 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Randomness: Understand the Order of the Noise in Diffusion
Nov 11, 2025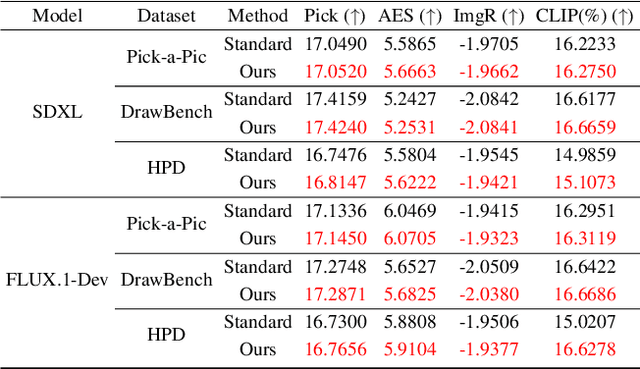
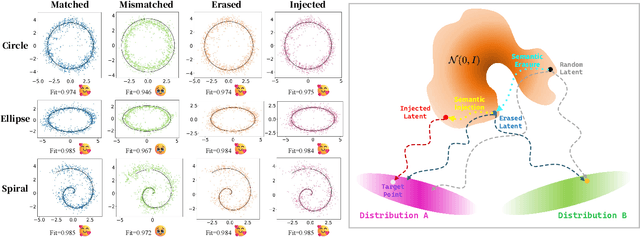


In text-driven content generation (T2C) diffusion model, semantic of generated content is mostly attributed to the process of text embedding and attention mechanism interaction. The initial noise of the generation process is typically characterized as a random element that contributes to the diversity of the generated content. Contrary to this view, this paper reveals that beneath the random surface of noise lies strong analyzable patterns. Specifically, this paper first conducts a comprehensive analysis of the impact of random noise on the model's generation. We found that noise not only contains rich semantic information, but also allows for the erasure of unwanted semantics from it in an extremely simple way based on information theory, and using the equivalence between the generation process of diffusion model and semantic injection to inject semantics into the cleaned noise. Then, we mathematically decipher these observations and propose a simple but efficient training-free and universal two-step "Semantic Erasure-Injection" process to modulate the initial noise in T2C diffusion model. Experimental results demonstrate that our method is consistently effective across various T2C models based on both DiT and UNet architectures and presents a novel perspective for optimizing the generation of diffusion model, providing a universal tool for consistent generation.
NeRF Inpainting with Geometric Diffusion Prior and Balanced Score Distillation
Nov 23, 2024



Recent advances in NeRF inpainting have leveraged pretrained diffusion models to enhance performance. However, these methods often yield suboptimal results due to their ineffective utilization of 2D diffusion priors. The limitations manifest in two critical aspects: the inadequate capture of geometric information by pretrained diffusion models and the suboptimal guidance provided by existing Score Distillation Sampling (SDS) methods. To address these problems, we introduce GB-NeRF, a novel framework that enhances NeRF inpainting through improved utilization of 2D diffusion priors. Our approach incorporates two key innovations: a fine-tuning strategy that simultaneously learns appearance and geometric priors and a specialized normal distillation loss that integrates these geometric priors into NeRF inpainting. We propose a technique called Balanced Score Distillation (BSD) that surpasses existing methods such as Score Distillation (SDS) and the improved version, Conditional Score Distillation (CSD). BSD offers improved inpainting quality in appearance and geometric aspects. Extensive experiments show that our method provides superior appearance fidelity and geometric consistency compared to existing approaches.
StableV2V: Stablizing Shape Consistency in Video-to-Video Editing
Nov 17, 2024Recent advancements of generative AI have significantly promoted content creation and editing, where prevailing studies further extend this exciting progress to video editing. In doing so, these studies mainly transfer the inherent motion patterns from the source videos to the edited ones, where results with inferior consistency to user prompts are often observed, due to the lack of particular alignments between the delivered motions and edited contents. To address this limitation, we present a shape-consistent video editing method, namely StableV2V, in this paper. Our method decomposes the entire editing pipeline into several sequential procedures, where it edits the first video frame, then establishes an alignment between the delivered motions and user prompts, and eventually propagates the edited contents to all other frames based on such alignment. Furthermore, we curate a testing benchmark, namely DAVIS-Edit, for a comprehensive evaluation of video editing, considering various types of prompts and difficulties. Experimental results and analyses illustrate the outperforming performance, visual consistency, and inference efficiency of our method compared to existing state-of-the-art studies.