 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLA-R1: Enhancing Reasoning in Vision-Language-Action Models
Oct 02, 2025Vision-Language-Action (VLA) models aim to unify perception, language understanding, and action generation, offering strong cross-task and cross-scene generalization with broad impact on embodied AI. However, current VLA models often lack explicit step-by-step reasoning, instead emitting final actions without considering affordance constraints or geometric relations. Their post-training pipelines also rarely reinforce reasoning quality, relying primarily on supervised fine-tuning with weak reward design. To address these challenges, we present VLA-R1, a reasoning-enhanced VLA that integrates Reinforcement Learning from Verifiable Rewards (RLVR) with Group Relative Policy Optimization (GRPO) to systematically optimize both reasoning and execution. Specifically, we design an RLVR-based post-training strategy with verifiable rewards for region alignment, trajectory consistency, and output formatting, thereby strengthening reasoning robustness and execution accuracy. Moreover, we develop VLA-CoT-13K, a high-quality dataset that provides chain-of-thought supervision explicitly aligned with affordance and trajectory annotations. Furthermore, extensive evaluations on in-domain, out-of-domain, simulation, and real-robot platforms demonstrate that VLA-R1 achieves superior generalization and real-world performance compared to prior VLA methods. We plan to release the model, code, and dataset following the publication of this work. Code: https://github.com/GigaAI-research/VLA-R1. Website: https://gigaai-research.github.io/VLA-R1.
Erased, But Not Forgotten: Erased Rectified Flow Transformers Still Remain Unsafe Under Concept Attack
Oct 01, 2025Recent advances in text-to-image (T2I) diffusion models have enabled impressive generative capabilities, but they also raise significant safety concerns due to the potential to produce harmful or undesirable content. While concept erasure has been explored as a mitigation strategy, most existing approaches and corresponding attack evaluations are tailored to Stable Diffusion (SD) and exhibit limited effectiveness when transferred to next-generation rectified flow transformers such as Flux. In this work, we present ReFlux, the first concept attack method specifically designed to assess the robustness of concept erasure in the latest rectified flow-based T2I framework. Our approach is motivated by the observation that existing concept erasure techniques, when applied to Flux, fundamentally rely on a phenomenon known as attention localization. Building on this insight, we propose a simple yet effective attack strategy that specifically targets this property. At its core, a reverse-attention optimization strategy is introduced to effectively reactivate suppressed signals while stabilizing attention. This is further reinforced by a velocity-guided dynamic that enhances the robustness of concept reactivation by steering the flow matching process, and a consistency-preserving objective that maintains the global layout and preserves unrelated content. Extensive experiments consistently demonstrate the effectiveness and efficiency of the proposed attack method, establishing a reliable benchmark for evaluating the robustness of concept erasure strategies in rectified flow transformers.
EMMA: Generalizing Real-World Robot Manipulation via Generative Visual Transfer
Sep 26, 2025
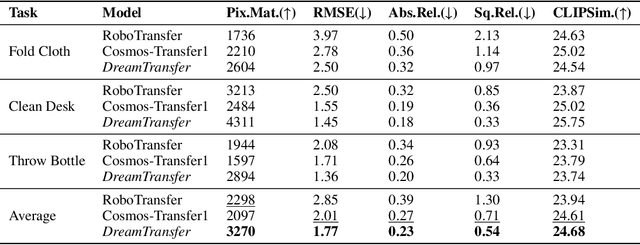
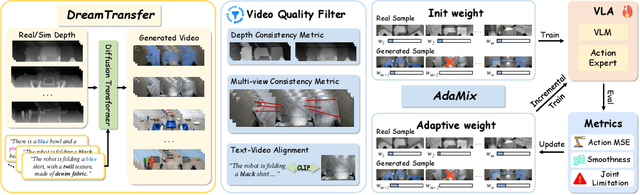
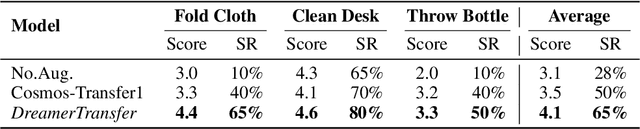
Vision-language-action (VLA) models increasingly rely on diverse training data to achieve robust generalization. However, collecting large-scale real-world robot manipulation data across varied object appearances and environmental conditions remains prohibitively time-consuming and expensive. To overcome this bottleneck, we propose Embodied Manipulation Media Adaptation (EMMA), a VLA policy enhancement framework that integrates a generative data engine with an effective training pipeline. We introduce DreamTransfer, a diffusion Transformer-based framework for generating multi-view consistent, geometrically grounded embodied manipulation videos. DreamTransfer enables text-controlled visual editing of robot videos, transforming foreground, background, and lighting conditions without compromising 3D structure or geometrical plausibility. Furthermore, we explore hybrid training with real and generated data, and introduce AdaMix, a hard-sample-aware training strategy that dynamically reweights training batches to focus optimization on perceptually or kinematically challenging samples. Extensive experiments show that videos generated by DreamTransfer significantly outperform prior video generation methods in multi-view consistency, geometric fidelity, and text-conditioning accuracy. Crucially, VLAs trained with generated data enable robots to generalize to unseen object categories and novel visual domains using only demonstrations from a single appearance. In real-world robotic manipulation tasks with zero-shot visual domains, our approach achieves over a 200% relative performance gain compared to training on real data alone, and further improves by 13% with AdaMix, demonstrating its effectiveness in boosting policy generalization.
