 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTANDEM: Bi-Level Data Mixture Optimization with Twin Networks
Jun 03, 2026The capabilities of large language models (LLMs) significantly depend on training data drawn from various domains. Optimizing domain-specific mixture ratios can be modeled as a bi-level optimization problem, which we simplify into a single-level penalized form and solve with twin networks: a proxy model trained on primary data and a dynamically updated reference model trained with additional data. Our proposed method, Twin Networks for bi-level DatA mixturE optiMization (TANDEM), measures the data efficacy through the difference between the twin models and up-weights domains that benefit more from the additional data. TANDEM provides theoretical guarantees and wider applicability, compared to prior approaches. Furthermore, our bi-level perspective suggests new settings to study domain reweighting such as data-restricted scenarios and supervised fine-tuning, where optimized mixture ratios significantly improve the performance. Extensive experiments validate TANDEM's effectiveness in all scenarios.
HTAM: Hierarchical Transition-Attended Memory for Operator Optimization
May 28, 2026High-performance GPU kernels are essential for efficient LLM deployment, yet optimizing them remains expertise-intensive. Recent LLM-based code generation makes automatic GPU operator generation promising, but operator optimization remains a hardware-aware search problem. Existing LLM-based methods face a granularity mismatch: coarse hints are reusable but hard to execute, whereas detailed memories are actionable but enlarge the search space and obscure optimization bottlenecks. The key challenge is therefore to organize optimization experience at an appropriate granularity. To address this issue, this paper proposes HTAM (Hierarchical Transition-Attended Memory), a coarse-to-fine framework for LLM-based operator optimization. HTAM builds a two-level Hierarchical Transition Graph (HTG) to organize coarse global directions, detailed local strategies, and transition experience between optimization steps. During each evolution step, HTAM selects a global direction from the current state and recent optimization history, retrieves the corresponding local strategy memory, and uses it to guide concrete CUDA code generation. Experiments on the full KernelBench suite demonstrate that HTAM consistently improves correctness, fast-solution rate, and speedup over LLM-based baselines, while backend and Robust-KBench studies indicate transferable benefits from structured memory.
OFA-Diffusion Compression: Compressing Diffusion Model in One-Shot Manner
Apr 14, 2026The Diffusion Probabilistic Model (DPM) achieves remarkable performance in image generation, while its increasing parameter size and computational overhead hinder its deployment in practical applications. To improve this, the existing literature focuses on obtaining a smaller model with a fixed architecture through model compression. However, in practice, DPMs usually need to be deployed on various devices with different resource constraints, which leads to multiple compression processes, incurring significant overhead for repeated training. To obviate this, we propose a once-for-all (OFA) compression framework for DPMs that yields different subnetworks with various computations in a one-shot training manner. The existing OFA framework typically involves massive subnetworks with different parameter sizes, while such a huge candidate space slows the optimization. Thus, we propose to restrict the candidate subnetworks with a certain set of parameter sizes, where each size corresponds to a specific subnetwork. Specifically, to construct each subnetwork with a given size, we gradually allocate the maintained channels by their importance. Furthermore, we propose a reweighting strategy to balance the optimization process of different subnetworks. Experimental results show that our approach can produce compressed DPMs for various sizes with significantly lower training overhead while achieving satisfactory performance.
Fragile Reconstruction: Adversarial Vulnerability of Reconstruction-Based Detectors for Diffusion-Generated Images
Apr 14, 2026Recently, detecting AI-generated images produced by diffusion-based models has attracted increasing attention due to their potential threat to safety. Among existing approaches, reconstruction-based methods have emerged as a prominent paradigm for this task. However, we find that such methods exhibit severe security vulnerabilities to adversarial perturbations; that is, by adding imperceptible adversarial perturbations to input images, the detection accuracy of classifiers collapses to near zero. To verify this threat, we present a systematic evaluation of the adversarial robustness of three representative detectors across four diverse generative backbone models. First, we construct adversarial attacks in white-box scenarios, which degrade the performance of all well-trained detectors. Moreover, we find that these attacks demonstrate transferability; specifically, attacks crafted against one detector can be transferred to others, indicating that adversarial attacks on detectors can also be constructed in a black-box setting. Finally, we assess common countermeasures and find that standard defense methods against adversarial attacks provide limited mitigation. We attribute these failures to the low signal-to-noise ratio (SNR) of attacked samples as perceived by the detectors. Overall, our results reveal fundamental security limitations of reconstruction-based detectors and highlight the need to rethink existing detection strategies.
