose to introduce geometry-aware contrastive learning to learn multi-view consistent features with geometric constraints. Meanwhile, we adopt cross-view attention to further enhance the geometry perception of features by querying features across input views. Experiments demonstrate that under the synthetic-to-real setting, our method can render images with higher quality and better fine-grained details, outperforming existing generalizable novel view synthesis methods in terms of PSNR, SSIM, and LPIPS. When trained on real data, our method also achieves state-of-the-art results.
Entity-Level Text-Guided Image Manipulation
Feb 22, 2023



Existing text-guided image manipulation methods aim to modify the appearance of the image or to edit a few objects in a virtual or simple scenario, which is far from practical applications. In this work, we study a novel task on text-guided image manipulation on the entity level in the real world (eL-TGIM). The task imposes three basic requirements, (1) to edit the entity consistent with the text descriptions, (2) to preserve the entity-irrelevant regions, and (3) to merge the manipulated entity into the image naturally. To this end, we propose an elegant framework, dubbed as SeMani, forming the Semantic Manipulation of real-world images that can not only edit the appearance of entities but also generate new entities corresponding to the text guidance. To solve eL-TGIM, SeMani decomposes the task into two phases: the semantic alignment phase and the image manipulation phase. In the semantic alignment phase, SeMani incorporates a semantic alignment module to locate the entity-relevant region to be manipulated. In the image manipulation phase, SeMani adopts a generative model to synthesize new images conditioned on the entity-irrelevant regions and target text descriptions. We discuss and propose two popular generation processes that can be utilized in SeMani, the discrete auto-regressive generation with transformers and the continuous denoising generation with diffusion models, yielding SeMani-Trans and SeMani-Diff, respectively. We conduct extensive experiments on the real datasets CUB, Oxford, and COCO datasets to verify that SeMani can distinguish the entity-relevant and -irrelevant regions and achieve more precise and flexible manipulation in a zero-shot manner compared with baseline methods. Our codes and models will be released at https://github.com/Yikai-Wang/SeMani.
Boosting Out-of-Distribution Detection with Multiple Pre-trained Models
Dec 24, 2022



Out-of-Distribution (OOD) detection, i.e., identifying whether an input is sampled from a novel distribution other than the training distribution, is a critical task for safely deploying machine learning systems in the open world. Recently, post hoc detection utilizing pre-trained models has shown promising performance and can be scaled to large-scale problems. This advance raises a natural question: Can we leverage the diversity of multiple pre-trained models to improve the performance of post hoc detection methods? In this work, we propose a detection enhancement method by ensembling multiple detection decisions derived from a zoo of pre-trained models. Our approach uses the p-value instead of the commonly used hard threshold and leverages a fundamental framework of multiple hypothesis testing to control the true positive rate of In-Distribution (ID) data. We focus on the usage of model zoos and provide systematic empirical comparisons with current state-of-the-art methods on various OOD detection benchmarks. The proposed ensemble scheme shows consistent improvement compared to single-model detectors and significantly outperforms the current competitive methods. Our method substantially improves the relative performance by 65.40% and 26.96% on the CIFAR10 and ImageNet benchmarks.
Generative Negative Text Replay for Continual Vision-Language Pretraining
Oct 31, 2022