MimicDreamer: Aligning Human and Robot Demonstrations for Scalable VLA Training
Sep 26, 2025



Vision Language Action (VLA) models derive their generalization capability from diverse training data, yet collecting embodied robot interaction data remains prohibitively expensive. In contrast, human demonstration videos are far more scalable and cost-efficient to collect, and recent studies confirm their effectiveness in training VLA models. However, a significant domain gap persists between human videos and robot-executed videos, including unstable camera viewpoints, visual discrepancies between human hands and robotic arms, and differences in motion dynamics. To bridge this gap, we propose MimicDreamer, a framework that turns fast, low-cost human demonstrations into robot-usable supervision by jointly aligning vision, viewpoint, and actions to directly support policy training. For visual alignment, we propose H2R Aligner, a video diffusion model that generates high-fidelity robot demonstration videos by transferring motion from human manipulation footage. For viewpoint stabilization, EgoStabilizer is proposed, which canonicalizes egocentric videos via homography and inpaints occlusions and distortions caused by warping. For action alignment, we map human hand trajectories to the robot frame and apply a constrained inverse kinematics solver to produce feasible, low-jitter joint commands with accurate pose tracking. Empirically, VLA models trained purely on our synthesized human-to-robot videos achieve few-shot execution on real robots. Moreover, scaling training with human data significantly boosts performance compared to models trained solely on real robot data; our approach improves the average success rate by 14.7\% across six representative manipulation tasks.
EgoDemoGen: Novel Egocentric Demonstration Generation Enables Viewpoint-Robust Manipulation
Sep 26, 2025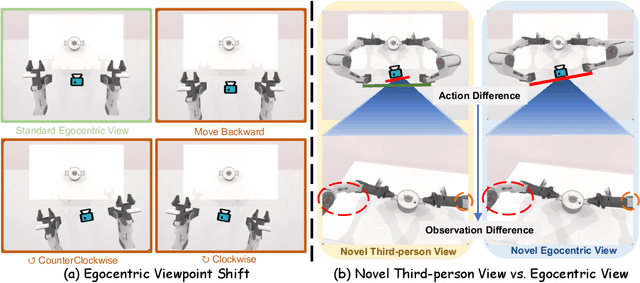

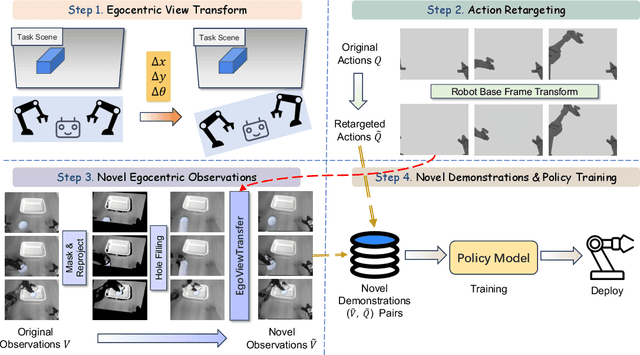
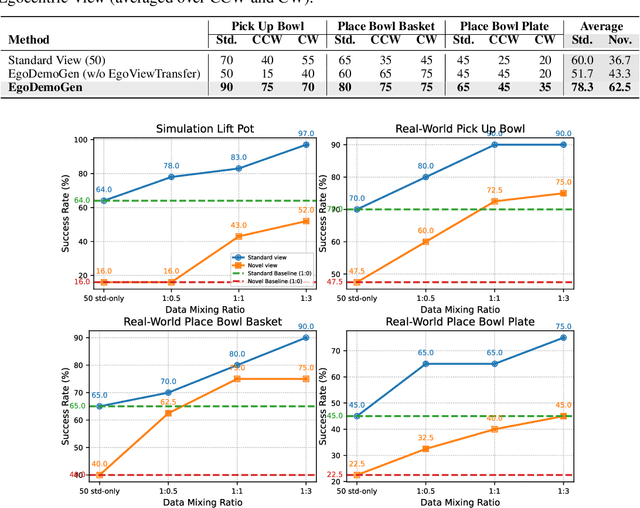
Imitation learning based policies perform well in robotic manipulation, but they often degrade under *egocentric viewpoint shifts* when trained from a single egocentric viewpoint. To address this issue, we present **EgoDemoGen**, a framework that generates *paired* novel egocentric demonstrations by retargeting actions in the novel egocentric frame and synthesizing the corresponding egocentric observation videos with proposed generative video repair model **EgoViewTransfer**, which is conditioned by a novel-viewpoint reprojected scene video and a robot-only video rendered from the retargeted joint actions. EgoViewTransfer is finetuned from a pretrained video generation model using self-supervised double reprojection strategy. We evaluate EgoDemoGen on both simulation (RoboTwin2.0) and real-world robot. After training with a mixture of EgoDemoGen-generated novel egocentric demonstrations and original standard egocentric demonstrations, policy success rate improves **absolutely** by **+17.0%** for standard egocentric viewpoint and by **+17.7%** for novel egocentric viewpoints in simulation. On real-world robot, the **absolute** improvements are **+18.3%** and **+25.8%**. Moreover, performance continues to improve as the proportion of EgoDemoGen-generated demonstrations increases, with diminishing returns. These results demonstrate that EgoDemoGen provides a practical route to egocentric viewpoint-robust robotic manipulation.
ReconDreamer-RL: Enhancing Reinforcement Learning via Diffusion-based Scene Reconstruction
