 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-Aware Reduction Framework: Towards Efficient and Faithful Visual State Space Models
Jun 18, 2026Mamba demonstrates strong efficiency in modeling long visual sequences. However, when token reduction is applied to structurally enhanced Mamba variants, these models exhibit a severe performance collapse. We attribute this degradation to the spatially agnostic nature of existing reduction methods, which violate the two-dimensional structural premise required by the selective scanning mechanism. In this work, we propose STORM, a spatial-aware token reduction framework designed to maintain structural integrity throughout the compression process. STORM reformulates reduction into a structured operation on spatial units, enforcing localized constraints to maintain both grid topology and neighborhood coherence. As a plug-and-play module, STORM equips existing reduction pipelines with explicit spatial awareness without any training. Empirical results demonstrate that STORM achieves state-of-the-art pruning accuracy across diverse vision Mamba backbones under training-free settings. Notably, STORM delivers a substantial accuracy recovery on VMamba, outperforming prior methods by up to 63.3\% in top-1 accuracy. Meanwhile, STORM incurs only a 1.0\% accuracy drop on PlainMamba, achieving performance comparable to ViT.
ViVa: A Video-Generative Value Model for Robot Reinforcement Learning
Apr 09, 2026Vision-language-action (VLA) models have advanced robot manipulation through large-scale pretraining, but real-world deployment remains challenging due to partial observability and delayed feedback. Reinforcement learning addresses this via value functions, which assess task progress and guide policy improvement. However, existing value models built on vision-language models (VLMs) struggle to capture temporal dynamics, undermining reliable value estimation in long-horizon tasks. In this paper, we propose ViVa, a video-generative value model that repurposes a pretrained video generator for value estimation. Taking the current observation and robot proprioception as input, ViVa jointly predicts future proprioception and a scalar value for the current state. By leveraging the spatiotemporal priors of a pretrained video generator, our approach grounds value estimation in anticipated embodiment dynamics, moving beyond static snapshots to intrinsically couple value with foresight. Integrated into RECAP, ViVa delivers substantial improvements on real-world box assembly. Qualitative analysis across all three tasks confirms that ViVa produces more reliable value signals, accurately reflecting task progress. By leveraging spatiotemporal priors from video corpora, ViVa also generalizes to novel objects, highlighting the promise of video-generative models for value estimation.
GigaWorld-Policy: An Efficient Action-Centered World--Action Model
Mar 18, 2026World-Action Models (WAM) initialized from pre-trained video generation backbones have demonstrated remarkable potential for robot policy learning. However, existing approaches face two critical bottlenecks that hinder performance and deployment. First, jointly reasoning over future visual dynamics and corresponding actions incurs substantial inference overhead. Second, joint modeling often entangles visual and motion representations, making motion prediction accuracy heavily dependent on the quality of future video forecasts. To address these issues, we introduce GigaWorld-Policy, an action-centered WAM that learns 2D pixel-action dynamics while enabling efficient action decoding, with optional video generation. Specifically, we formulate policy training into two coupled components: the model predicts future action sequences conditioned on the current observation, and simultaneously generates future videos conditioned on the predicted actions and the same observation. The policy is supervised by both action prediction and video generation, providing richer learning signals and encouraging physically plausible actions through visual-dynamics constraints. With a causal design that prevents future-video tokens from influencing action tokens, explicit future-video generation is optional at inference time, allowing faster action prediction during deployment. To support this paradigm, we curate a diverse, large-scale robot dataset to pre-train an action-centered video generation model, which is then adapted as the backbone for robot policy learning. Experimental results on real-world robotic platforms show that GigaWorld-Policy runs 9x faster than the leading WAM baseline, Motus, while improving task success rates by 7%. Moreover, compared with pi-0.5, GigaWorld-Policy improves performance by 95% on RoboTwin 2.0.
GigaBrain-0.5M*: a VLA That Learns From World Model-Based Reinforcement Learning
Feb 12, 2026Vision-language-action (VLA) models that directly predict multi-step action chunks from current observations face inherent limitations due to constrained scene understanding and weak future anticipation capabilities. In contrast, video world models pre-trained on web-scale video corpora exhibit robust spatiotemporal reasoning and accurate future prediction, making them a natural foundation for enhancing VLA learning. Therefore, we propose \textit{GigaBrain-0.5M*}, a VLA model trained via world model-based reinforcement learning. Built upon \textit{GigaBrain-0.5}, which is pre-trained on over 10,000 hours of robotic manipulation data, whose intermediate version currently ranks first on the international RoboChallenge benchmark. \textit{GigaBrain-0.5M*} further integrates world model-based reinforcement learning via \textit{RAMP} (Reinforcement leArning via world Model-conditioned Policy) to enable robust cross-task adaptation. Empirical results demonstrate that \textit{RAMP} achieves substantial performance gains over the RECAP baseline, yielding improvements of approximately 30\% on challenging tasks including \texttt{Laundry Folding}, \texttt{Box Packing}, and \texttt{Espresso Preparation}. Critically, \textit{GigaBrain-0.5M$^*$} exhibits reliable long-horizon execution, consistently accomplishing complex manipulation tasks without failure as validated by real-world deployment videos on our \href{https://gigabrain05m.github.io}{project page}.