Vision-language pre-training (VLP) has attracted increasing attention recently. With a large amount of image-text pairs, VLP models trained with contrastive loss have achieved impressive performance in various tasks, especially the zero-shot generalization on downstream datasets. In practical applications, however, massive data are usually collected in a streaming fashion, requiring VLP models to continuously integrate novel knowledge from incoming data and retain learned knowledge. In this work, we focus on learning a VLP model with sequential chunks of image-text pair data. To tackle the catastrophic forgetting issue in this multi-modal continual learning setting, we first introduce pseudo text replay that generates hard negative texts conditioned on the training images in memory, which not only better preserves learned knowledge but also improves the diversity of negative samples in the contrastive loss. Moreover, we propose multi-modal knowledge distillation between images and texts to align the instance-wise prediction between old and new models. We incrementally pre-train our model on both the instance and class incremental splits of the Conceptual Caption dataset, and evaluate the model on zero-shot image classification and image-text retrieval tasks. Our method consistently outperforms the existing baselines with a large margin, which demonstrates its superiority. Notably, we realize an average performance boost of $4.60\%$ on image-classification downstream datasets for the class incremental split.
Dual-Curriculum Teacher for Domain-Inconsistent Object Detection in Autonomous Driving
Oct 17, 2022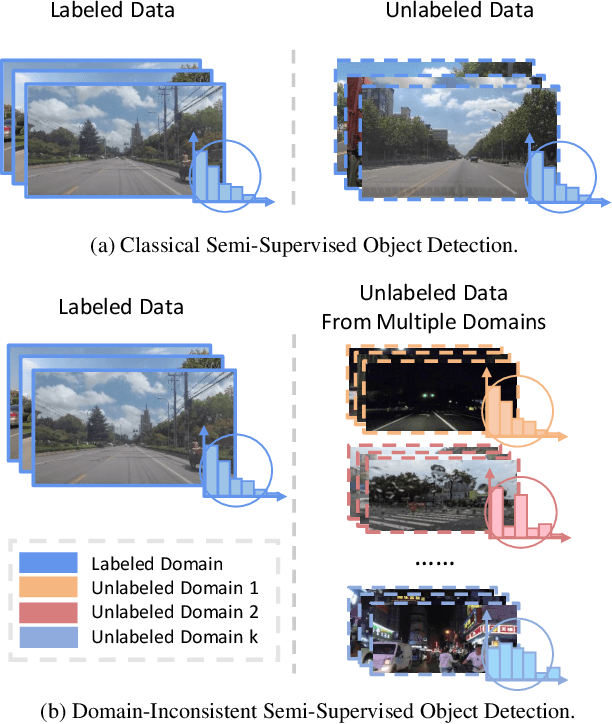
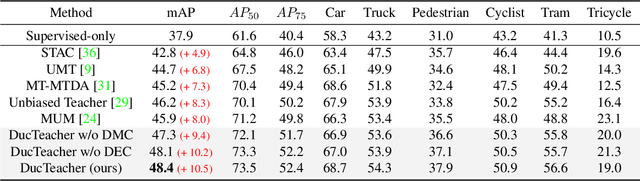
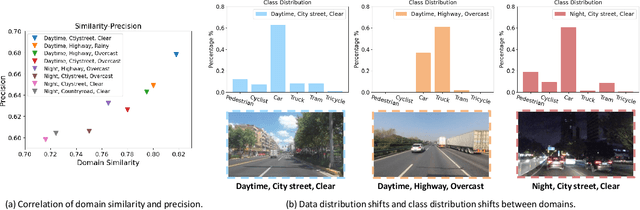
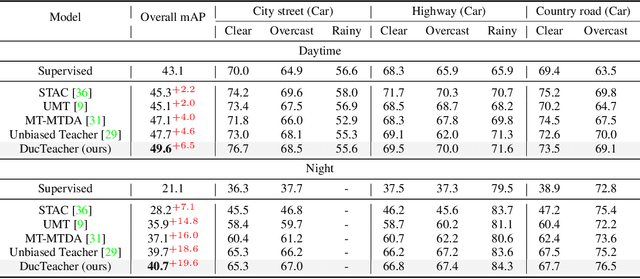
Object detection for autonomous vehicles has received increasing attention in recent years, where labeled data are often expensive while unlabeled data can be collected readily, calling for research on semi-supervised learning for this area. Existing semi-supervised object detection (SSOD) methods usually assume that the labeled and unlabeled data come from the same data distribution. In autonomous driving, however, data are usually collected from different scenarios, such as different weather conditions or different times in a day. Motivated by this, we study a novel but challenging domain inconsistent SSOD problem. It involves two kinds of distribution shifts among different domains, including (1) data distribution discrepancy, and (2) class distribution shifts, making existing SSOD methods suffer from inaccurate pseudo-labels and hurting model performance. To address this problem, we propose a novel method, namely Dual-Curriculum Teacher (DucTeacher). Specifically, DucTeacher consists of two curriculums, i.e., (1) domain evolving curriculum seeks to learn from the data progressively to handle data distribution discrepancy by estimating the similarity between domains, and (2) distribution matching curriculum seeks to estimate the class distribution for each unlabeled domain to handle class distribution shifts. In this way, DucTeacher can calibrate biased pseudo-labels and handle the domain-inconsistent SSOD problem effectively. DucTeacher shows its advantages on SODA10M, the largest public semi-supervised autonomous driving dataset, and COCO, a widely used SSOD benchmark. Experiments show that DucTeacher achieves new state-of-the-art performance on SODA10M with 2.2 mAP improvement and on COCO with 0.8 mAP improvement.
ZooD: Exploiting Model Zoo for Out-of-Distribution Generalization
Oct 17, 2022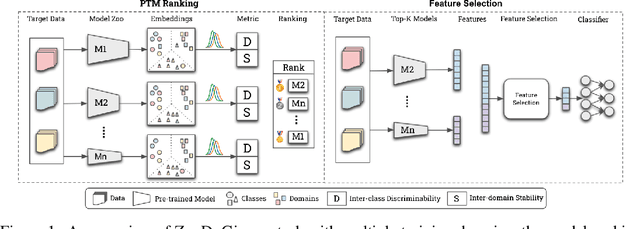

