 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUME: A Unified Meta-Generalization Framework for Cross-Domain ETA
May 31, 2026Accurate Estimated Time of Arrival (ETA) prediction on checkout page is crucial in instant logistics for enhancing user satisfaction, optimizing dispatching, and controlling operational costs. In international on-demand delivery platforms, where ETA data originates from diverse countries or regions with different patterns, multi-domain modeling is of great importance and has been widely adopted. However, existing methods still face three critical challenges in real-world deployment. First, current multi-domain models struggle to generalize to completely unseen domains, failing to achieve zero-shot prediction during the initial cold-start phase. Second, cross-domain feature spaces are often assumed to be consistent, whereas new domains commonly suffer from structural missingness of offline (statistical) features due to the lack of historical data. Third, such feature missingness often compels industrial systems to model mature and cold-start domains separately, hindering knowledge transfer and increasing maintenance overhead. To address these challenges, we propose \textbf{UME}, a \textbf{U}nified \textbf{M}eta-generalization framework for \textbf{E}TA. Specifically, UME integrates a unified dual-branch architecture with a novel meta-learning mechanism that employs a hypernetwork-based meta learner. By leveraging domain-level knowledge and instance-level context, the meta learner empowers three meta modules to dynamically modulate feature gating, expert attention, and final prediction, capturing cross-domain correlations and facilitating intra-domain adaptation. A knowledge distillation strategy is further introduce to enhance performance. UME has now been deployed in Meituan-keeta delivery platform (the largest international food delivery platform in China). Extensive offline experiments and online A/B tests demonstrate that UME significantly outperforms existing baselines.
SkillGenBench: Benchmarking Skill Generation Pipelines for LLM Agents
May 18, 2026As LLM agents are increasingly built around reusable skills, a central challenge is no longer only whether agents can use provided skills, but whether they can generate correct, reusable, and executable skills from repositories and documents. Existing benchmarks primarily evaluate the efficacy of given skills or the ability of agents to solve downstream tasks from raw context, but they do not isolate skill generation itself as the object of study. We introduce SkillGenBench, a benchmark for evaluating skill generation pipelines under a unified and controlled protocol. In SkillGenBench, a generator receives raw corpora and produces standardized skill artifacts, which are then executed under fixed harnesses and assessed with unified evaluation procedures. The benchmark covers two generation regimes: task-conditioned generation, where a task-specific skill is synthesized after the task is revealed, and task-agnostic generation, where a reusable skill library must be distilled before downstream tasks are known. It also spans two complementary procedural sources: repository-grounded instances, where procedures are distributed across code, configuration, and scripts, and document-grounded instances, where procedures and constraints must be distilled from long-form text. We provide standardized task specifications, pinned environments, and evaluation protocols centered on deterministic execution-based checks, supplemented by auxiliary signals for diagnosis. Experiments across a range of skill-generation methods and backbones show substantial performance variation, highlight the difficulty of reusable skill distillation, and reveal distinct failure modes in skill generation from software repositories versus long-form documents. SkillGenBench establishes a reproducible testbed for studying skill generation as an independent research problem in agent systems.
Rubrics to Tokens: Bridging Response-level Rubrics and Token-level Rewards in Instruction Following Tasks
Apr 03, 2026Rubric-based Reinforcement Learning (RL) has emerged as a promising approach for aligning Large Language Models (LLMs) with complex, open-domain instruction following tasks. However, existing methods predominantly rely on response-level rewards, introducing severe reward sparsity and reward ambiguity problems. To address these issues, we propose Rubrics to Tokens (RTT), a novel rubric-based RL framework that bridges coarse response-level scores and fine-grained token-level credit assignment. RTT introduces a Token-Level Relevance Discriminator to predict which tokens in the response are responsible for a specific constraint, and optimizes the policy model via RTT-GRPO, which integrates response-level and token-level advantages within a unified framework. Furthermore, when transitioning from one-dimensional, outcome-level reward to three-dimensional reward space in the token-level rubric-based RL, we propose a novel group normalization method, called Intra-sample Token Group Normalization, to accommodate this shift. Extensive experiments and benchmarks demonstrate that RTT consistently outperforms other baselines in both instruction- and rubric-level accuracy across different models.
