 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMMA: Generalizing Real-World Robot Manipulation via Generative Visual Transfer
Sep 26, 2025
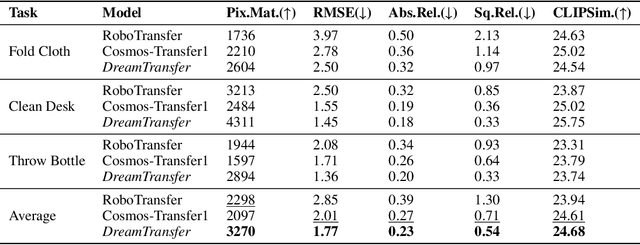
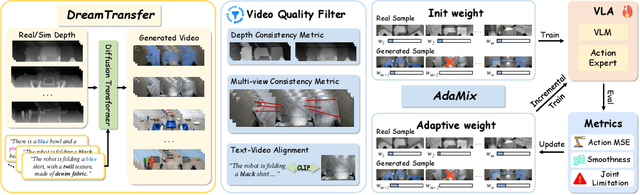
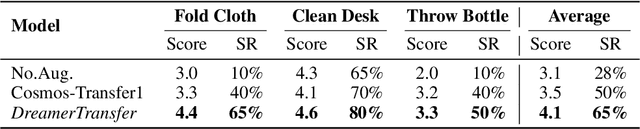
Vision-language-action (VLA) models increasingly rely on diverse training data to achieve robust generalization. However, collecting large-scale real-world robot manipulation data across varied object appearances and environmental conditions remains prohibitively time-consuming and expensive. To overcome this bottleneck, we propose Embodied Manipulation Media Adaptation (EMMA), a VLA policy enhancement framework that integrates a generative data engine with an effective training pipeline. We introduce DreamTransfer, a diffusion Transformer-based framework for generating multi-view consistent, geometrically grounded embodied manipulation videos. DreamTransfer enables text-controlled visual editing of robot videos, transforming foreground, background, and lighting conditions without compromising 3D structure or geometrical plausibility. Furthermore, we explore hybrid training with real and generated data, and introduce AdaMix, a hard-sample-aware training strategy that dynamically reweights training batches to focus optimization on perceptually or kinematically challenging samples. Extensive experiments show that videos generated by DreamTransfer significantly outperform prior video generation methods in multi-view consistency, geometric fidelity, and text-conditioning accuracy. Crucially, VLAs trained with generated data enable robots to generalize to unseen object categories and novel visual domains using only demonstrations from a single appearance. In real-world robotic manipulation tasks with zero-shot visual domains, our approach achieves over a 200% relative performance gain compared to training on real data alone, and further improves by 13% with AdaMix, demonstrating its effectiveness in boosting policy generalization.
MimicDreamer: Aligning Human and Robot Demonstrations for Scalable VLA Training
Sep 26, 2025



Vision Language Action (VLA) models derive their generalization capability from diverse training data, yet collecting embodied robot interaction data remains prohibitively expensive. In contrast, human demonstration videos are far more scalable and cost-efficient to collect, and recent studies confirm their effectiveness in training VLA models. However, a significant domain gap persists between human videos and robot-executed videos, including unstable camera viewpoints, visual discrepancies between human hands and robotic arms, and differences in motion dynamics. To bridge this gap, we propose MimicDreamer, a framework that turns fast, low-cost human demonstrations into robot-usable supervision by jointly aligning vision, viewpoint, and actions to directly support policy training. For visual alignment, we propose H2R Aligner, a video diffusion model that generates high-fidelity robot demonstration videos by transferring motion from human manipulation footage. For viewpoint stabilization, EgoStabilizer is proposed, which canonicalizes egocentric videos via homography and inpaints occlusions and distortions caused by warping. For action alignment, we map human hand trajectories to the robot frame and apply a constrained inverse kinematics solver to produce feasible, low-jitter joint commands with accurate pose tracking. Empirically, VLA models trained purely on our synthesized human-to-robot videos achieve few-shot execution on real robots. Moreover, scaling training with human data significantly boosts performance compared to models trained solely on real robot data; our approach improves the average success rate by 14.7\% across six representative manipulation tasks.
Motion-R1: Chain-of-Thought Reasoning and Reinforcement Learning for Human Motion Generation
Jun 12, 2025Recent advances in large language models, especially in natural language understanding and reasoning, have opened new possibilities for text-to-motion generation. Although existing approaches have made notable progress in semantic alignment and motion synthesis, they often rely on end-to-end mapping strategies that fail to capture deep linguistic structures and logical reasoning. Consequently, generated motions tend to lack controllability, consistency, and diversity. To address these limitations, we propose Motion-R1, a unified motion-language modeling framework that integrates a Chain-of-Thought mechanism. By explicitly decomposing complex textual instructions into logically structured action paths, Motion-R1 provides high-level semantic guidance for motion generation, significantly enhancing the model's ability to interpret and execute multi-step, long-horizon, and compositionally rich commands. To train our model, we adopt Group Relative Policy Optimization, a reinforcement learning algorithm designed for large models, which leverages motion quality feedback to optimize reasoning chains and motion synthesis jointly. Extensive experiments across multiple benchmark datasets demonstrate that Motion-R1 achieves competitive or superior performance compared to state-of-the-art methods, particularly in scenarios requiring nuanced semantic understanding and long-term temporal coherence. The code, model and data will be publicly available.
HumanDreamer-X: Photorealistic Single-image Human Avatars Reconstruction via Gaussian Restoration
Apr 04, 2025



Single-image human reconstruction is vital for digital human modeling applications but remains an extremely challenging task. Current approaches rely on generative models to synthesize multi-view images for subsequent 3D reconstruction and animation. However, directly generating multiple views from a single human image suffers from geometric inconsistencies, resulting in issues like fragmented or blurred limbs in the reconstructed models. To tackle these limitations, we introduce \textbf{HumanDreamer-X}, a novel framework that integrates multi-view human generation and reconstruction into a unified pipeline, which significantly enhances the geometric consistency and visual fidelity of the reconstructed 3D models. In this framework, 3D Gaussian Splatting serves as an explicit 3D representation to provide initial geometry and appearance priority. Building upon this foundation, \textbf{HumanFixer} is trained to restore 3DGS renderings, which guarantee photorealistic results. Furthermore, we delve into the inherent challenges associated with attention mechanisms in multi-view human generation, and propose an attention modulation strategy that effectively enhances geometric details identity consistency across multi-view. Experimental results demonstrate that our approach markedly improves generation and reconstruction PSNR quality metrics by 16.45% and 12.65%, respectively, achieving a PSNR of up to 25.62 dB, while also showing generalization capabilities on in-the-wild data and applicability to various human reconstruction backbone models.