 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchoring Values in Temporal and Group Dimensions for Flow Matching Model Alignment
Dec 13, 2025Group Relative Policy Optimization (GRPO) has proven highly effective in enhancing the alignment capabilities of Large Language Models (LLMs). However, current adaptations of GRPO for the flow matching-based image generation neglect a foundational conflict between its core principles and the distinct dynamics of the visual synthesis process. This mismatch leads to two key limitations: (i) Uniformly applying a sparse terminal reward across all timesteps impairs temporal credit assignment, ignoring the differing criticality of generation phases from early structure formation to late-stage tuning. (ii) Exclusive reliance on relative, intra-group rewards causes the optimization signal to fade as training converges, leading to the optimization stagnation when reward diversity is entirely depleted. To address these limitations, we propose Value-Anchored Group Policy Optimization (VGPO), a framework that redefines value estimation across both temporal and group dimensions. Specifically, VGPO transforms the sparse terminal reward into dense, process-aware value estimates, enabling precise credit assignment by modeling the expected cumulative reward at each generative stage. Furthermore, VGPO replaces standard group normalization with a novel process enhanced by absolute values to maintain a stable optimization signal even as reward diversity declines. Extensive experiments on three benchmarks demonstrate that VGPO achieves state-of-the-art image quality while simultaneously improving task-specific accuracy, effectively mitigating reward hacking. Project webpage: https://yawen-shao.github.io/VGPO/.
Beyond Randomness: Understand the Order of the Noise in Diffusion
Nov 11, 2025
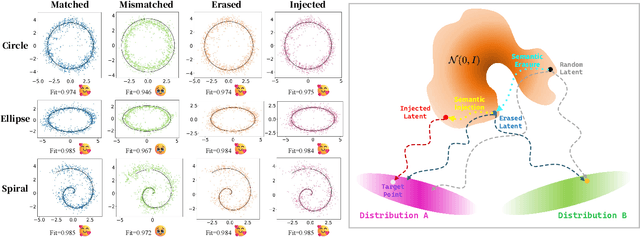


In text-driven content generation (T2C) diffusion model, semantic of generated content is mostly attributed to the process of text embedding and attention mechanism interaction. The initial noise of the generation process is typically characterized as a random element that contributes to the diversity of the generated content. Contrary to this view, this paper reveals that beneath the random surface of noise lies strong analyzable patterns. Specifically, this paper first conducts a comprehensive analysis of the impact of random noise on the model's generation. We found that noise not only contains rich semantic information, but also allows for the erasure of unwanted semantics from it in an extremely simple way based on information theory, and using the equivalence between the generation process of diffusion model and semantic injection to inject semantics into the cleaned noise. Then, we mathematically decipher these observations and propose a simple but efficient training-free and universal two-step "Semantic Erasure-Injection" process to modulate the initial noise in T2C diffusion model. Experimental results demonstrate that our method is consistently effective across various T2C models based on both DiT and UNet architectures and presents a novel perspective for optimizing the generation of diffusion model, providing a universal tool for consistent generation.
Latent Harmony: Synergistic Unified UHD Image Restoration via Latent Space Regularization and Controllable Refinement
Oct 09, 2025



Ultra-High Definition (UHD) image restoration faces a trade-off between computational efficiency and high-frequency detail retention. While Variational Autoencoders (VAEs) improve efficiency via latent-space processing, their Gaussian constraint often discards degradation-specific high-frequency information, hurting reconstruction fidelity. To overcome this, we propose Latent Harmony, a two-stage framework that redefines VAEs for UHD restoration by jointly regularizing the latent space and enforcing high-frequency-aware reconstruction.In Stage One, we introduce LH-VAE, which enhances semantic robustness through visual semantic constraints and progressive degradation perturbations, while latent equivariance strengthens high-frequency reconstruction.Stage Two jointly trains this refined VAE with a restoration model using High-Frequency Low-Rank Adaptation (HF-LoRA): an encoder LoRA guided by a fidelity-oriented high-frequency alignment loss to recover authentic details, and a decoder LoRA driven by a perception-oriented loss to synthesize realistic textures. Both LoRA modules are trained via alternating optimization with selective gradient propagation to preserve the pretrained latent structure.At inference, a tunable parameter {\alpha} enables flexible fidelity-perception trade-offs.Experiments show Latent Harmony achieves state-of-the-art performance across UHD and standard-resolution tasks, effectively balancing efficiency, perceptual quality, and reconstruction accuracy.
