 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 Challenge on Efficient Low Light Image Enhancement: Methods and Results
May 04, 2026This paper presents a comprehensive review of the NITRE 2026 Efficient Low Light Image Enhancement (E-LLIE) Challenge, highlighting the proposed solutions and final outcomes. This challenge focuses on mobile image enhancement under low-light conditions, aiming to design lightweight networks that improve enhancement quality while ensuring practical deployability under limited computational resources. A total of 207 participants registered, 27 teams submitted valid entries, and 17 teams ultimately provided valid factsheet. Based on these submissions, this paper provides a systematic evaluation of recent methods for E-LLIE, offering a comprehensive overview of state-of-the-art progress and demonstrating significant improvements in both performance and efficiency.
NTIRE 2026 Challenge on Bitstream-Corrupted Video Restoration: Methods and Results
Apr 09, 2026This paper reports on the NTIRE 2026 Challenge on Bitstream-Corrupted Video Restoration (BSCVR). The challenge aims to advance research on recovering visually coherent videos from corrupted bitstreams, whose decoding often produces severe spatial-temporal artifacts and content distortion. Built upon recent progress in bitstream-corrupted video recovery, the challenge provides a common benchmark for evaluating restoration methods under realistic corruption settings. We describe the dataset, evaluation protocol, and participating methods, and summarize the final results and main technical trends. The challenge highlights the difficulty of this emerging task and provides useful insights for future research on robust video restoration under practical bitstream corruption.
NTIRE 2025 Image Shadow Removal Challenge Report
Jun 18, 2025



This work examines the findings of the NTIRE 2025 Shadow Removal Challenge. A total of 306 participants have registered, with 17 teams successfully submitting their solutions during the final evaluation phase. Following the last two editions, this challenge had two evaluation tracks: one focusing on reconstruction fidelity and the other on visual perception through a user study. Both tracks were evaluated with images from the WSRD+ dataset, simulating interactions between self- and cast-shadows with a large number of diverse objects, textures, and materials.
Steering Prediction via a Multi-Sensor System for Autonomous Racing
Sep 28, 2024



Autonomous racing has rapidly gained research attention. Traditionally, racing cars rely on 2D LiDAR as their primary visual system. In this work, we explore the integration of an event camera with the existing system to provide enhanced temporal information. Our goal is to fuse the 2D LiDAR data with event data in an end-to-end learning framework for steering prediction, which is crucial for autonomous racing. To the best of our knowledge, this is the first study addressing this challenging research topic. We start by creating a multisensor dataset specifically for steering prediction. Using this dataset, we establish a benchmark by evaluating various SOTA fusion methods. Our observations reveal that existing methods often incur substantial computational costs. To address this, we apply low-rank techniques to propose a novel, efficient, and effective fusion design. We introduce a new fusion learning policy to guide the fusion process, enhancing robustness against misalignment. Our fusion architecture provides better steering prediction than LiDAR alone, significantly reducing the RMSE from 7.72 to 1.28. Compared to the second-best fusion method, our work represents only 11% of the learnable parameters while achieving better accuracy. The source code, dataset, and benchmark will be released to promote future research.
Towards a Generalist and Blind RGB-X Tracker
May 28, 2024With the emergence of a single large model capable of successfully solving a multitude of tasks in NLP, there has been growing research interest in achieving similar goals in computer vision. On the one hand, most of these generic models, referred to as generalist vision models, aim at producing unified outputs serving different tasks. On the other hand, some existing models aim to combine different input types (aka data modalities), which are then processed by a single large model. Yet, this step of combination remains specialized, which falls short of serving the initial ambition. In this paper, we showcase that such specialization (during unification) is unnecessary, in the context of RGB-X video object tracking. Our single model tracker, termed XTrack, can remain blind to any modality X during inference time. Our tracker employs a mixture of modal experts comprising those dedicated to shared commonality and others capable of flexibly performing reasoning conditioned on input modality. Such a design ensures the unification of input modalities towards a common latent space, without weakening the modality-specific information representation. With this idea, our training process is extremely simple, integrating multi-label classification loss with a routing function, thereby effectively aligning and unifying all modalities together, even from only paired data. Thus, during inference, we can adopt any modality without relying on the inductive bias of the modal prior and achieve generalist performance. Without any bells and whistles, our generalist and blind tracker can achieve competitive performance compared to well-established modal-specific models on 5 benchmarks across 3 auxiliary modalities, covering commonly used depth, thermal, and event data.
Object Segmentation by Mining Cross-Modal Semantics
May 23, 2023



Multi-sensor clues have shown promise for object segmentation, but inherent noise in each sensor, as well as the calibration error in practice, may bias the segmentation accuracy. In this paper, we propose a novel approach by mining the Cross-Modal Semantics to guide the fusion and decoding of multimodal features, with the aim of controlling the modal contribution based on relative entropy. We explore semantics among the multimodal inputs in two aspects: the modality-shared consistency and the modality-specific variation. Specifically, we propose a novel network, termed XMSNet, consisting of (1) all-round attentive fusion (AF), (2) coarse-to-fine decoder (CFD), and (3) cross-layer self-supervision. On the one hand, the AF block explicitly dissociates the shared and specific representation and learns to weight the modal contribution by adjusting the proportion, region, and pattern, depending upon the quality. On the other hand, our CFD initially decodes the shared feature and then refines the output through specificity-aware querying. Further, we enforce semantic consistency across the decoding layers to enable interaction across network hierarchies, improving feature discriminability. Exhaustive comparison on eleven datasets with depth or thermal clues, and on two challenging tasks, namely salient and camouflage object segmentation, validate our effectiveness in terms of both performance and robustness.
DSEC-MOS: Segment Any Moving Object with Moving Ego Vehicle
Apr 28, 2023