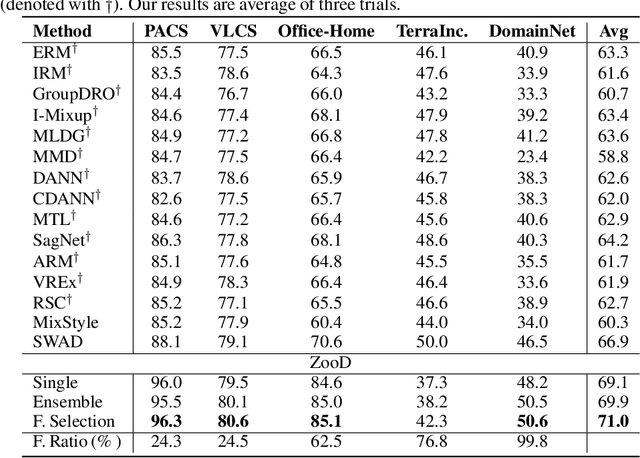
Recent advances on large-scale pre-training have shown great potentials of leveraging a large set of Pre-Trained Models (PTMs) for improving Out-of-Distribution (OoD) generalization, for which the goal is to perform well on possible unseen domains after fine-tuning on multiple training domains. However, maximally exploiting a zoo of PTMs is challenging since fine-tuning all possible combinations of PTMs is computationally prohibitive while accurate selection of PTMs requires tackling the possible data distribution shift for OoD tasks. In this work, we propose ZooD, a paradigm for PTMs ranking and ensemble with feature selection. Our proposed metric ranks PTMs by quantifying inter-class discriminability and inter-domain stability of the features extracted by the PTMs in a leave-one-domain-out cross-validation manner. The top-K ranked models are then aggregated for the target OoD task. To avoid accumulating noise induced by model ensemble, we propose an efficient variational EM algorithm to select informative features. We evaluate our paradigm on a diverse model zoo consisting of 35 models for various OoD tasks and demonstrate: (i) model ranking is better correlated with fine-tuning ranking than previous methods and up to 9859x faster than brute-force fine-tuning; (ii) OoD generalization after model ensemble with feature selection outperforms the state-of-the-art methods and the accuracy on most challenging task DomainNet is improved from 46.5\% to 50.6\%. Furthermore, we provide the fine-tuning results of 35 PTMs on 7 OoD datasets, hoping to help the research of model zoo and OoD generalization. Code will be available at https://gitee.com/mindspore/models/tree/master/research/cv/zood.
CAGroup3D: Class-Aware Grouping for 3D Object Detection on Point Clouds
Oct 09, 2022
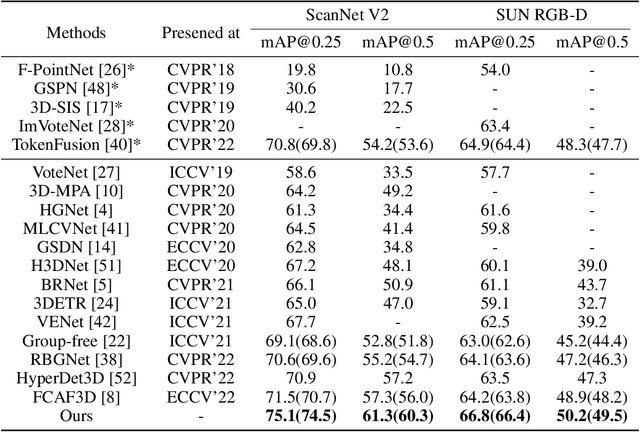
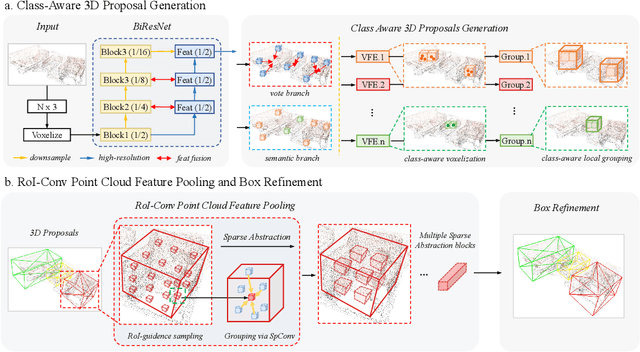

We present a novel two-stage fully sparse convolutional 3D object detection framework, named CAGroup3D. Our proposed method first generates some high-quality 3D proposals by leveraging the class-aware local group strategy on the object surface voxels with the same semantic predictions, which considers semantic consistency and diverse locality abandoned in previous bottom-up approaches. Then, to recover the features of missed voxels due to incorrect voxel-wise segmentation, we build a fully sparse convolutional RoI pooling module to directly aggregate fine-grained spatial information from backbone for further proposal refinement. It is memory-and-computation efficient and can better encode the geometry-specific features of each 3D proposal. Our model achieves state-of-the-art 3D detection performance with remarkable gains of +\textit{3.6\%} on ScanNet V2 and +\textit{2.6}\% on SUN RGB-D in term of mAP@0.25. Code will be available at https://github.com/Haiyang-W/CAGroup3D.