 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-SCOPE: Fully Sparse Long-Range Cooperative 3D Perception
Apr 10, 2026Cooperative 3D perception via Vehicle-to-Everything communication is a promising paradigm for enhancing autonomous driving, offering extended sensing horizons and occlusion resolution. However, the practical deployment of existing methods is hindered at long distances by two critical bottlenecks: the quadratic computational scaling of dense BEV representations and the fragility of feature association mechanisms under significant observation and alignment errors. To overcome these limitations, we introduce Long-SCOPE, a fully sparse framework designed for robust long-distance cooperative 3D perception. Our method features two novel components: a Geometry-guided Query Generation module to accurately detect small, distant objects, and a learnable Context-Aware Association module that robustly matches cooperative queries despite severe positional noise. Experiments on the V2X-Seq and Griffin datasets validate that Long-SCOPE achieves state-of-the-art performance, particularly in challenging 100-150 m long-range settings, while maintaining highly competitive computation and communication costs.
Humanoid Occupancy: Enabling A Generalized Multimodal Occupancy Perception System on Humanoid Robots
Jul 27, 2025Humanoid robot technology is advancing rapidly, with manufacturers introducing diverse heterogeneous visual perception modules tailored to specific scenarios. Among various perception paradigms, occupancy-based representation has become widely recognized as particularly suitable for humanoid robots, as it provides both rich semantic and 3D geometric information essential for comprehensive environmental understanding. In this work, we present Humanoid Occupancy, a generalized multimodal occupancy perception system that integrates hardware and software components, data acquisition devices, and a dedicated annotation pipeline. Our framework employs advanced multi-modal fusion techniques to generate grid-based occupancy outputs encoding both occupancy status and semantic labels, thereby enabling holistic environmental understanding for downstream tasks such as task planning and navigation. To address the unique challenges of humanoid robots, we overcome issues such as kinematic interference and occlusion, and establish an effective sensor layout strategy. Furthermore, we have developed the first panoramic occupancy dataset specifically for humanoid robots, offering a valuable benchmark and resource for future research and development in this domain. The network architecture incorporates multi-modal feature fusion and temporal information integration to ensure robust perception. Overall, Humanoid Occupancy delivers effective environmental perception for humanoid robots and establishes a technical foundation for standardizing universal visual modules, paving the way for the widespread deployment of humanoid robots in complex real-world scenarios.
Griffin: Aerial-Ground Cooperative Detection and Tracking Dataset and Benchmark
Mar 10, 2025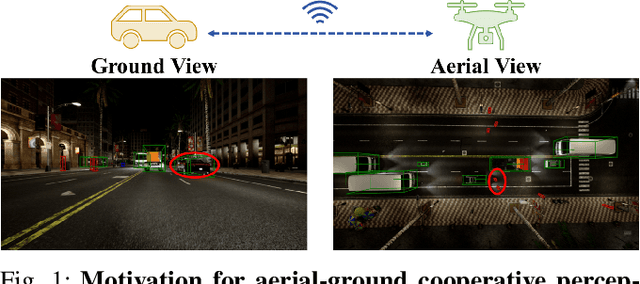

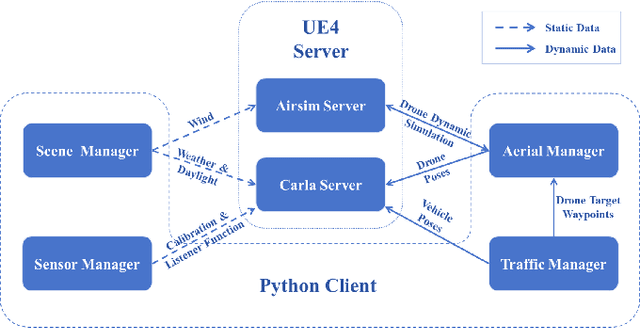

Despite significant advancements, autonomous driving systems continue to struggle with occluded objects and long-range detection due to the inherent limitations of single-perspective sensing. Aerial-ground cooperation offers a promising solution by integrating UAVs' aerial views with ground vehicles' local observations. However, progress in this emerging field has been hindered by the absence of public datasets and standardized evaluation benchmarks. To address this gap, this paper presents a comprehensive solution for aerial-ground cooperative 3D perception through three key contributions: (1) Griffin, a large-scale multi-modal dataset featuring over 200 dynamic scenes (30k+ frames) with varied UAV altitudes (20-60m), diverse weather conditions, and occlusion-aware 3D annotations, enhanced by CARLA-AirSim co-simulation for realistic UAV dynamics; (2) A unified benchmarking framework for aerial-ground cooperative detection and tracking tasks, including protocols for evaluating communication efficiency, latency tolerance, and altitude adaptability; (3) AGILE, an instance-level intermediate fusion baseline that dynamically aligns cross-view features through query-based interaction, achieving an advantageous balance between communication overhead and perception accuracy. Extensive experiments prove the effectiveness of aerial-ground cooperative perception and demonstrate the direction of further research. The dataset and codes are available at https://github.com/wang-jh18-SVM/Griffin.
Leveraging Temporal Contexts to Enhance Vehicle-Infrastructure Cooperative Perception
Aug 20, 2024Infrastructure sensors installed at elevated positions offer a broader perception range and encounter fewer occlusions. Integrating both infrastructure and ego-vehicle data through V2X communication, known as vehicle-infrastructure cooperation, has shown considerable advantages in enhancing perception capabilities and addressing corner cases encountered in single-vehicle autonomous driving. However, cooperative perception still faces numerous challenges, including limited communication bandwidth and practical communication interruptions. In this paper, we propose CTCE, a novel framework for cooperative 3D object detection. This framework transmits queries with temporal contexts enhancement, effectively balancing transmission efficiency and performance to accommodate real-world communication conditions. Additionally, we propose a temporal-guided fusion module to further improve performance. The roadside temporal enhancement and vehicle-side spatial-temporal fusion together constitute a multi-level temporal contexts integration mechanism, fully leveraging temporal information to enhance performance. Furthermore, a motion-aware reconstruction module is introduced to recover lost roadside queries due to communication interruptions. Experimental results on V2X-Seq and V2X-Sim datasets demonstrate that CTCE outperforms the baseline QUEST, achieving improvements of 3.8% and 1.3% in mAP, respectively. Experiments under communication interruption conditions validate CTCE's robustness to communication interruptions.
End-to-End Autonomous Driving through V2X Cooperation
Mar 31, 2024



Cooperatively utilizing both ego-vehicle and infrastructure sensor data via V2X communication has emerged as a promising approach for advanced autonomous driving. However, current research mainly focuses on improving individual modules, rather than taking end-to-end learning to optimize final planning performance, resulting in underutilized data potential. In this paper, we introduce UniV2X, a pioneering cooperative autonomous driving framework that seamlessly integrates all key driving modules across diverse views into a unified network. We propose a sparse-dense hybrid data transmission and fusion mechanism for effective vehicle-infrastructure cooperation, offering three advantages: 1) Effective for simultaneously enhancing agent perception, online mapping, and occupancy prediction, ultimately improving planning performance. 2) Transmission-friendly for practical and limited communication conditions. 3) Reliable data fusion with interpretability of this hybrid data. We implement UniV2X, as well as reproducing several benchmark methods, on the challenging DAIR-V2X, the real-world cooperative driving dataset. Experimental results demonstrate the effectiveness of UniV2X in significantly enhancing planning performance, as well as all intermediate output performance. Code is at https://github.com/AIR-THU/UniV2X.