Aug 11, 2025



Reinforcement learning for training end-to-end autonomous driving models in closed-loop simulations is gaining growing attention. However, most simulation environments differ significantly from real-world conditions, creating a substantial simulation-to-reality (sim2real) gap. To bridge this gap, some approaches utilize scene reconstruction techniques to create photorealistic environments as a simulator. While this improves realistic sensor simulation, these methods are inherently constrained by the distribution of the training data, making it difficult to render high-quality sensor data for novel trajectories or corner case scenarios. Therefore, we propose ReconDreamer-RL, a framework designed to integrate video diffusion priors into scene reconstruction to aid reinforcement learning, thereby enhancing end-to-end autonomous driving training. Specifically, in ReconDreamer-RL, we introduce ReconSimulator, which combines the video diffusion prior for appearance modeling and incorporates a kinematic model for physical modeling, thereby reconstructing driving scenarios from real-world data. This narrows the sim2real gap for closed-loop evaluation and reinforcement learning. To cover more corner-case scenarios, we introduce the Dynamic Adversary Agent (DAA), which adjusts the trajectories of surrounding vehicles relative to the ego vehicle, autonomously generating corner-case traffic scenarios (e.g., cut-in). Finally, the Cousin Trajectory Generator (CTG) is proposed to address the issue of training data distribution, which is often biased toward simple straight-line movements. Experiments show that ReconDreamer-RL improves end-to-end autonomous driving training, outperforming imitation learning methods with a 5x reduction in the Collision Ratio.
Humanoid Occupancy: Enabling A Generalized Multimodal Occupancy Perception System on Humanoid Robots
Jul 27, 2025Humanoid robot technology is advancing rapidly, with manufacturers introducing diverse heterogeneous visual perception modules tailored to specific scenarios. Among various perception paradigms, occupancy-based representation has become widely recognized as particularly suitable for humanoid robots, as it provides both rich semantic and 3D geometric information essential for comprehensive environmental understanding. In this work, we present Humanoid Occupancy, a generalized multimodal occupancy perception system that integrates hardware and software components, data acquisition devices, and a dedicated annotation pipeline. Our framework employs advanced multi-modal fusion techniques to generate grid-based occupancy outputs encoding both occupancy status and semantic labels, thereby enabling holistic environmental understanding for downstream tasks such as task planning and navigation. To address the unique challenges of humanoid robots, we overcome issues such as kinematic interference and occlusion, and establish an effective sensor layout strategy. Furthermore, we have developed the first panoramic occupancy dataset specifically for humanoid robots, offering a valuable benchmark and resource for future research and development in this domain. The network architecture incorporates multi-modal feature fusion and temporal information integration to ensure robust perception. Overall, Humanoid Occupancy delivers effective environmental perception for humanoid robots and establishes a technical foundation for standardizing universal visual modules, paving the way for the widespread deployment of humanoid robots in complex real-world scenarios.