Deploying Models to Non-participating Clients in Federated Learning without Fine-tuning: A Hypernetwork-based Approach
Aug 18, 2025Federated Learning (FL) has emerged as a promising paradigm for privacy-preserving collaborative learning, yet data heterogeneity remains a critical challenge. While existing methods achieve progress in addressing data heterogeneity for participating clients, they fail to generalize to non-participating clients with in-domain distribution shifts and resource constraints. To mitigate this issue, we present HyperFedZero, a novel method that dynamically generates specialized models via a hypernetwork conditioned on distribution-aware embeddings. Our approach explicitly incorporates distribution-aware inductive biases into the model's forward pass, extracting robust distribution embeddings using a NoisyEmbed-enhanced extractor with a Balancing Penalty, effectively preventing feature collapse. The hypernetwork then leverages these embeddings to generate specialized models chunk-by-chunk for non-participating clients, ensuring adaptability to their unique data distributions. Extensive experiments on multiple datasets and models demonstrate HyperFedZero's remarkable performance, surpassing competing methods consistently with minimal computational, storage, and communication overhead. Moreover, ablation studies and visualizations further validate the necessity of each component, confirming meaningful adaptations and validating the effectiveness of HyperFedZero.
GigaVideo-1: Advancing Video Generation via Automatic Feedback with 4 GPU-Hours Fine-Tuning
Jun 12, 2025



Recent progress in diffusion models has greatly enhanced video generation quality, yet these models still require fine-tuning to improve specific dimensions like instance preservation, motion rationality, composition, and physical plausibility. Existing fine-tuning approaches often rely on human annotations and large-scale computational resources, limiting their practicality. In this work, we propose GigaVideo-1, an efficient fine-tuning framework that advances video generation without additional human supervision. Rather than injecting large volumes of high-quality data from external sources, GigaVideo-1 unlocks the latent potential of pre-trained video diffusion models through automatic feedback. Specifically, we focus on two key aspects of the fine-tuning process: data and optimization. To improve fine-tuning data, we design a prompt-driven data engine that constructs diverse, weakness-oriented training samples. On the optimization side, we introduce a reward-guided training strategy, which adaptively weights samples using feedback from pre-trained vision-language models with a realism constraint. We evaluate GigaVideo-1 on the VBench-2.0 benchmark using Wan2.1 as the baseline across 17 evaluation dimensions. Experiments show that GigaVideo-1 consistently improves performance on almost all the dimensions with an average gain of about 4% using only 4 GPU-hours. Requiring no manual annotations and minimal real data, GigaVideo-1 demonstrates both effectiveness and efficiency. Code, model, and data will be publicly available.
GPS: Distilling Compact Memories via Grid-based Patch Sampling for Efficient Online Class-Incremental Learning
Apr 15, 2025Online class-incremental learning aims to enable models to continuously adapt to new classes with limited access to past data, while mitigating catastrophic forgetting. Replay-based methods address this by maintaining a small memory buffer of previous samples, achieving competitive performance. For effective replay under constrained storage, recent approaches leverage distilled data to enhance the informativeness of memory. However, such approaches often involve significant computational overhead due to the use of bi-level optimization. Motivated by these limitations, we introduce Grid-based Patch Sampling (GPS), a lightweight and effective strategy for distilling informative memory samples without relying on a trainable model. GPS generates informative samples by sampling a subset of pixels from the original image, yielding compact low-resolution representations that preserve both semantic content and structural information. During replay, these representations are reassembled to support training and evaluation. Experiments on extensive benchmarks demonstrate that GRS can be seamlessly integrated into existing replay frameworks, leading to 3%-4% improvements in average end accuracy under memory-constrained settings, with limited computational overhead.
