 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack on Track: Aligning Rewards and States for Reasoning in Diffusion Large Language Models
Jun 07, 2026Reinforcement learning (RL) holds immense promise for enhancing the reasoning capabilities of diffusion large language models (dLLMs). However, progress is fundamentally constrained by a dual misalignment between authentic generation trajectory and the gradient update process: (i) Process-reward misalignment. Sparse, terminal rewards are indiscriminately assigned to all intermediate steps of the generation process, failing to provide discriminative credit assignment. (ii) State-trajectory misalignment. Policy updates are often diverted toward artificial, out-of-trajectory states, squandering gradients on less informative samples. To address these limitations, we introduce Process Aligned Policy Optimization (PAPO), a novel framework that holistically aligns the RL update with the dLLM's generative trajectory via Step-Aware Process Rewards (SPR) that transform sparse terminal rewards into dense, step-wise credit, and Entropy-Guided Historical Re-enactment (EHR) that replays authentic trajectories at high-uncertainty steps. Extensive experiments on four benchmarks demonstrate that PAPO significantly outperforms baselines, achieving gains of up to 4.5% on GSM8K, 4.8% on MATH500, 42.2% on Countdown and 16.1% on Sudoku.
Anchoring Values in Temporal and Group Dimensions for Flow Matching Model Alignment
Dec 13, 2025Group Relative Policy Optimization (GRPO) has proven highly effective in enhancing the alignment capabilities of Large Language Models (LLMs). However, current adaptations of GRPO for the flow matching-based image generation neglect a foundational conflict between its core principles and the distinct dynamics of the visual synthesis process. This mismatch leads to two key limitations: (i) Uniformly applying a sparse terminal reward across all timesteps impairs temporal credit assignment, ignoring the differing criticality of generation phases from early structure formation to late-stage tuning. (ii) Exclusive reliance on relative, intra-group rewards causes the optimization signal to fade as training converges, leading to the optimization stagnation when reward diversity is entirely depleted. To address these limitations, we propose Value-Anchored Group Policy Optimization (VGPO), a framework that redefines value estimation across both temporal and group dimensions. Specifically, VGPO transforms the sparse terminal reward into dense, process-aware value estimates, enabling precise credit assignment by modeling the expected cumulative reward at each generative stage. Furthermore, VGPO replaces standard group normalization with a novel process enhanced by absolute values to maintain a stable optimization signal even as reward diversity declines. Extensive experiments on three benchmarks demonstrate that VGPO achieves state-of-the-art image quality while simultaneously improving task-specific accuracy, effectively mitigating reward hacking. Project webpage: https://yawen-shao.github.io/VGPO/.
GREAT: Geometry-Intention Collaborative Inference for Open-Vocabulary 3D Object Affordance Grounding
Nov 29, 2024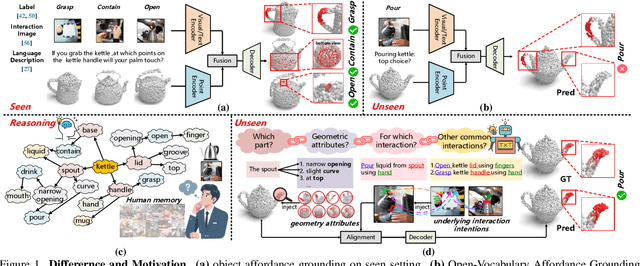
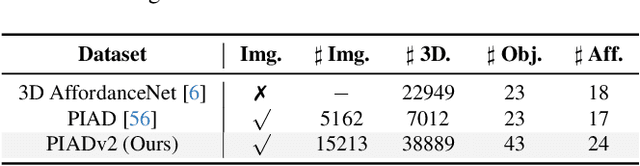


Open-Vocabulary 3D object affordance grounding aims to anticipate ``action possibilities'' regions on 3D objects with arbitrary instructions, which is crucial for robots to generically perceive real scenarios and respond to operational changes. Existing methods focus on combining images or languages that depict interactions with 3D geometries to introduce external interaction priors. However, they are still vulnerable to a limited semantic space by failing to leverage implied invariant geometries and potential interaction intentions. Normally, humans address complex tasks through multi-step reasoning and respond to diverse situations by leveraging associative and analogical thinking. In light of this, we propose GREAT (GeometRy-intEntion collAboraTive inference) for Open-Vocabulary 3D Object Affordance Grounding, a novel framework that mines the object invariant geometry attributes and performs analogically reason in potential interaction scenarios to form affordance knowledge, fully combining the knowledge with both geometries and visual contents to ground 3D object affordance. Besides, we introduce the Point Image Affordance Dataset v2 (PIADv2), the largest 3D object affordance dataset at present to support the task. Extensive experiments demonstrate the effectiveness and superiority of GREAT. Code and dataset are available at project.