Reasoning and Tool-use Compete in Agentic RL:From Quantifying Interference to Disentangled Tuning
Feb 01, 2026Agentic Reinforcement Learning (ARL) focuses on training large language models (LLMs) to interleave reasoning with external tool execution to solve complex tasks. Most existing ARL methods train a single shared model parameters to support both reasoning and tool use behaviors, implicitly assuming that joint training leads to improved overall agent performance. Despite its widespread adoption, this assumption has rarely been examined empirically. In this paper, we systematically investigate this assumption by introducing a Linear Effect Attribution System(LEAS), which provides quantitative evidence of interference between reasoning and tool-use behaviors. Through an in-depth analysis, we show that these two capabilities often induce misaligned gradient directions, leading to training interference that undermines the effectiveness of joint optimization and challenges the prevailing ARL paradigm. To address this issue, we propose Disentangled Action Reasoning Tuning(DART), a simple and efficient framework that explicitly decouples parameter updates for reasoning and tool-use via separate low-rank adaptation modules. Experimental results show that DART consistently outperforms baseline methods with averaged 6.35 percent improvements and achieves performance comparable to multi-agent systems that explicitly separate tool-use and reasoning using a single model.
ETS: Energy-Guided Test-Time Scaling for Training-Free RL Alignment
Jan 29, 2026Reinforcement Learning (RL) post-training alignment for language models is effective, but also costly and unstable in practice, owing to its complicated training process. To address this, we propose a training-free inference method to sample directly from the optimal RL policy. The transition probability applied to Masked Language Modeling (MLM) consists of a reference policy model and an energy term. Based on this, our algorithm, Energy-Guided Test-Time Scaling (ETS), estimates the key energy term via online Monte Carlo, with a provable convergence rate. Moreover, to ensure practical efficiency, ETS leverages modern acceleration frameworks alongside tailored importance sampling estimators, substantially reducing inference latency while provably preserving sampling quality. Experiments on MLM (including autoregressive models and diffusion language models) across reasoning, coding, and science benchmarks show that our ETS consistently improves generation quality, validating its effectiveness and design.
Towards a Theoretical Understanding to the Generalization of RLHF
Jan 23, 2026Reinforcement Learning from Human Feedback (RLHF) and its variants have emerged as the dominant approaches for aligning Large Language Models with human intent. While empirically effective, the theoretical generalization properties of these methods in high-dimensional settings remain to be explored. To this end, we build the generalization theory on RLHF of LLMs under the linear reward model, through the framework of algorithmic stability. In contrast to the existing works built upon the consistency of maximum likelihood estimations on reward model, our analysis is presented under an end-to-end learning framework, which is consistent with practice. Concretely, we prove that under a key \textbf{feature coverage} condition, the empirical optima of policy model have a generalization bound of order $\mathcal{O}(n^{-\frac{1}{2}})$. Moreover, the results can be extrapolated to parameters obtained by gradient-based learning algorithms, i.e., Gradient Ascent (GA) and Stochastic Gradient Ascent (SGA). Thus, we argue that our results provide new theoretical evidence for the empirically observed generalization of LLMs after RLHF.
TR-PTS: Task-Relevant Parameter and Token Selection for Efficient Tuning
Jul 30, 2025Large pre-trained models achieve remarkable performance in vision tasks but are impractical for fine-tuning due to high computational and storage costs. Parameter-Efficient Fine-Tuning (PEFT) methods mitigate this issue by updating only a subset of parameters; however, most existing approaches are task-agnostic, failing to fully exploit task-specific adaptations, which leads to suboptimal efficiency and performance. To address this limitation, we propose Task-Relevant Parameter and Token Selection (TR-PTS), a task-driven framework that enhances both computational efficiency and accuracy. Specifically, we introduce Task-Relevant Parameter Selection, which utilizes the Fisher Information Matrix (FIM) to identify and fine-tune only the most informative parameters in a layer-wise manner, while keeping the remaining parameters frozen. Simultaneously, Task-Relevant Token Selection dynamically preserves the most informative tokens and merges redundant ones, reducing computational overhead. By jointly optimizing parameters and tokens, TR-PTS enables the model to concentrate on task-discriminative information. We evaluate TR-PTS on benchmark, including FGVC and VTAB-1k, where it achieves state-of-the-art performance, surpassing full fine-tuning by 3.40% and 10.35%, respectively. The code are available at https://github.com/synbol/TR-PTS.