Fractional Spike Differential Equations Neural Network with Efficient Adjoint Parameters Training
Jul 22, 2025Spiking Neural Networks (SNNs) draw inspiration from biological neurons to create realistic models for brain-like computation, demonstrating effectiveness in processing temporal information with energy efficiency and biological realism. Most existing SNNs assume a single time constant for neuronal membrane voltage dynamics, modeled by first-order ordinary differential equations (ODEs) with Markovian characteristics. Consequently, the voltage state at any time depends solely on its immediate past value, potentially limiting network expressiveness. Real neurons, however, exhibit complex dynamics influenced by long-term correlations and fractal dendritic structures, suggesting non-Markovian behavior. Motivated by this, we propose the Fractional SPIKE Differential Equation neural network (fspikeDE), which captures long-term dependencies in membrane voltage and spike trains through fractional-order dynamics. These fractional dynamics enable more expressive temporal patterns beyond the capability of integer-order models. For efficient training of fspikeDE, we introduce a gradient descent algorithm that optimizes parameters by solving an augmented fractional-order ODE (FDE) backward in time using adjoint sensitivity methods. Extensive experiments on diverse image and graph datasets demonstrate that fspikeDE consistently outperforms traditional SNNs, achieving superior accuracy, comparable energy efficiency, reduced training memory usage, and enhanced robustness against noise. Our approach provides a novel open-sourced computational toolbox for fractional-order SNNs, widely applicable to various real-world tasks.
NTIRE 2025 Image Shadow Removal Challenge Report
Jun 18, 2025



This work examines the findings of the NTIRE 2025 Shadow Removal Challenge. A total of 306 participants have registered, with 17 teams successfully submitting their solutions during the final evaluation phase. Following the last two editions, this challenge had two evaluation tracks: one focusing on reconstruction fidelity and the other on visual perception through a user study. Both tracks were evaluated with images from the WSRD+ dataset, simulating interactions between self- and cast-shadows with a large number of diverse objects, textures, and materials.
AliTok: Towards Sequence Modeling Alignment between Tokenizer and Autoregressive Model
Jun 05, 2025Autoregressive image generation aims to predict the next token based on previous ones. However, existing image tokenizers encode tokens with bidirectional dependencies during the compression process, which hinders the effective modeling by autoregressive models. In this paper, we propose a novel Aligned Tokenizer (AliTok), which utilizes a causal decoder to establish unidirectional dependencies among encoded tokens, thereby aligning the token modeling approach between the tokenizer and autoregressive model. Furthermore, by incorporating prefix tokens and employing two-stage tokenizer training to enhance reconstruction consistency, AliTok achieves great reconstruction performance while being generation-friendly. On ImageNet-256 benchmark, using a standard decoder-only autoregressive model as the generator with only 177M parameters, AliTok achieves a gFID score of 1.50 and an IS of 305.9. When the parameter count is increased to 662M, AliTok achieves a gFID score of 1.35, surpassing the state-of-the-art diffusion method with 10x faster sampling speed. The code and weights are available at https://github.com/ali-vilab/alitok.
Fact-R1: Towards Explainable Video Misinformation Detection with Deep Reasoning
May 22, 2025The rapid spread of multimodal misinformation on social media has raised growing concerns, while research on video misinformation detection remains limited due to the lack of large-scale, diverse datasets. Existing methods often overfit to rigid templates and lack deep reasoning over deceptive content. To address these challenges, we introduce FakeVV, a large-scale benchmark comprising over 100,000 video-text pairs with fine-grained, interpretable annotations. In addition, we further propose Fact-R1, a novel framework that integrates deep reasoning with collaborative rule-based reinforcement learning. Fact-R1 is trained through a three-stage process: (1) misinformation long-Chain-of-Thought (CoT) instruction tuning, (2) preference alignment via Direct Preference Optimization (DPO), and (3) Group Relative Policy Optimization (GRPO) using a novel verifiable reward function. This enables Fact-R1 to exhibit emergent reasoning behaviors comparable to those observed in advanced text-based reinforcement learning systems, but in the more complex multimodal misinformation setting. Our work establishes a new paradigm for misinformation detection, bridging large-scale video understanding, reasoning-guided alignment, and interpretable verification.
