 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCFD-copilot: leveraging domain-adapted large language model and model context protocol to enhance simulation automation
Dec 08, 2025



Configuring computational fluid dynamics (CFD) simulations requires significant expertise in physics modeling and numerical methods, posing a barrier to non-specialists. Although automating scientific tasks with large language models (LLMs) has attracted attention, applying them to the complete, end-to-end CFD workflow remains a challenge due to its stringent domain-specific requirements. We introduce CFD-copilot, a domain-specialized LLM framework designed to facilitate natural language-driven CFD simulation from setup to post-processing. The framework employs a fine-tuned LLM to directly translate user descriptions into executable CFD setups. A multi-agent system integrates the LLM with simulation execution, automatic error correction, and result analysis. For post-processing, the framework utilizes the model context protocol (MCP), an open standard that decouples LLM reasoning from external tool execution. This modular design allows the LLM to interact with numerous specialized post-processing functions through a unified and scalable interface, improving the automation of data extraction and analysis. The framework was evaluated on benchmarks including the NACA~0012 airfoil and the three-element 30P-30N airfoil. The results indicate that domain-specific adaptation and the incorporation of the MCP jointly enhance the reliability and efficiency of LLM-driven engineering workflows.
EMMA: Generalizing Real-World Robot Manipulation via Generative Visual Transfer
Sep 26, 2025
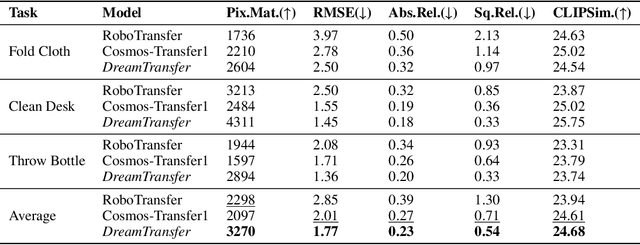
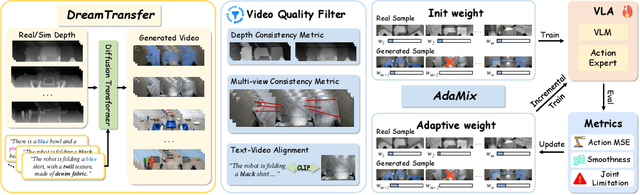
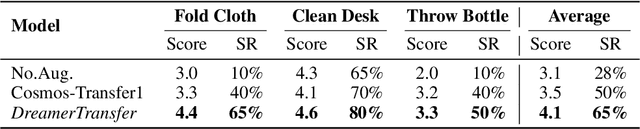
Vision-language-action (VLA) models increasingly rely on diverse training data to achieve robust generalization. However, collecting large-scale real-world robot manipulation data across varied object appearances and environmental conditions remains prohibitively time-consuming and expensive. To overcome this bottleneck, we propose Embodied Manipulation Media Adaptation (EMMA), a VLA policy enhancement framework that integrates a generative data engine with an effective training pipeline. We introduce DreamTransfer, a diffusion Transformer-based framework for generating multi-view consistent, geometrically grounded embodied manipulation videos. DreamTransfer enables text-controlled visual editing of robot videos, transforming foreground, background, and lighting conditions without compromising 3D structure or geometrical plausibility. Furthermore, we explore hybrid training with real and generated data, and introduce AdaMix, a hard-sample-aware training strategy that dynamically reweights training batches to focus optimization on perceptually or kinematically challenging samples. Extensive experiments show that videos generated by DreamTransfer significantly outperform prior video generation methods in multi-view consistency, geometric fidelity, and text-conditioning accuracy. Crucially, VLAs trained with generated data enable robots to generalize to unseen object categories and novel visual domains using only demonstrations from a single appearance. In real-world robotic manipulation tasks with zero-shot visual domains, our approach achieves over a 200% relative performance gain compared to training on real data alone, and further improves by 13% with AdaMix, demonstrating its effectiveness in boosting policy generalization.
Fine-tuning a Large Language Model for Automating Computational Fluid Dynamics Simulations
Apr 21, 2025



Configuring computational fluid dynamics (CFD) simulations typically demands extensive domain expertise, limiting broader access. Although large language models (LLMs) have advanced scientific computing, their use in automating CFD workflows is underdeveloped. We introduce a novel approach centered on domain-specific LLM adaptation. By fine-tuning Qwen2.5-7B-Instruct on NL2FOAM, our custom dataset of 28716 natural language-to-OpenFOAM configuration pairs with chain-of-thought (CoT) annotations, we enable direct translation from natural language descriptions to executable CFD setups. A multi-agent framework orchestrates the process, autonomously verifying inputs, generating configurations, running simulations, and correcting errors. Evaluation on a benchmark of 21 diverse flow cases demonstrates state-of-the-art performance, achieving 88.7% solution accuracy and 82.6% first-attempt success rate. This significantly outperforms larger general-purpose models like Qwen2.5-72B-Instruct, DeepSeek-R1, and Llama3.3-70B-Instruct, while also requiring fewer correction iterations and maintaining high computational efficiency. The results highlight the critical role of domain-specific adaptation in deploying LLM assistants for complex engineering workflows. Our code and fine-tuned model have been deposited at https://github.com/YYgroup/AutoCFD.
Fine-tuning an Large Language Model for Automating Computational Fluid Dynamics Simulations
Apr 13, 2025Configuring computational fluid dynamics (CFD) simulations typically demands extensive domain expertise, limiting broader access. Although large language models (LLMs) have advanced scientific computing, their use in automating CFD workflows is underdeveloped. We introduce a novel approach centered on domain-specific LLM adaptation. By fine-tuning Qwen2.5-7B-Instruct on NL2FOAM, our custom dataset of 28716 natural language-to-OpenFOAM configuration pairs with chain-of-thought (CoT) annotations, we enable direct translation from natural language descriptions to executable CFD setups. A multi-agent framework orchestrates the process, autonomously verifying inputs, generating configurations, running simulations, and correcting errors. Evaluation on a benchmark of 21 diverse flow cases demonstrates state-of-the-art performance, achieving 88.7% solution accuracy and 82.6% first-attempt success rate. This significantly outperforms larger general-purpose models like Qwen2.5-72B-Instruct, DeepSeek-R1, and Llama3.3-70B-Instruct, while also requiring fewer correction iterations and maintaining high computational efficiency. The results highlight the critical role of domain-specific adaptation in deploying LLM assistants for complex engineering workflows.