Reward-SQL: Boosting Text-to-SQL via Stepwise Reasoning and Process-Supervised Rewards
May 07, 2025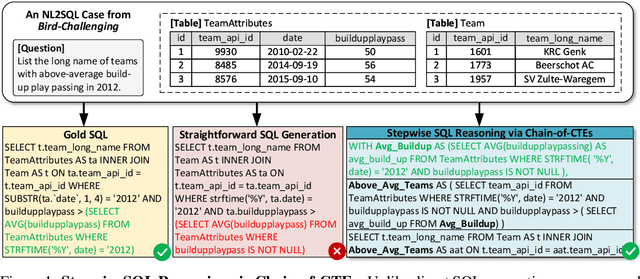
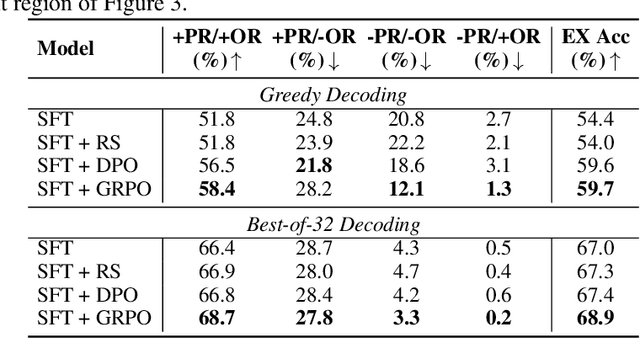
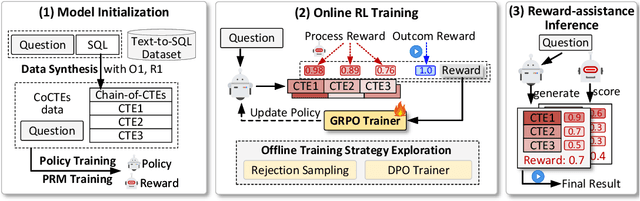
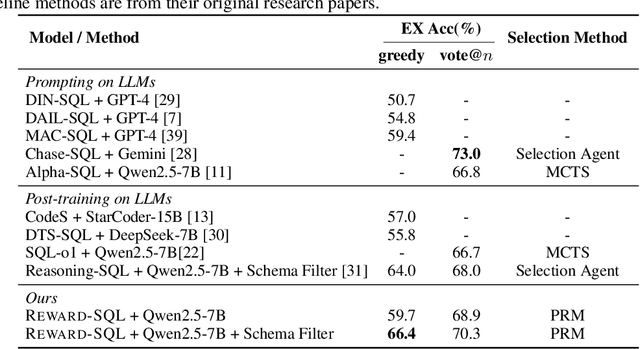
Recent advances in large language models (LLMs) have significantly improved performance on the Text-to-SQL task by leveraging their powerful reasoning capabilities. To enhance accuracy during the reasoning process, external Process Reward Models (PRMs) can be introduced during training and inference to provide fine-grained supervision. However, if misused, PRMs may distort the reasoning trajectory and lead to suboptimal or incorrect SQL generation.To address this challenge, we propose Reward-SQL, a framework that systematically explores how to incorporate PRMs into the Text-to-SQL reasoning process effectively. Our approach follows a "cold start, then PRM supervision" paradigm. Specifically, we first train the model to decompose SQL queries into structured stepwise reasoning chains using common table expressions (Chain-of-CTEs), establishing a strong and interpretable reasoning baseline. Then, we investigate four strategies for integrating PRMs, and find that combining PRM as an online training signal (GRPO) with PRM-guided inference (e.g., best-of-N sampling) yields the best results. Empirically, on the BIRD benchmark, Reward-SQL enables models supervised by a 7B PRM to achieve a 13.1% performance gain across various guidance strategies. Notably, our GRPO-aligned policy model based on Qwen2.5-Coder-7B-Instruct achieves 68.9% accuracy on the BIRD development set, outperforming all baseline methods under the same model size. These results demonstrate the effectiveness of Reward-SQL in leveraging reward-based supervision for Text-to-SQL reasoning. Our code is publicly available.
Improved Diffusion-based Generative Model with Better Adversarial Robustness
Feb 24, 2025Diffusion Probabilistic Models (DPMs) have achieved significant success in generative tasks. However, their training and sampling processes suffer from the issue of distribution mismatch. During the denoising process, the input data distributions differ between the training and inference stages, potentially leading to inaccurate data generation. To obviate this, we analyze the training objective of DPMs and theoretically demonstrate that this mismatch can be alleviated through Distributionally Robust Optimization (DRO), which is equivalent to performing robustness-driven Adversarial Training (AT) on DPMs. Furthermore, for the recently proposed Consistency Model (CM), which distills the inference process of the DPM, we prove that its training objective also encounters the mismatch issue. Fortunately, this issue can be mitigated by AT as well. Based on these insights, we propose to conduct efficient AT on both DPM and CM. Finally, extensive empirical studies validate the effectiveness of AT in diffusion-based models. The code is available at https://github.com/kugwzk/AT_Diff.