WonderFree: Enhancing Novel View Quality and Cross-View Consistency for 3D Scene Exploration
Jun 25, 2025Interactive 3D scene generation from a single image has gained significant attention due to its potential to create immersive virtual worlds. However, a key challenge in current 3D generation methods is the limited explorability, which cannot render high-quality images during larger maneuvers beyond the original viewpoint, particularly when attempting to move forward into unseen areas. To address this challenge, we propose WonderFree, the first model that enables users to interactively generate 3D worlds with the freedom to explore from arbitrary angles and directions. Specifically, we decouple this challenge into two key subproblems: novel view quality, which addresses visual artifacts and floating issues in novel views, and cross-view consistency, which ensures spatial consistency across different viewpoints. To enhance rendering quality in novel views, we introduce WorldRestorer, a data-driven video restoration model designed to eliminate floaters and artifacts. In addition, a data collection pipeline is presented to automatically gather training data for WorldRestorer, ensuring it can handle scenes with varying styles needed for 3D scene generation. Furthermore, to improve cross-view consistency, we propose ConsistView, a multi-view joint restoration mechanism that simultaneously restores multiple perspectives while maintaining spatiotemporal coherence. Experimental results demonstrate that WonderFree not only enhances rendering quality across diverse viewpoints but also significantly improves global coherence and consistency. These improvements are confirmed by CLIP-based metrics and a user study showing a 77.20% preference for WonderFree over WonderWorld enabling a seamless and immersive 3D exploration experience. The code, model, and data will be publicly available.
GigaVideo-1: Advancing Video Generation via Automatic Feedback with 4 GPU-Hours Fine-Tuning
Jun 12, 2025



Recent progress in diffusion models has greatly enhanced video generation quality, yet these models still require fine-tuning to improve specific dimensions like instance preservation, motion rationality, composition, and physical plausibility. Existing fine-tuning approaches often rely on human annotations and large-scale computational resources, limiting their practicality. In this work, we propose GigaVideo-1, an efficient fine-tuning framework that advances video generation without additional human supervision. Rather than injecting large volumes of high-quality data from external sources, GigaVideo-1 unlocks the latent potential of pre-trained video diffusion models through automatic feedback. Specifically, we focus on two key aspects of the fine-tuning process: data and optimization. To improve fine-tuning data, we design a prompt-driven data engine that constructs diverse, weakness-oriented training samples. On the optimization side, we introduce a reward-guided training strategy, which adaptively weights samples using feedback from pre-trained vision-language models with a realism constraint. We evaluate GigaVideo-1 on the VBench-2.0 benchmark using Wan2.1 as the baseline across 17 evaluation dimensions. Experiments show that GigaVideo-1 consistently improves performance on almost all the dimensions with an average gain of about 4% using only 4 GPU-hours. Requiring no manual annotations and minimal real data, GigaVideo-1 demonstrates both effectiveness and efficiency. Code, model, and data will be publicly available.
Motion-R1: Chain-of-Thought Reasoning and Reinforcement Learning for Human Motion Generation
Jun 12, 2025Recent advances in large language models, especially in natural language understanding and reasoning, have opened new possibilities for text-to-motion generation. Although existing approaches have made notable progress in semantic alignment and motion synthesis, they often rely on end-to-end mapping strategies that fail to capture deep linguistic structures and logical reasoning. Consequently, generated motions tend to lack controllability, consistency, and diversity. To address these limitations, we propose Motion-R1, a unified motion-language modeling framework that integrates a Chain-of-Thought mechanism. By explicitly decomposing complex textual instructions into logically structured action paths, Motion-R1 provides high-level semantic guidance for motion generation, significantly enhancing the model's ability to interpret and execute multi-step, long-horizon, and compositionally rich commands. To train our model, we adopt Group Relative Policy Optimization, a reinforcement learning algorithm designed for large models, which leverages motion quality feedback to optimize reasoning chains and motion synthesis jointly. Extensive experiments across multiple benchmark datasets demonstrate that Motion-R1 achieves competitive or superior performance compared to state-of-the-art methods, particularly in scenarios requiring nuanced semantic understanding and long-term temporal coherence. The code, model and data will be publicly available.