Story2Proposal: A Scaffold for Structured Scientific Paper Writing
Mar 28, 2026Generating scientific manuscripts requires maintaining alignment between narrative reasoning, experimental evidence, and visual artifacts across the document lifecycle. Existing language-model generation pipelines rely on unconstrained text synthesis with validation applied only after generation, often producing structural drift, missing figures or tables, and cross-section inconsistencies. We introduce Story2Proposal, a contract-governed multi-agent framework that converts a research story into a structured manuscript through coordinated agents operating under a persistent shared visual contract. The system organizes architect, writer, refiner, and renderer agents around a contract state that tracks section structure and registered visual elements, while evaluation agents supply feedback in a generate evaluate adapt loop that updates the contract during generation. Experiments on tasks derived from the Jericho research corpus show that Story2Proposal achieved an expert evaluation score of 6.145 versus 3.963 for DirectChat (+2.182) across GPT, Claude, Gemini, and Qwen backbones. Compared with the structured generation baseline Fars, Story2Proposal obtained an average score of 5.705 versus 5.197, indicating improved structural consistency and visual alignment.
MimicDreamer: Aligning Human and Robot Demonstrations for Scalable VLA Training
Sep 26, 2025



Vision Language Action (VLA) models derive their generalization capability from diverse training data, yet collecting embodied robot interaction data remains prohibitively expensive. In contrast, human demonstration videos are far more scalable and cost-efficient to collect, and recent studies confirm their effectiveness in training VLA models. However, a significant domain gap persists between human videos and robot-executed videos, including unstable camera viewpoints, visual discrepancies between human hands and robotic arms, and differences in motion dynamics. To bridge this gap, we propose MimicDreamer, a framework that turns fast, low-cost human demonstrations into robot-usable supervision by jointly aligning vision, viewpoint, and actions to directly support policy training. For visual alignment, we propose H2R Aligner, a video diffusion model that generates high-fidelity robot demonstration videos by transferring motion from human manipulation footage. For viewpoint stabilization, EgoStabilizer is proposed, which canonicalizes egocentric videos via homography and inpaints occlusions and distortions caused by warping. For action alignment, we map human hand trajectories to the robot frame and apply a constrained inverse kinematics solver to produce feasible, low-jitter joint commands with accurate pose tracking. Empirically, VLA models trained purely on our synthesized human-to-robot videos achieve few-shot execution on real robots. Moreover, scaling training with human data significantly boosts performance compared to models trained solely on real robot data; our approach improves the average success rate by 14.7\% across six representative manipulation tasks.
LMQFormer: A Laplace-Prior-Guided Mask Query Transformer for Lightweight Snow Removal
Oct 12, 2022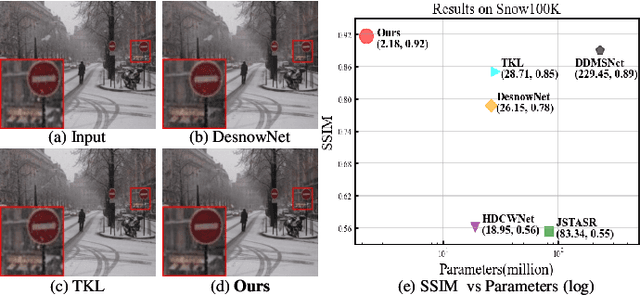



Snow removal aims to locate snow areas and recover clean images without repairing traces. Unlike the regularity and semitransparency of rain, snow with various patterns and degradations seriously occludes the background. As a result, the state-of-the-art snow removal methods usually retains a large parameter size. In this paper, we propose a lightweight but high-efficient snow removal network called Laplace Mask Query Transformer (LMQFormer). Firstly, we present a Laplace-VQVAE to generate a coarse mask as prior knowledge of snow. Instead of using the mask in dataset, we aim at reducing both the information entropy of snow and the computational cost of recovery. Secondly, we design a Mask Query Transformer (MQFormer) to remove snow with the coarse mask, where we use two parallel encoders and a hybrid decoder to learn extensive snow features under lightweight requirements. Thirdly, we develop a Duplicated Mask Query Attention (DMQA) that converts the coarse mask into a specific number of queries, which constraint the attention areas of MQFormer with reduced parameters. Experimental results in popular datasets have demonstrated the efficiency of our proposed model, which achieves the state-of-the-art snow removal quality with significantly reduced parameters and the lowest running time.