PMQ-VE: Progressive Multi-Frame Quantization for Video Enhancement
May 18, 2025



Multi-frame video enhancement tasks aim to improve the spatial and temporal resolution and quality of video sequences by leveraging temporal information from multiple frames, which are widely used in streaming video processing, surveillance, and generation. Although numerous Transformer-based enhancement methods have achieved impressive performance, their computational and memory demands hinder deployment on edge devices. Quantization offers a practical solution by reducing the bit-width of weights and activations to improve efficiency. However, directly applying existing quantization methods to video enhancement tasks often leads to significant performance degradation and loss of fine details. This stems from two limitations: (a) inability to allocate varying representational capacity across frames, which results in suboptimal dynamic range adaptation; (b) over-reliance on full-precision teachers, which limits the learning of low-bit student models. To tackle these challenges, we propose a novel quantization method for video enhancement: Progressive Multi-Frame Quantization for Video Enhancement (PMQ-VE). This framework features a coarse-to-fine two-stage process: Backtracking-based Multi-Frame Quantization (BMFQ) and Progressive Multi-Teacher Distillation (PMTD). BMFQ utilizes a percentile-based initialization and iterative search with pruning and backtracking for robust clipping bounds. PMTD employs a progressive distillation strategy with both full-precision and multiple high-bit (INT) teachers to enhance low-bit models' capacity and quality. Extensive experiments demonstrate that our method outperforms existing approaches, achieving state-of-the-art performance across multiple tasks and benchmarks.The code will be made publicly available at: https://github.com/xiaoBIGfeng/PMQ-VE.
NTIRE 2025 Challenge on Event-Based Image Deblurring: Methods and Results
Apr 16, 2025This paper presents an overview of NTIRE 2025 the First Challenge on Event-Based Image Deblurring, detailing the proposed methodologies and corresponding results. The primary goal of the challenge is to design an event-based method that achieves high-quality image deblurring, with performance quantitatively assessed using Peak Signal-to-Noise Ratio (PSNR). Notably, there are no restrictions on computational complexity or model size. The task focuses on leveraging both events and images as inputs for single-image deblurring. A total of 199 participants registered, among whom 15 teams successfully submitted valid results, offering valuable insights into the current state of event-based image deblurring. We anticipate that this challenge will drive further advancements in event-based vision research.
Event Signal Filtering via Probability Flux Estimation
Apr 10, 2025Events offer a novel paradigm for capturing scene dynamics via asynchronous sensing, but their inherent randomness often leads to degraded signal quality. Event signal filtering is thus essential for enhancing fidelity by reducing this internal randomness and ensuring consistent outputs across diverse acquisition conditions. Unlike traditional time series that rely on fixed temporal sampling to capture steady-state behaviors, events encode transient dynamics through polarity and event intervals, making signal modeling significantly more complex. To address this, the theoretical foundation of event generation is revisited through the lens of diffusion processes. The state and process information within events is modeled as continuous probability flux at threshold boundaries of the underlying irradiance diffusion. Building on this insight, a generative, online filtering framework called Event Density Flow Filter (EDFilter) is introduced. EDFilter estimates event correlation by reconstructing the continuous probability flux from discrete events using nonparametric kernel smoothing, and then resamples filtered events from this flux. To optimize fidelity over time, spatial and temporal kernels are employed in a time-varying optimization framework. A fast recursive solver with O(1) complexity is proposed, leveraging state-space models and lookup tables for efficient likelihood computation. Furthermore, a new real-world benchmark Rotary Event Dataset (RED) is released, offering microsecond-level ground truth irradiance for full-reference event filtering evaluation. Extensive experiments validate EDFilter's performance across tasks like event filtering, super-resolution, and direct event-based blob tracking. Significant gains in downstream applications such as SLAM and video reconstruction underscore its robustness and effectiveness.