Moving Object Segmentation (MOS), a crucial task in computer vision, has numerous applications such as surveillance, autonomous driving, and video analytics. Existing datasets for moving object segmentation mainly focus on RGB or Lidar videos, but lack additional event information that can enhance the understanding of dynamic scenes. To address this limitation, we propose a novel dataset, called DSEC-MOS. Our dataset includes frames captured by RGB cameras embedded on moving vehicules and incorporates event data, which provide high temporal resolution and low-latency information about changes in the scenes. To generate accurate segmentation mask annotations for moving objects, we apply the recently emerged large model SAM - Segment Anything Model - with moving object bounding boxes from DSEC-MOD serving as prompts and calibrated RGB frames, then further revise the results. Our DSEC-MOS dataset contains in total 16 sequences (13314 images). To the best of our knowledge, DSEC-MOS is also the first moving object segmentation dataset that includes event camera in autonomous driving. Project Page: https://github.com/ZZY-Zhou/DSEC-MOS.
RGB-Event Fusion for Moving Object Detection in Autonomous Driving
Sep 17, 2022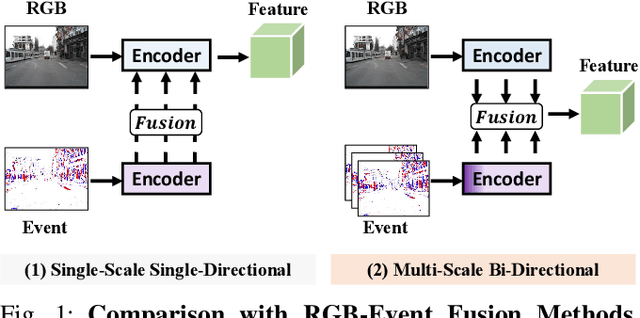
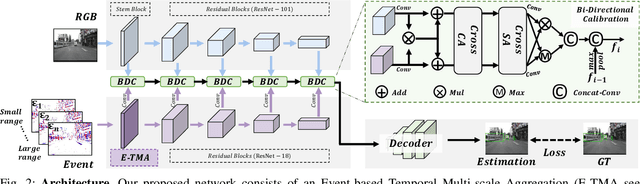
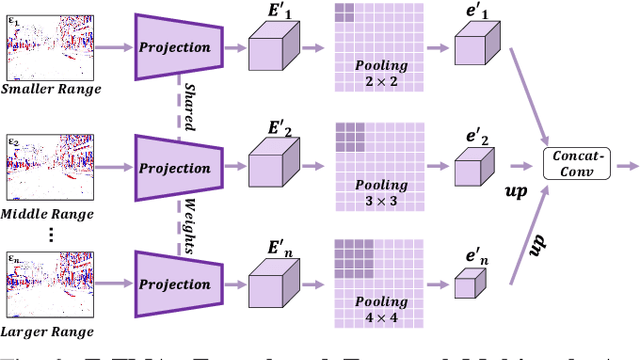
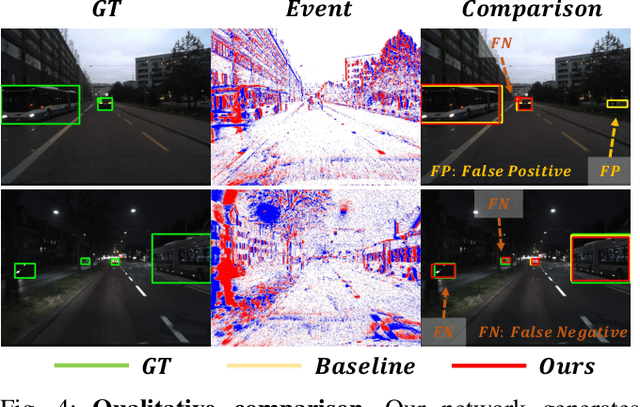
Moving Object Detection (MOD) is a critical vision task for successfully achieving safe autonomous driving. Despite plausible results of deep learning methods, most existing approaches are only frame-based and may fail to reach reasonable performance when dealing with dynamic traffic participants. Recent advances in sensor technologies, especially the Event camera, can naturally complement the conventional camera approach to better model moving objects. However, event-based works often adopt a pre-defined time window for event representation, and simply integrate it to estimate image intensities from events, neglecting much of the rich temporal information from the available asynchronous events. Therefore, from a new perspective, we propose RENet, a novel RGB-Event fusion Network, that jointly exploits the two complementary modalities to achieve more robust MOD under challenging scenarios for autonomous driving. Specifically, we first design a temporal multi-scale aggregation module to fully leverage event frames from both the RGB exposure time and larger intervals. Then we introduce a bi-directional fusion module to attentively calibrate and fuse multi-modal features. To evaluate the performance of our network, we carefully select and annotate a sub-MOD dataset from the commonly used DSEC dataset. Extensive experiments demonstrate that our proposed method performs significantly better than the state-of-the-art RGB-Event fusion alternatives.