Ferret: An Efficient Online Continual Learning Framework under Varying Memory Constraints
Mar 15, 2025In the realm of high-frequency data streams, achieving real-time learning within varying memory constraints is paramount. This paper presents Ferret, a comprehensive framework designed to enhance online accuracy of Online Continual Learning (OCL) algorithms while dynamically adapting to varying memory budgets. Ferret employs a fine-grained pipeline parallelism strategy combined with an iterative gradient compensation algorithm, ensuring seamless handling of high-frequency data with minimal latency, and effectively counteracting the challenge of stale gradients in parallel training. To adapt to varying memory budgets, its automated model partitioning and pipeline planning optimizes performance regardless of memory limitations. Extensive experiments across 20 benchmarks and 5 integrated OCL algorithms show Ferret's remarkable efficiency, achieving up to 3.7$\times$ lower memory overhead to reach the same online accuracy compared to competing methods. Furthermore, Ferret consistently outperforms these methods across diverse memory budgets, underscoring its superior adaptability. These findings position Ferret as a premier solution for efficient and adaptive OCL framework in real-time environments.
Heart-Darts: Classification of Heartbeats Using Differentiable Architecture Search
May 03, 2021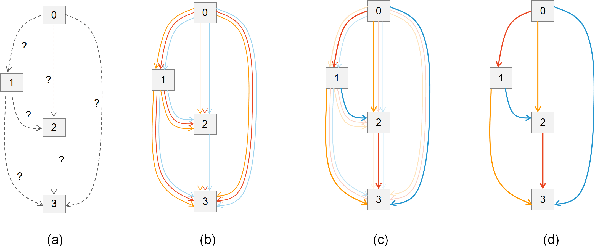
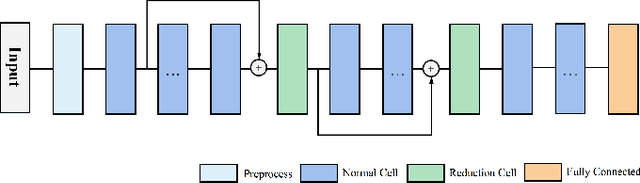
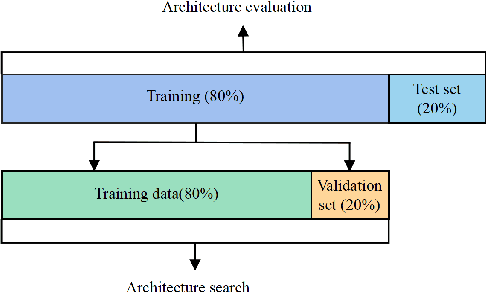
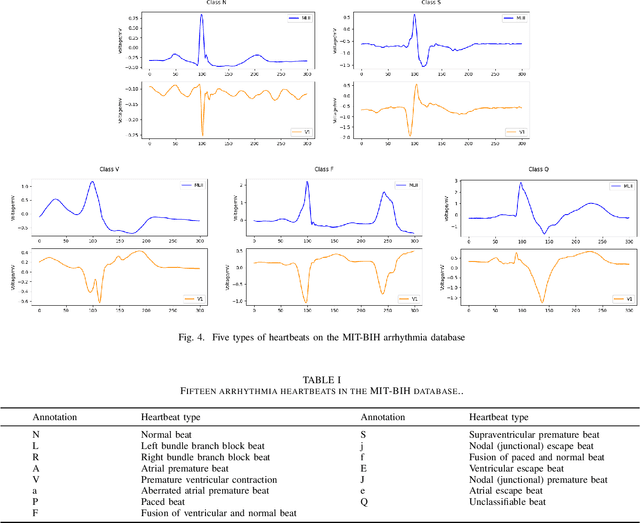
Arrhythmia is a cardiovascular disease that manifests irregular heartbeats. In arrhythmia detection, the electrocardiogram (ECG) signal is an important diagnostic technique. However, manually evaluating ECG signals is a complicated and time-consuming task. With the application of convolutional neural networks (CNNs), the evaluation process has been accelerated and the performance is improved. It is noteworthy that the performance of CNNs heavily depends on their architecture design, which is a complex process grounded on expert experience and trial-and-error. In this paper, we propose a novel approach, Heart-Darts, to efficiently classify the ECG signals by automatically designing the CNN model with the differentiable architecture search (i.e., Darts, a cell-based neural architecture search method). Specifically, we initially search a cell architecture by Darts and then customize a novel CNN model for ECG classification based on the obtained cells. To investigate the efficiency of the proposed method, we evaluate the constructed model on the MIT-BIH arrhythmia database. Additionally, the extensibility of the proposed CNN model is validated on two other new databases. Extensive experimental results demonstrate that the proposed method outperforms several state-of-the-art CNN models in ECG classification in terms of both performance and generalization capability.